Redux原理(一):Store实现分析
写在前面
写React也有段时间了,一直也是用Redux管理数据流,最近正好有时间分析下源码,一方面希望对Redux有一些理论上的认识;另一方面也学习下框架编程的思维方式。
Redux如何管理state
注册store tree
1、Redux通过全局唯一的store对象管理项目中的state
var store = createStore(reducer,initialState);
2、可以通过store注册listener,注册的listener会在store tree每次变更后执行
store.subscribe(function () {
console.log("state change");
});
如何更新store tree
1、store调用dispatch,通过action把变更的信息传递给reducer
var action = { type: 'add'};
store.dispatch(action);
2、store根据action携带type在reducer中查询变更具体要执行的方法,执行后返回新的state
export default (state = initialState, action)=>{
switch (action.type) {
case 'add':
return {
count:state.count + 1
}
break;
default:
break;
}
}
3、reducer执行后返回的新状态会更新到store tree中,触发由store.subscribe()注册的所有listener
Store实现
主要方法:
- createStore
- combineReducers
- bindActionCreators
- applyMiddleWare
- compose
createStore源码分析
查看完整createStore请戳这里
createStore方法用来注册一个store,返回值为包含了若干方法的对象,方法体如下:
export var ActionTypes = {
INIT: '@@redux/INIT'
}
export default function createStore(){
function getState(){}
function dispatch(){}
function subscribe(){}
function replaceReducer(){}
dispatch({ type: ActionTypes.INIT })
return {
dispatch,
subscribe,
getState,
replaceReducer
}
}
下面逐个代码段分析功能
createStore完整函数声明如下:
createStore(
reducer:(state, action)=>nextState,
preloadedState:any,
enhancer:(store)=>nextStore
)=>{
getState:()=>any,
subscribe:(listener:()=>any)=>any,
dispatch:(action:{type:""})=>{type:""},
replaceReducer:(nextReducer:(state, action)=>nextState)=>void
}
可以看出整个函数是一个闭包结构。参数有三个,返回值公开出若干方法
- dispatch:分发action
- subscribe:注册listener,监听state变化
- getState:读取store tree中所有state
- replaceReucer:替换reducer,改变state更新逻辑
当然,createStore内部处理了其重载形式,即:可以不传preloadedState
createStore(
reducer:(state, action)=>nextState,
enhancer:(store)=>nextStore
)
参数:
- reducer: reducer必须是一个function类型,此方法根据action.type更新state
- preloadedState: store tree初始值
- enhancer: enhancer通过添加middleware,增强store功能
前置操作

进入createSore首先执行如下操作:
- [40-43] 用于支持两种参数列表形式
createStore(reducer,preloadedState,enhancer)和createStore(reducer,enhancer) - [45-48][53-55] 校验reducer和enhancer的类型(必须为function)
重点分析下50行:
return enhancer(createStore)(reducer, preloadedState)
本语句执行了外部传入的enhancer,接收旧createStore,返回一个新createStore并执行,此过程形成一次递归;
那么递归什么时候停止呢?
可以看到,新createStore执行时,仅有reducer和preloadedState两个参数,再次运行到45行时,不会进入if条件 故不会再形成第二次递归,此时递归停止;
理论上,createStore仅被增强了一次,那如果希望对其进行多次增强该怎么办呢?
Redux提供了compose和applyMiddleWare方法,用来在Store上注册中间件,由此来实现多次增强。
getState()
getState方法比较简单,直接返回当前store tree状态
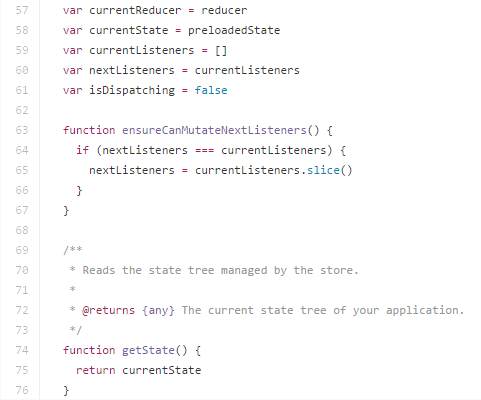
- [57-61] 定义了createStore内部要用到的全局变量。其中
