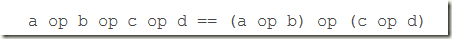前言
本文为java.util.stream 包文档的译文
极其个别部分可能为了更好理解,陈述略有改动,与原文几乎一致
原文可参考在线API文档
Package java.util.stream Description
一些用于支持流上函数式操作的类 ,例如在集合上的map-reduce转换。例如
int sum = widgets.stream()
.filter(b -> b.getColor() == RED)
.mapToInt(b -> b.getWeight())
.sum();
此处,我们使用widgets, 他是一个 Collection<Widget>, 作为一个流的源,
然后在流上执行一个filter-map-reduce 来获得红色widgets重量的总和。(总和是一个归约(reduce)操作的例子)
这个包中引入的关键抽象是流。
类 Stream、IntStream、LongStream和DoubleStream分别是在对象Object和基本类型int、long和double类型上的流。
流与集合的不同有以下几点:
- 不存储数据 流不是存储元素的数据结构;相反,它通过一个哥哥计算操作组合而成的管道,从一个数据源,如数据结构、数组、生成器函数或i/o通道 来传递元素
- 函数特性 一个流上的操作产生一个结果,但是不会修改它的源。例如,过滤集合 获得的流会产生一个没有被过滤元素的新流,而不是从源集合中删除元素
- 延迟搜索 许多流操作,如过滤、映射或重复删除,都可以延迟实现,从而提供出优化的机会。
- 例如,“找到带有三个连续元音的第一个字符串”不需要检查所有的输入字符串。
- 流操作分为中间(流生成)操作和终端(值或副作用生成)操作。许多的中间操作, 如filter,map等,都是延迟执行。
- 中间操作总是惰性的的。
- Stream可能是无限的 虽然集合的大小是有限的,但流不需要。诸如limit(n)或findFirst()这样的短路操作可以允许在有限时间内完成无限流的计算。
- 消耗的 流的元素只在流的生命周期中访问一次。就像迭代器一样,必须生成一个新的流来重新访问源的相同元素
流可以通过多种方式进行获得,比如
- Collection 提供的stream parallelStream
- 从数组 Arrays.stream(Object[]) 静态方法
- Stream类的静态工厂方法 比如 Stream.of(Object[]), IntStream.range(int, int), Stream.iterate(Object, UnaryOperator) Stream.generate
- BufferedReader.lines(); 文件行
- 获取文件路径的流: Files类的find(), lines(), list(), walk();
- Random.ints() 随机数流
- JDK中的许多其他流载方法,包括BitSet.stream(), Pattern.splitAsStream(java.lang.CharSequence), and JarFile.stream().
还可以从第三方类库的提供中创建其他一些流 ,详见 Low-level stream construction
Stream operations and pipelines流操作以及管道
流操作被划分为中间和终端操作,通过流管道组合起来。
- 一条流管道由一个源(如一个集合、一个数组、一个生成器函数或一个i/o通道)组成;
- 然后是零个或更多的中间操作,例如stream.filter 或者stream.map;
- 还有一个终端操作,如stream.forEach或Stream.reduce
中间操作返回一条新流,他们总是惰性的;
执行诸如filter()之类的中间操作实际上并不会立即执行任何过滤操作,而是创建了一个新流,当遍历时,它包含与给定谓词相匹配的初始流的元素。直到管道的终端操作被执行,管道源的遍历才会开始
终端操作,例如Stream.forEach 和 IntStream.sum,可以遍历流以产生结果或副作用。
在执行终端操作之后,流管道被认为是被消耗掉的,并且不能再被使用;
如果您需要再次遍历相同的数据源,您必须重新从数据源获得一条新流
