Hadoop高可用集群
1.简介
若HDFS集群中只配置了一个NameNode,那么当该NameNode所在的节点宕机,则整个HDFS就不能进行文件的上传和下载。
若YARN集群中只配置了一个ResourceManager,那么当该ResourceManager所在的节点宕机,则整个YARN就不能进行任务的计算。
*Hadoop依赖Zookeeper进行各个模块的HA配置,其中状态为Active的节点对外提供服务,而状态为StandBy的节点则只负责数据的同步,在必要时提供快速故障转移。
Hadoop各个模块剖析:https://www.cnblogs.com/funyoung/p/9889719.html
Hadoop集群管理:https://www.cnblogs.com/funyoung/p/9920828.html
2.HDFS HA集群
2.1 模型
当有两个NameNode时,提供哪个NameNode地址给客户端?
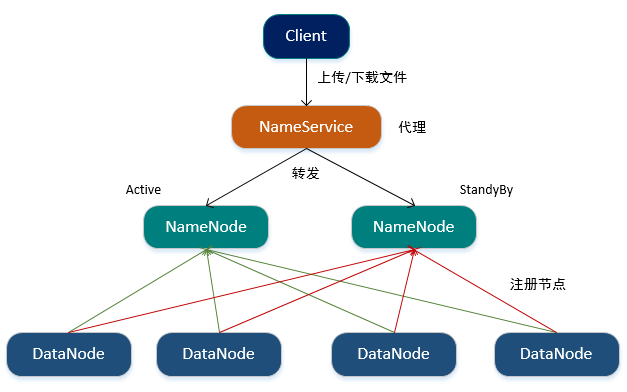
1.Hadoop提供了NameService进程,其是NameNode的代理,维护NameNode列表并存储NameNode的状态,客户端直接访问的是NameService,NameService会将请求转发给当前状态为Active的NameNode。
2.当启动HDFS时,DataNode将同时向两个NameNode进行注册。
怎样发现NameNode无法提供服务以及如何进行NameNode间状态的切换?
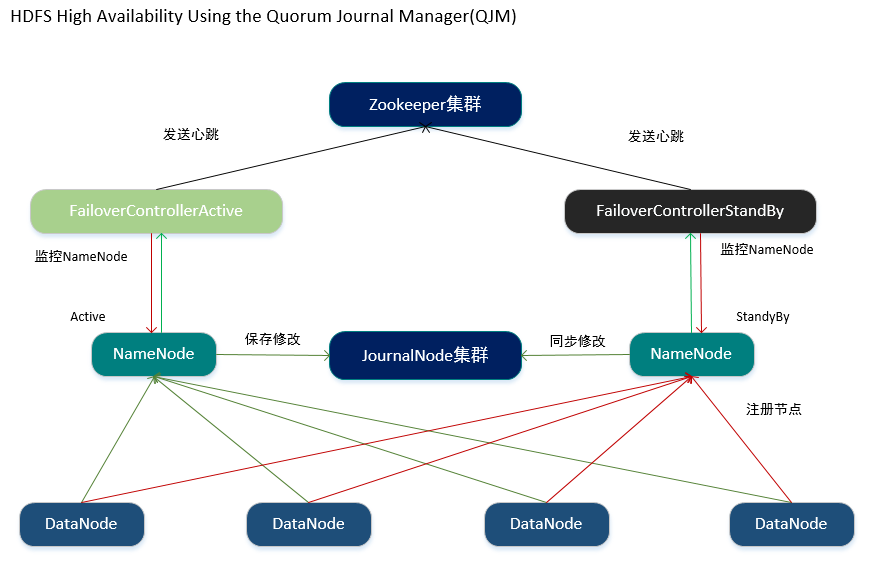
1.Hadoop提供了FailoverControllerActive和FailoverControllerStandBy两个进程用于NameNode的生命监控。
2.FailoverControllerActive和FailoverControllerStandBy会分别监控对应状态的NameNode,若NameNode无异常则定期向Zookeeper集群发送心跳,若在一定时间内Zookeeper集群没收到FailoverControllerActive发送的心跳,则认为此时状态为Active的NameNode已经无法对外提供服务,因此将状态为StandBy的NameNode切换为Active状态。
NameNode之间的数据如何进行同步和共享?