currentReducer、currentState声明当前reducer方法集合和store tree状态,初始值为外部传入的createStore参数,currentListeners和nextListeners定义了存放store变化时要执行响应函数的数组集合
subscribe()
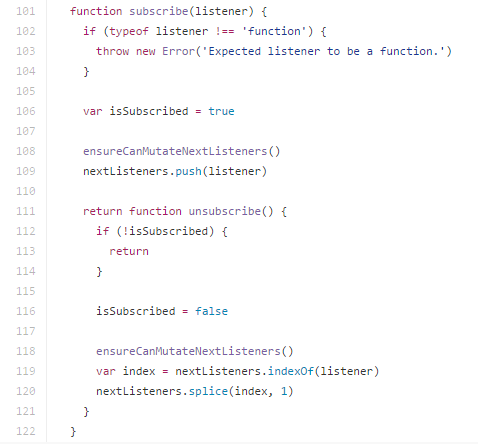
Redux采用了观察者模式,store内部维护listener数组,用于存储所有通过store.subscrib注册的listener,store.subscrib返回unsubscrib方法,用于注销当前listener;当store tree更新后,依次执行数组中的listener
具体代码如下:
dispatch()
dispatch方法主要完成两件事:
1、根据action查询reducer中变更state的方法,更新store tree
2、变更store tree后,依次执行listener中所有响应函数

- [168-173] 通过currentReducer和action,更新当前的store tree
- [175-181] 当state tree变更后,依次执行所有注册的listener
有个问题需要注意:
方法中使用了全局定义的isDispatching用于给变更中的store tree加锁;即:只有当本次store tree变更完毕后,才允许执行下一次变更,避免store tree响应多个变更时,结果不同步的问题;但事实上,这种写法也决定了,目前的store tree只能响应同步变更(异步变更需要通过添加中间件实现)
replaceReducer()
replaceReducer用于替换操作store tree中state的方式

整个方法代码量不多,从外部接收新的reducer方法后,替换掉内部旧的ruducer。
需要注意一下199行的dispatch方法,这一行主动触发了一次变更。由于每次dispatch执行后,redux都会执行reducer或子reducer方法(如果使用了combineReducers),所以这一行的作用就是在初始化store tree中所有的state节点。
小结
以上就是整个createStore方法的主要实现过程,其中dispatch方法为控制整个store tree变更的核心方法。触发store tree变更的方式只有一个,就是dispatch一个action
combineReducers源码分析
为什么需要combineReducers
结合上面store tree变更的过程,我们可以看到,真正导致变更的核心代码就是:
currentState = currentReducer(currentState, action)
试想,若整个项目只通过一个reducer方法维护整个store tree,随着项目功能和复杂度的增加,我们需要维护的store tree层级也会越来越深,当我们需要变更一个处于store tree底层的state,reducer中的变更逻辑会十分复杂且臃肿。
而combineReducers存在的目的就是解决了整个store tree中state与reducer一对一设置的问题。我们可以根据项目的需要,定义多个子reducer方法,每个子reducer仅维护整个store tree中的一部分state, 通过combineReducers将子reducer合并为一层。这样我们就可以根据实际需要,将整个store tree拆分成更细小的部分,分开维护。
代码实现
combineReducers完整代码请戳这里
整个函数体结构如下:
combineReducers(
reducers:Object
)=> reducer(
state:any,
action:{type:""}
)
参数reducers是一个Object对象,其中包含所有待合并的子reducer方法
返回值是合并后的reducer方法,在执行此方法时,会在已合并的所有子reducer中查询要执行的reducer,并执行,变更其对应的state片段。
下面逐个代码段分析具体实现:

以上这部分主要用于规范化存储子ruducer的reducers对象
- [103-115] 过滤掉reducers对象中所有非function类型的reducer,合法的结果保存在
finalReducers对象中 - [116-127] 通过
assertReducerSanity方法校验所有子reducer的初始值和执行后结果是否为空,是则提示错误。
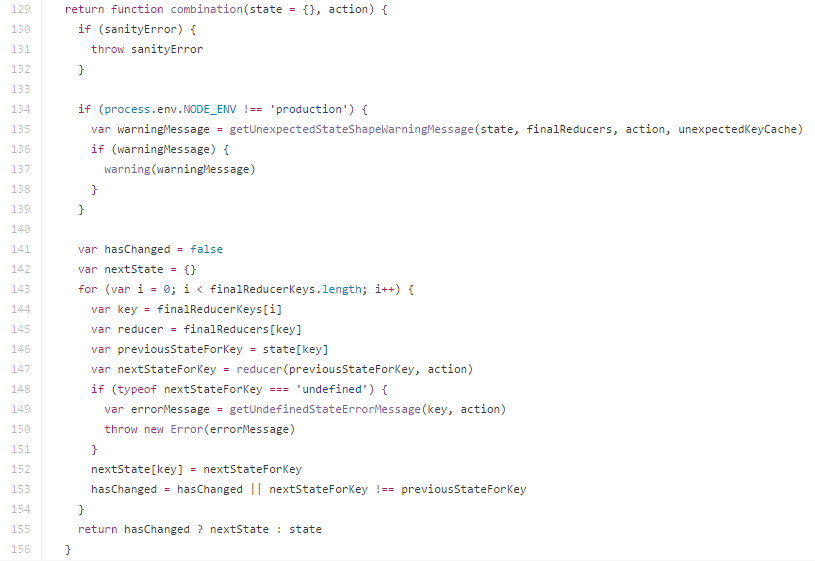
以上这段代码为combineReducers的核心代码,其返回一个function,用于查询真正要变更的state片段
- [141-154] 遍历规范化后的
finalReducers,获取到当前key对应的子reducer和子state,执行reducer得到当前state片段更新后的状态,并更新到整个store tree中。
其中129行中的state,应该是整个store tree对应的state,首次获取previousStateForKey时,值可能为undefined,那么接下来执行var nextStateForKey = reducer(previousStateForKey, action)实际上是依次为每个子state片段进行初始化。 - [153] 本行判定store tree是否被更新,其中
nextStateForKey !== previousStateForKey直接通过引用关系判断state是否变更。故一定要注意,定义reducer方法时,一定要遵循函数式编程,确保传入的state与返回的state不要存在引用关系,否则可能导致store tree中状态无法更新。
小结
至此,我们可以看到combineReducers方法,实际就是在每次要执行reducer时,通过action.type定义的类型进行查询,获得子reducer并执行。