在几乎所有情况下,终端操作都很迫切,在返回之前完成了数据源的遍历和管道的处理。只有终端操作iterator() 和 spliterator() 不是;
这些都是作为一个“逃生舱口”提供的,以便在现有操作不足以完成任务的情况下,启用任意客户控制的管道遍历
延迟处理流可以显著提高效率;
在像上面的filer-map-sum例子这样的管道中,过滤、映射和求和可以被融合到数据的单个传递中,并且具有最小的中间状态。
惰性还允许在没有必要的情况下避免检查所有数据;对于诸如“查找第一个超过1000个字符的字符串”这样的操作,只需要检查足够的字符串,就可以找到具有所需特征的字符串,而不需要检查源的所有字符串。(当输入流是无限的而不仅仅是大的时候,这种行为就变得更加重要了。)
中间操作被进一步划分为无状态和有状态操作。
无状态操作,如filter和map,在处理新元素时不保留以前处理的元素的状态——每个元素都可以独立于其他元素的操作处理。
有状态的操作,例如distinct和sorted,则需要考虑从先前看到处理的元素中合并状态。
有状态操作可能需要在产生结果之前处理整个输入。
例如,直到一个人看到了流的所有元素之前 他没办法完成对流的排序
因此,在并行计算下,一些包含有状态中间操作的管道可能需要对数据进行多次传递,或者可能需要缓冲重要数据。
包含完全无状态的中间操作的管道可以在单次传递过程中进行处理,无论是顺序的还是并行的,只有最少的数据缓冲
此外,一些操作被认为是短路操作。一个中间操作,如果在提供无限流输入时,它可能会产生一个有限的流,那么他就是短路的。
如果在无限流作为输入时,它可能在有限的时间内终止,这个终端操作是短路的。
在管道中进行短路操作是处理无限流在有限时间内正常终止的必要条件,但不是充分条件
Parallelism并行
通过显式的for循环处理元素本质上是串行的
流通过将计算重新定义为聚合操作的管道,而不是在每个单独元素上立即执行操作,从而促进并行执行。
所有的流操作都可以串行或并行执行
JDK中流的实现创建的都是串行流, 除非显式的设置为并行
例如,Collection有方法Collection.stream()和Collection.parallelstream(),它们分别产生串行和并行流;
其他的流方法比如 IntStream.range(int, int) 产生串行的流,但是可以通过调用BaseStream.parallel()方法设置为 并行化
想要计算所有 widgets的重量之和 只需要
这个例子的串行和并行版本的唯一区别是初始时创建流,使用parallelStream()而不是stream()
当启动终端操作时,流管道是按顺序或并行执行的,这取决于它被调用的流的策略模式。
一个流是否可以串行或并行执行,可以用isParallel()方法来获得,
可以用BaseStream.sequential() 和 BaseStream.parallel() 操作修改。
当启动终端操作时,流管道是按顺序或并行执行的,这取决于它被调用的流的模式。
除了被确定为显式非确定性的操作之外,如findAny(),无论是顺序执行还是并行执行,都不应该改变计算的结果。
大多数流操作接受描述用户指定行为的参数,这些参数通常是lambda表达式。
为了保持正确的行为,这些行为参数必须是不干涉non-interfering的,并且在大多数情况下必须是无状态的。
这些参数始终是函数式接口的实例,例如Function,通常是lambda表达式或方法引用
Non-interference 无干扰的 非干涉的
Streams允许您在各种数据源上执行可能并行的聚合操作,甚至包括ArrayList之类的非线程安全集合。
只有当我们能够在流管道的执行过程中防止对数据源的干扰时这才是可能的。
除了逃脱舱口iterator()和spliterator()之外,都是在调用终端操作时开始执行,并在终端操作完成时结束。
对于大多数数据源来说,防止干扰意味着确保在流管道的执行过程中根本没有修改数据源。
这方面的一个显著的例外是源是并发集合的流,它们是专门设计用来处理并发修改的。并发流源是那些Spliterator 设置了并发特性(CONCURRENT characteristic)
因此,在流管道中,源不是并发的行为参数,永远不应该修改流的数据源。
一个行为参数将被称之为干扰的(interfere) 如果对于一个非并发数据源来说如果它修改或导致被修改数据源被修改.