1.Hadoop提供了JournalNode用于存放NameNode中的编辑日志。
2.当激活的NameNode执行任何名称空间上的修改时,它将修改的记录保存到JournalNode集群中,备用的NameNode能够实时监控JournalNode集群中日志的变化,当监控到日志发生改变时会将其同步到本地。
*当状态为Active的NameNode无法对外提供服务时,Zookeeper将会自动的将处于StandBy状态的NameNode切换成Active。
2.2 HDFS HA高可用集群搭建
1.安装并配置Zookeeper集群
https://www.cnblogs.com/funyoung/p/8778106.html
2.配置HDFS(hdfs-site.xml)
<configuration>
<!-- 指定NameService的名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定NameService下两个NameNode的名称 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 分别指定NameNode的RPC通讯地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>192.168.1.80:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>192.168.1.81:8020</value>
</property>
<!-- 分别指定NameNode的Web监控页面地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>192.168.1.80:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>192.168.1.81:50070</value>
</property>
<!-- 指定NameNode编辑日志存储在JournalNode集群中的目录-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.1.80:8485;192.168.1.81:8485;192.168.1.82:8485/mycluster</value>
</property>
<!-- 指定JournalNode集群存放日志的目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop/hadoop-2.9.0/journalnode</value>
</property>
<!-- 配置NameNode失败自动切换的方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 由于使用SSH,那么需要指定密钥的位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启失败故障自动转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置Zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.1.80:2181,192.168.1.81:2181,192.168.1.82:2181</value>
</property>
<!-- 文件在HDFS中的备份数(小于等于NameNode) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭HDFS的访问权限 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 指定一个配置文件,使NameNode过滤配置文件中指定的host -->
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/hdfs.exclude</value>
</property>
</configuration>
*指定NameNode的RPC通讯地址是为了接收FailoverControllerActive和FailoverControllerStandBy以及DataNode发送的心跳。
3.配置Hadoop公共属性(core-site.xml)
<configuration>
<!-- Hadoop工作目录,用于存放Hadoop运行时NameNode、DataNode产生的数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.9.0/data</value>
</property>
<!-- 默认NameNode,使用NameService的名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 开启Hadoop的回收站机制,当删除HDFS中的文件时,文件将会被移动到回收站(/usr/<username>/.Trash),在指定的时间过后再对其进行删除,此机制可以防止文件被误删除 -->