通过以上分析,我们需要注意两个问题:
1、子reducer遵循函数式编程,不要直接变更作为参数传入的state,变更state后,一定要返回一个新state对象,不要跟参数state建立引用关系(可以使用Immutable处理state)
2、由于combineReducers内部仅通过action.type作为查询当前要执行的子reducer的依据,会更新所有查询到的state片段,故不建议子reducer中,action.type的值出现重复,否则可能会误更新state。
总结
本篇通过分析源码整理了Redux中Store对象的执行逻辑,重点分析了dispatch(action)后,store tree内部状态如何更新。
篇幅所限,没有分析如何在store上注册中间件,以及如何在store tree变更后,触发页面更新的过程,这些会在之后的博客中更新
第一次写源码分析还有很多不足,如有错误,欢迎指正。
Redux原理(一):Store实现分析的更多相关文章
- 轻松理解Redux原理及工作流程
轻松理解Redux原理及工作流程 Redux由Dan Abramov在2015年创建的科技术语.是受2014年Facebook的Flux架构以及函数式编程语言Elm启发.很快,Redux因其简单易学体 ...
- react-router + redux + react-redux 的例子与分析
一个 react-router + redux + react-redux 的例子与分析 index.js import React from 'react' import ReactDom fr ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- ConcurrentHashMap实现原理及源码分析
ConcurrentHashMap实现原理 ConcurrentHashMap源码分析 总结 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对Ha ...
- 第2章 rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释. 以下是本文的姊妹篇: 1.rsync(一):基本命令和用法 2.rsync(二):ino ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- (转)ReentrantLock实现原理及源码分析
背景:ReetrantLock底层是基于AQS实现的(CAS+CHL),有公平和非公平两种区别. 这种底层机制,很有必要通过跟踪源码来进行分析. 参考 ReentrantLock实现原理及源码分析 源 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
- 《深入探索Netty原理及源码分析》文集小结
<深入探索Netty原理及源码分析>文集小结 https://www.jianshu.com/p/239a196152de
随机推荐
- Bonobo创建新库出错,解决方案
创建新库出错如下: Native library pre-loader is trying to load native SQLite library "D:\wwwroot\localho ...
- spring mvc 和spring security配置 web.xml设置
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmln ...
- enote笔记语言(1)
what 是什么 why 为什么 when 何时 where 在哪里 whi ...
- PHP flush()与ob_flush()的区别
buffer ---- flush()buffer是一个内存地址空间,Linux系统默认大小一般为4096(1kb),即一个内存页.主要用于存储速度不同步的设备或者优先级不同的 设备之间传办理数据的区 ...
- 【干货分享】前端面试知识点锦集02(CSS篇)——附答案
二.CSS部分 1.解释一下CSS的盒子模型? 回答一:a.标准的css盒子模型:宽度=内容的宽度+边框的宽度+加上内边具的宽度b.网页设计中常听的属性名:内容(content).填充(padding ...
- 在网站开发中很有用的8个 jQuery 效果【附源码】
jQuery 作为最优秀 JavaScript 库之一,改变了很多人编写 JavaScript 的方式.它简化了 HTML 文档遍历,事件处理,动画和 Ajax 交互,而且有成千上万的成熟 jQuer ...
- sed的应用
h3 { color: rgb(255, 255, 255); background-color: rgb(30,144,255); padding: 3px; margin: 10px 0px } ...
- iOS:小技巧(不断更新)
记录下一些不常用技巧,以防忘记,复制用. 1.获取当前的View在Window的frame: UIWindow * window=[[[UIApplication sharedApplication] ...
- Normalize.css的使用及下载
Normalize.css 只是一个很小的CSS文件,但它在默认的HTML元素样式上提供了跨浏览器的高度一致性.相比于传统的CSS reset,Normalize.css是一种现代的.为HTML5准备 ...
- Git和Code Review流程
Code Review流程1.根据开发任务,建立git分支, 分支名称模式为feature/任务名,比如关于API相关的一项任务,建立分支feature/api.git checkout -b fea ...