不仅仅是并行的管道需要,所有的管道都需要是非干扰的(non-interference)
除非流数据源是并发的,否则在执行流管道时修改stream的数据源可能会导致异常、错误的答案或不一致的行为。
对于表现良好的stream,数据源是可以修改的,只要是在终端操作开始之前,并且所有的修改都会包含在内
比如
首先创建一个列表,由两个字符串组成:“one”;和“two”。
然后,从该列表中创建一条stream。接下来,通过添加第三个字符串:“three”来修改列表。
最后,流的元素被collect 以及joining在一起。由于该列表在终端收集操作开始之前被修改,结果将是一串“one two three”。
从JDK集合返回的所有流,以及大多数其他JDK类,都像这样表现良好;
对于其他库生成的流,请参阅 Low-level stream construction,以满足构建行为良好的流的需求。
Stateless behaviors无状态行为
如果流操作的行为参数是有状态的,那么流管道的结果可能是不确定的或不正确的。
有状态的lambda(或实现适当的功函数接口的其他对象)是一个其结果依赖于任何可能在流水线执行过程中发生变化的状态。
有状态lambda的一个例子是map()的参数:
在这里,如果映射操作是并行执行的,那么相同输入的结果可能因线程调度差异而变化,而对于无状态lambda表达式,结果总是相同的
还要注意的是,试图从行为参数访问可变状态时,在安全性和性能方面是您一个错误的选择;
如果你不同步访问那个状态,你就有了数据竞争,因此你的代码可能出现问题,
但是如果你对那个状态进行同步访问,你就有可能会破坏你想要从并行性中得到的受益。
最好的方法是在流操作中完全地避免有状态的行为参数; 通常总会有种方法可以重构流以避免状态性
Side-effects副作用
一般来说,对流操作的行为参数的副作用是不鼓励的,因为它们通常会导致不知情的违反无状态要求的行为,以及其他线程安全隐患
如果行为参数确实有副作用,除非显式地声明,否则就无法保证这些副作用对其他线程的可见性,也不能保证在同一条管道内的“相同”元素上的不同操作在相同的线程中执行。此外,这些影响的排序可能出乎意料。即使管道被限制生成一个与stream源的处理顺序一致的结果(例如,IntStream.range(0,5).parallel().map(x -> x*2).toArray() 必须生成0、2、4、6、8),对于将mapper函数应用于个别元素的顺序,或者对于给定元素执行任何行为参数的顺序,都没有保证
对许多可能会被尝试使用于副作用的计算中,可以替换为无副作用的,更安全更有效的表达,比如使用归约而不是可变的累积器。
然而,使用println()来进行调试的副作用通常是无害的。少部分的流操作,如forEach()和peek(),用的就是他们的副作用;这些应该小心使用。
下面的例子演示,如何从一个使用副作用的计算转变为不适用副作用
下面的代码搜索一个字符串流,以匹配给定的正则表达式,并将匹配放在列表中
这段代码不必要地使用了副作用。如果并行执行,ArrayList的非线程安全将导致不正确的结果,并且添加所需的同步将导致竞争,从而破坏并行性的好处。
此外,在这里使用副作用是完全没有必要的;forEach()可以简单地被替换为更安全、更高效、更适合并行化的reduce操作。
Ordering 排序
流可能有也可能没有定义好的顺序。流是否有顺序取决于源和中间操作。(所谓定义好的顺序,就是说原始数据源是否有序)
某些流源(如列表或数组)本质上是有序的,而其他的(如HashSet)则不是。
一些中间操作,比如sorted(),可以在无序的流中强加一个顺序,而其他的操作可能会使一个有序的流变成无序,例如BaseStream.unordered().