<property>
<name>fs.trash.interval</name>
<!-- 单位是分钟 -->
<value>1440</value>
</property>
</configuration>
*在HDFS HA集群中,StandBy的NameNode会对namespace进行checkpoint操作,因此就不需要在HA集群中运行SecondaryNameNode、CheckpintNode、BackupNode。
4.启动HDFS HA高可用集群
1.分别启动JournalNode



2.格式化第一个NameNode并启动


3.第二个NameNode同步第一个NameNode的信息

4.启动第二个NameNode

5.启动Zookeeper集群
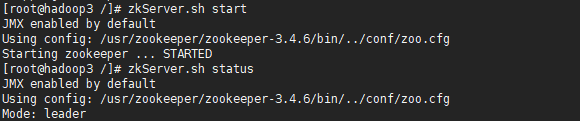
6.格式化Zookeeper

*当格式化ZK后,ZK中将会多了hadoop-ha节点。
7.重启HDFS集群

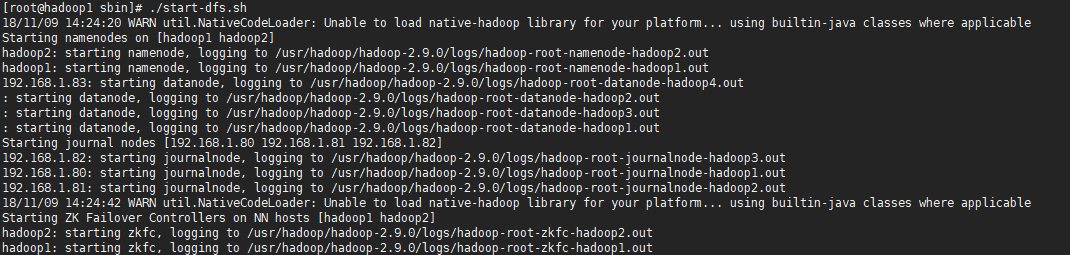
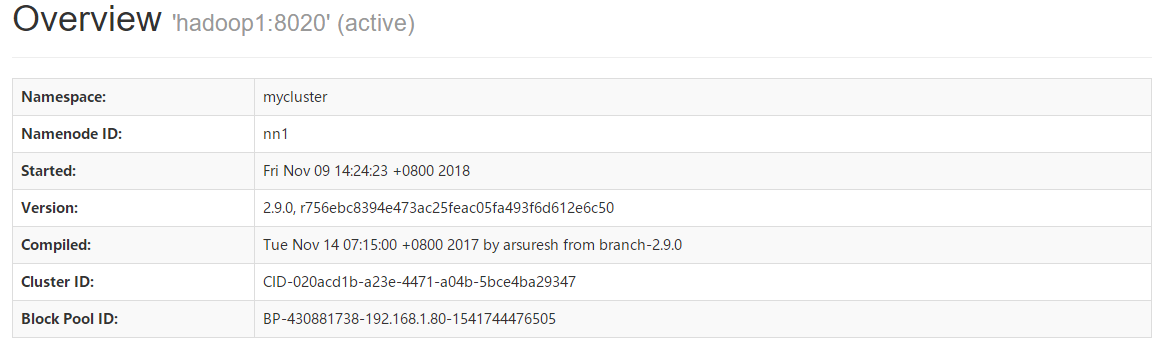
当HDFS HA集群启动完毕后,可以分别访问NameNode管理页面查看当前NameNode的状态,http://192.168.1.80:50070、http://192.168.1.81:50070。
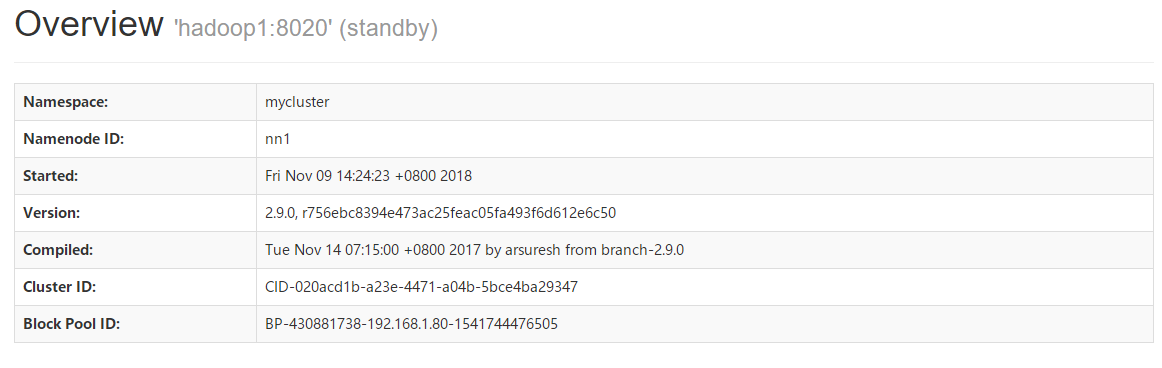
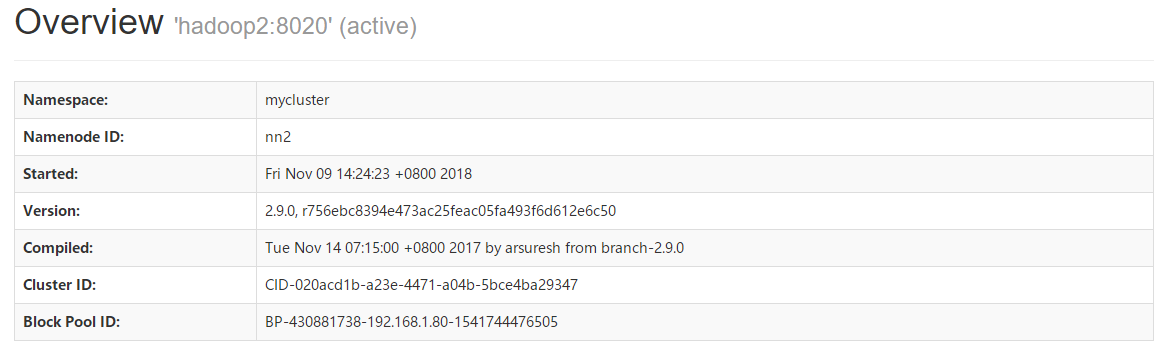
*可以查看到主机名为hadoop1的NamNode其状态为StandBy,而主机名为hadoop2的NameNode其状态为Active。
8.模拟NameNode宕机,手动杀死进程。

此时访问NameNode管理页面,可见主机名为hadoop1的NameNode其状态从原本的StandBy切换成Active。
2.3 JAVA操作HDFS HA集群
*由于在HDFS HA集群中存在两个NameNode,且服务端暴露的是NameService,因此在通过JAVA连接HDFS HA集群时需要使用Configuration实例进行相关的配置。
/**
* @Auther: ZHUANGHAOTANG
* @Date: 2018/11/6 11:49
* @Description:
*/
public class HDFSUtils { private static Logger logger = LoggerFactory.getLogger(HDFSUtils.class); /**
* NameNode Service
*/
private static final String NAMESERVER_URL = "hdfs://mycluster:8020"; /**
* NameNode服务列表
*/
private static final String[] NAMENODE_URLS = {"192.168.1.80:8020", "192.168.1.81:8020"}; /**
* HDFS文件系统连接对象
*/
private static FileSystem fs = null; static {
Configuration conf = new Configuration();
//指定默认连接的NameNode,使用NameService的地址
conf.set("fs.defaultFS", NAMESERVER_URL);
//指定NameService的名称
conf.set("dfs.nameservices", "mycluster");
//指定NameService下的NameNode列表
conf.set("dfs.ha.namenodes.mycluster", "nn1,nn2");
//分别指定NameNode的RPC通讯地址
conf.set("dfs.namenode.rpc-address.mycluster.nn1", NAMENODE_URLS[0]);
conf.set("dfs.namenode.rpc-address.mycluster.nn2", NAMENODE_URLS[1]);
//配置NameNode失败自动切换的方式
conf.set("dfs.client.failover.proxy.provider.mycluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
try {
fs = FileSystem.get(URI.create(NAMESERVER_URL), conf);
} catch (IOException e) {
logger.info("初始化HDFS连接失败:{}", e);
}
} /**
* 创建目录
*/
public static void mkdir(String dir) throws Exception {
dir = NAMESERVER_URL + dir;
if (!fs.exists(new Path(dir))) {
fs.mkdirs(new Path(dir));
}
} /**
* 删除目录或文件
*/
public static void delete(String dir) throws Exception {
dir = NAMESERVER_URL + dir;
fs.delete(new Path(dir), true);
} /**
* 遍历指定路径下的目录和文件
*/
public static List<String> listAll(String dir) throws Exception {
List<String> names = new ArrayList<>();
dir = NAMESERVER_URL + dir;
FileStatus[] files = fs.listStatus(new Path(dir));
for (FileStatus file : files) {
if (file.isFile()) { //文件
names.add(file.getPath().toString());
} else if (file.isDirectory()) { //目录
names.add(file.getPath().toString());
} else if (file.isSymlink()) { //软或硬链接
names.add(file.getPath().toString());
}
}
return names;
} /**
* 上传当前服务器的文件到HDFS中
*/
public static void uploadLocalFileToHDFS(String localFile, String hdfsFile) throws Exception {
hdfsFile = NAMESERVER_URL + hdfsFile;
Path src = new Path(localFile);
Path dst = new Path(hdfsFile);
fs.copyFromLocalFile(src, dst);
} /**
* 通过流上传文件
*/
public static void uploadFile(String hdfsPath, InputStream inputStream) throws Exception {
hdfsPath = NAMESERVER_URL + hdfsPath;
FSDataOutputStream os = fs.create(new Path(hdfsPath));
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
byte[] data = new byte[1024];
int len;
while ((len = bufferedInputStream.read(data)) != -1) {
if (len == data.length) {
os.write(data);
} else { //最后一次读取
byte[] lastData = new byte[len];
System.arraycopy(data, 0, lastData, 0, len);
os.write(lastData);
}
}
inputStream.close();
bufferedInputStream.close();
os.close();
} /**
* 从HDFS中下载文件
*/
public static byte[] readFile(String hdfsFile) throws Exception {
hdfsFile = NAMESERVER_URL + hdfsFile;
Path path = new Path(hdfsFile);
if (fs.exists(path)) {
FSDataInputStream is = fs.open(path);
FileStatus stat = fs.getFileStatus(path);
byte[] data = new byte[(int) stat.getLen()];
is.readFully(0, data);
is.close();
return data;
} else {
throw new Exception("File Not Found In HDFS");
}
} }
3.YARN HA集群
3.1 模型
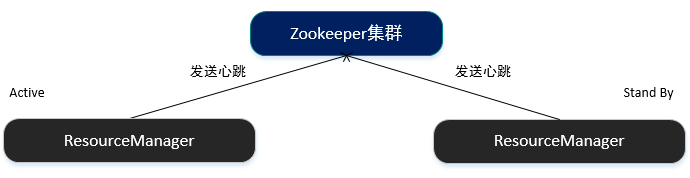
*启动两个ResourceManager后分别向Zookeeper注册,通过Zookeeper管理他们的状态,一旦状态为Active的ResourceManager无法正常提供服务,Zookeeper将会立即将状态为StandBy的ResourceManager切换为Active。
3.2 YARN HA高可用集群搭建
1.配置YARN(yarn-site.xml)