此外,一些终端操作可能会忽略顺序,比如forEach()。
如果一个流有序,大多数操作都被限制在顺序的元素上操作;
如果流的源是包含1、2、3的列表,那么执行map(x-x 2)的结果必须是2、4、6。
然而,如果源没有定义的顺序,那么值2、4、6的任何排列都将是一个有效的结果。
对于串行流,顺序的存在与否并不影响性能,只影响确定性。
如果一个流是有序的,在相同的源上重复执行相同的流管道将产生相同的结果;
如果没有排序,重复执行可能会产生不同的结果
对于并行流,放松排序的限制有时可以实现更高效的执行。
如果元素的排序不是很重要,那么可以更有效地实现某些聚合操作,如过滤重复元素(distinct() )或分组归约(Collectors.groupingBy())。
类似地,与顺序相关的操作,如limit(),可能需要缓冲以确保正确的排序,从而破坏并行性的好处。
在流有顺序的情况下,但是用户并不特别关心这个顺序,显式地通过unordered()方法调用取消排序, 可能会改善一些有状态或终端操作的并行性能。
然而,大多数的流管道,例如上面的“blocks的重量总和”,即使在排序约束下仍然有效地并行化。
Reduction operations归约操作
一个归约操作(也称为折叠)接受一系列的输入元素,并通过重复应用组合操作将它们组合成一个简单的结果,例如查找一组数字的总和或最大值,或者将元素累积到一个列表中。streams类有多种形式的通用归约reduce操作,称为reduce()和collect(),以及多个专门化的简化形式,如sum()、max()或count()
当然,这样的操作可以很容易用简单的顺序循环来实现,如下所示
然而,我们有充分的理由倾向于reduce操作,而不是像上面这样的迭代累计运算。
它不仅是一个“更抽象的”——它在流上把流作为一个整体运行而不是作用于单独的元素——但是一个适当构造的reduce操作本质上是可并行的,只要用于处理元素的函数(s)是结合的associative和无状态stateless的。举个例子,给定一个数字流,我们想要找到和,我们可以写:
几乎不需要怎么修改,就可以以并行的方式运行
之所以归约操作可以很好地并行,是因为实现可以并行地操作数据的子集,然后将中间结果组合在一起,得到最终的正确答案。(即使该语言有一个“"parallel for-each"”构造,迭代累计运算方法仍然需要开发人员提供对共享累积变量sum的线程安全更新以及所需的同步,这可能会消除并行性带来的任何性能收益。)
使用reduce()代替了归约操作的并行化的所有负担,并且库可以提供一个高效的并行实现,不需要额外的同步
前面展示的“widgets”示例展示了如何与其他操作相结合,以替换for循环。
如果widgets 是Widget 对象的集合,它有一个getWeight方法,我们可以找到最重的widget:
在更通用的形式中 对类型为T的元素,并且返回结果类型为U的reduce操作 需要三个参数:
在这里,identity不仅仅是归约的初始化结果值或者如果没有任何元素时的一个默认的返回值
迭代累计运算器接受部分结果和下一个元素,并产生一个新的中间结果。
组合函数结合了两个部分结果,产生了一个新的中间结果。
(在并行减少的情况下,组合是必要的,在这个过程中,输入被分区,每个分区都计算出部分的累积,然后将部分结果组合起来产生最终的结果。)
更准确地说,identity必须是组合函数的恒等式。这意味着对所有的u,combiner.apply(identity, u)等于u,
另外,组合函数必须是结合的,必须与累加器函数兼容:
对所有u和t,
combiner.apply(identity, u) 必须等于accumulator.apply(u, t).