<configuration>
<!-- 配置Reduce取数据的方式是shuffle(随机) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志的删除时间 -1:禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation。retain-seconds</name>
<value>864000</value>
</property>
<!-- 设置yarn的内存大小,单位是MB -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<!-- 设置yarn的CPU核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
<!-- YARN HA配置 -->
<!-- 开启yarn ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定yarn ha的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!-- 分别指定两个ResourceManager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定两个ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>192.168.1.80</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>192.168.1.81</value>
</property>
<!-- 分别指定两个ResourceManager的Web访问地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>192.168.1.80:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>192.168.1.81:8088</value>
</property>
<!-- 配置使用的Zookeeper集群 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>192.168.1.80:2181,192.168.1.81:2181,192.168.1.82:2181</value>
</property>
<!-- ResourceManager Restart配置 -->
<!-- 启用ResourceManager的restart功能,当ResourceManager重启时将会保存运行时信息到指定的位置,重启成功后再进行读取 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- ResourceManager Restart使用的存储方式(实现类) -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- ResourceManager重启时数据保存在Zookeeper中的目录 -->
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<!-- NodeManager Restart配置 -->
<!-- 启用NodeManager的restart功能,当NodeManager重启时将会保存运行时信息到指定的位置,重启成功后再进行读取 -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- NodeManager重启时数据保存在本地的目录 -->
<property>
<name>yarn.nodemanager.recovery.dir</name>
<value>/usr/hadoop/hadoop-2.9.0/data/rsnodemanager</value>
</property>
<!-- 配置NodeManager的RPC通讯端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
</configuration>
ResourceManager Restart使用的存储方式(实现类)
1.ResourceManager运行时的数据保存在ZK中:org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
2.ResourceManager运行时的数据保存在HDFS中:org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
3.ResourceManager运行时的数据保存在本地:org.apache.hadoop.yarn.server.resourcemanager.recovery.LeveldbRMStateStore
*使用不同的存储方式将需要额外的配置项,可参考官网,http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerRestart.html
2.启动YARN HA高可用集群
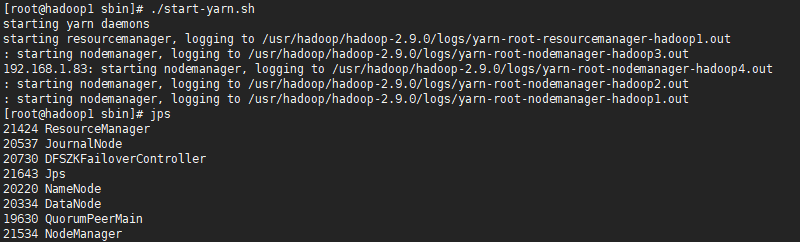
1.在ResourceManager所在节点中启动YARN集群
2.手动启动另一个ResourceManager
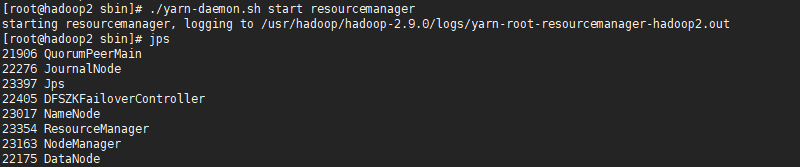
*当启动YARN HA集群后,可以分别访问ResourceManager管理页面,http://192.168.1.80:8088、http://192.168.1.81:8088。
访问状态为StandBy的ResourceManager时,会将请求重定向到状态为Active的ResourceManager的管理页面。
3.模拟ResourceManager宕机,手动杀死进程

*Zookeeper在一定时间内无法接收到状态为Active的ResourceManager发送的心跳时,将会立即将状态为StandBy的ResourceManager切换为Active。
Hadoop高可用集群的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- 【Hadoop】2、Hadoop高可用集群部署
1.服务器设置 集群规划 Namenode-Hadoop管理节点 10.25.24.92 10.25.24.93 Datanode-Hadoop数据存储节点 10.25.24.89 10.25.24. ...
- 大数据高可用集群环境安装与配置(06)——安装Hadoop高可用集群
下载Hadoop安装包 登录 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 镜像站,找到我们要安装的版本,点击进去复制下载链接 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
随机推荐
- ORA-04030: out of process memory when trying to allocate 152 bytes (Logminer LCR c,krvtadc)
今天使用LogMiner找回误更新的数据时,查询v$logmnr_contents时,遇到了"ORA-04030: out of process memory when trying to ...
- Python基础之注释,算数运算符,变量,输入和格式化输出
Python的注释 注释的作用:用自己熟悉的语言,对某些代码进行标注说明,增强程序的可读性: 在python解释器解释代码的过程中,凡是#右边的,解释器都直接跳过这一行: 注释的分类 单行注释 # 这 ...
- python学习_1
1.python2和python3 从宏观上讲,python2源码不标准.混乱.重复,和龟叔的理念背道而驰. 在python3上,实现了源码的统一化和标准化,去除了重复的代码. 2.编译型语言和解释型 ...
- Springboot添加filter方法
在springboot添加filter有两种方式: (1).通过创建FilterRegistrationBean的方式(建议使用此种方式,统一管理,且通过注解的方式若不是本地调试,如果在filter中 ...
- scala的多种集合的使用(1)之集合层级结构与分类
一.在使用scala集合时有几个概念必须知道: 1.谓词是什么? 谓词就是一个方法,一个函数或者一个匿名函数,接受一个或多个函数,返回一个Boolean值. 例如:下面方法返回true或者false, ...
- centos 6.8 配置 Redis3.2.5
配置Redis3.2.5 与 php-redis 一.配置Redis 1.下载Redis3.2.5安装包 [root@zhangsan /] wget http://download.redis.io ...
- MySQL 的数据目录
MySQL里面有4个数据库是属于MySQL自带的系统数据库: mysql 这个数据库贼核心,它存储了MySQL的用户账户和权限信息,一些存储过程.事件的定义信息,一些运行过程中产生的日志信息,一些帮助 ...
- LODOP不同电脑打印效果不同排查
1.位置不同,偏移问题.详细的相关偏移问题的博文:LODOP不同打印机出现偏移问题 2.样式问题. 本机浏览器解析样式不同 ,相关超文本样式博文:Lodop打印控件传入css样式.看是否传入正确样式 ...
- spring整合junit进行测试
以下只是一个模板,大家记得改变配置文件 package cn.itcast.crm.dao; import org.junit.Test; import org.junit.runner.RunWit ...
- python 学习二
什么是JSON,JSON 是一种轻量级的数据格式,其实就是字符串 把字符串转换为字典用 json.loads() import jsons = '{"aa":1,"bb& ...