三参数形式是双参数形式的泛化,将映射步骤合并到累加步骤中。
我们可以用更一般的形式重新改写这个简单的widgets重量的例子
尽管显式的map-reduce的形式更易于阅读,因此通常应该优先考虑。
通用的形式是为了 通过将映射和减少到单个函数,以重要的工作进行优化 这种场景
Mutable reduction 可变的归约
一个可变的归约操作在处理流中的元素时,将输入元素积累到一个可变的结果容器中,例如一个Collection或StringBuilder,
如果我们想要获取一串字符串的流并将它们连接成一个长字符串,我们可以通过普通的reduce来实现这个目标:
我们会得到想要的结果,它甚至可以并行工作,然而,但是我们可能对性能不满意
这样的实现将会进行大量的字符串复制 时间复杂度O(n^2)
一种更有效的方法是将结果累积到StringBuilder中,这是一个用于累积字符串的可变容器
就如同我们对普通的归约操作处理一样,我们可以使用相同的技术来处理可变的归约
可变归约操作称为collect()当它将期望的结果收集到一个结果容器中,例如一个集合
收集操作需要三个功能:
一个supplier 功能来构造结果容器的新实例,
一个累计运算器函数将一个输入元素合并到一个结果容器中,
一个组合函数将一个结果容器的内容合并到另一个结果容器中。
它的形式与普通归约的一般形式非常相似
与reduce()相比,以这种抽象的方式表示收集的好处是它直接适合并行化:
我们可以并行地累计运算部分结果,然后将它们组合起来,只要积累和组合功能满足适当的需求。
例如,为了收集流中的元素的字符串表示到ArrayList,我们可以编写显式的for循环
或者我们可以使用一个可并行的collect形式
或者,从累加器函数中提取出来map操作,我们可以更简洁地表达它:
在这里,我们的supplier只是ArrayList的构造器,累加器将string element元素添加到ArrayList中,组合器简单地使用addAll将字符串从一个容器复制到另一个容器中
collect的三个部分——supplier, accumulator, 和combiner ——是紧密耦合的。
我们可以使用Collector来抽象的表达描述这三部分。
上面的例子可以将字符串collect到列表中,可以使用一个标准收集器来重写:
将可变的归约打包成收集器有另一个优点:可组合性。
类Collectors包含许多用于收集器的预定义工厂,包括将一个收集器转换为另一个收集器的组合器。
例如,假设我们有一个Collector,它计算员工流的薪水之和,如下所列
(对于第二个类型的参数 ? ,仅仅表明我们不关心收集器所使用的中间类型。 )如果我们想要创建一个收集器来按部门计算工资的总和,我们可以使用groupingBy来重用summingSalaries 薪水:
就像常规的reduce操作一样,只有满足适当的条件collect() 操作才能够并行化
对于任何部分累计运算的结果,将其与空结果容器相结合combiner 必须产生一个等效的结果
也就是说,对于任意一个部分累计运算的结果p,累计运算或者组合调用的结果,p必须等于 combiner.apply(p, supplier.get()).
而且,无论计算是否分割,它必须产生一个等价的结果。对于任何输入元素t1和t2,下面计算的结果r1和r2必须是等价的
在这里,等价通常指的是Object.equals(Object).。但在某些情况下,等价性的要求可能会降低
Reduction, concurrency, and ordering 归约 并发与排序
通过一些复杂的reduce操作,例如生成map的collect(),例如
并行执行操作可能实际上会产生反效果。这是因为组合步骤(通过键将一个Map合并到另一个Map)对于某些Map实现来说可能代价很大
然而,假设在这个reduce中使用的结果容器是一个可修改的集合——例如ConcurrentHashMap。在这种情况下,对迭代累计运算器的并行调用实际上可以将它们的结果并发地放到相同的共享结果容器中,从而将不再需要组合器合并不同的结果容器。这可能会促进并行执行性能的提升。我们称之为并行reduce
支持并发reduce的收集器以Collector.Characteristics.CONCURRENT characteristic特性为标志。并发特性。然而,并发集合也有缺点。
如果多个线程将结果并发地存入一个共享容器,那么产生结果的顺序是不确定的。
因此,只有在排序对正在处理的流不重要的情况下,才可能执行并发的reduce
下面这些条件下 Stream.collect(Collector) 的实现会并发reduce(归约)
- 流是并行的;
- 收集器有Collector.Characteristics.CONCURRENT 特性
- 要么是无序的流,要么收集器拥有Collector.Characteristics.UNORDERED 特性
您可以通过使用BaseStream.unordered()方法来确保流是无序的。例如:
(Collectors.groupingByConcurrent(java.util.function.Function<? super T, ? extends K>) 等同于 groupingBy).
Associativity 结合性
如果一个操作或者函数方法满足下面的形式,那么他就是结合的
如果我们把这个问题扩大到四项,就可以看到这种结合性对于并行的重要性
这样我们就可以把(a op b) 和 (c op d) 进行并行计算 最后在对他们进行 op 运算
结合性操作的例子包括数字加法、min、max和字符串串联
Low-level stream construction 低级流构造器
到目前为止,所有的流示例都使用了Collection.stream()或Arrays.stream(Object)等方法来获得一个stream。这些处理流的方法是如何实现的?
类StreamSupport提供了许多用于创建流的低级方法,所有这些方法都使用某种形式的Spliterator。
一个Spliterator是迭代器的一个并行版本;
它描述了一个(可能是无限的)元素集合,支持顺序前进、批量遍历,并将一部分输入分割成另一个可并行处理的Spliterator。
在最低层,所有的流都由一个Spliterator驱动构造
在实现Spliterator时,有许多实现选择,几乎所有的实现都是在简单的实现和运行时性能之间进行权衡。
创建Spliterator的最简单、但最不高性能的方法是,使用 Spliterators.spliteratorUnknownSize(java.util.Iterator, int)从一个iterator中创建spliterator 。
虽然这样的spliterator 可以工作,但它可能会提供糟糕的并行性能,因为我们已经丢失了容量信息(底层数据集有多大),以及被限制为一个简单的分割算法。
一个高质量的spliterator 将提供平衡的和已知大小的分割,精确的容量信息,以及一些可用于实现优化执行的spliterator 或数据的其他特征 (特征见spliterator characteristics)
可变数据源的Spliterators 有一个额外的挑战;绑定到数据的时间,因为数据可能在创建Spliterators 后和开始执行流管道的期间,发生变化。
理想情况下,一个流的spliterator将报告一个IMMUTABLE or CONCURRENT;如果不是,应该是后期绑定(late-binding)。
如果一个源不能直接提供一个推荐的spliterator,它可能会通过Supplier 间接地提供一个spliterator,并通过接收Supplier作为参数的stream()版本构造一个stream。只有在流管道的终端操作之后,才从Supplier处获得spliterator
这些要求极大地减少了流源的变化和流管道的执行之间的潜在的干扰。
基于具有所需特性的spliterators ,或者使用 Supplier-based 的工厂的形式的流,在终端操作开始之前对数据源的修改是不受影响的(如果流操作的行为参数满足不干涉和无状态的要求标准)。参见不干涉 Non-Interference的细节。
- Fuchsia OS入门官方文档
Fuchsia Pink + Purple == Fuchsia (a new Operating System) Welcome to Fuchsia! This document has ever ...
- [三]java8 函数式编程Stream 概念深入理解 Stream 运行原理 Stream设计思路
Stream的概念定义 官方文档是永远的圣经~ 表格内容来自https://docs.oracle.com/javase/8/docs/api/ Package java.util.s ...
- Java8函数式编程探秘
引子 将行为作为数据传递 怎样在一行代码里同时计算一个列表的和.最大值.最小值.平均值.元素个数.奇偶分组.指数.排序呢? 答案是思维反转!将行为作为数据传递. 文艺青年的代码如下所示: public ...
- 重识Java8函数式编程
前言 最近真的是太忙忙忙忙忙了,很久没有更新文章了.最近工作中看到了几段关于函数式编程的代码,但是有点费解,于是就准备总结一下函数式编程.很多东西很简单,但是如果不总结,可能会被它的各种变体所困扰.接 ...
- 关于Java8函数式编程你需要了解的几点
函数式编程与面向对象的设计方法在思路和手段上都各有千秋,在这里,我将简要介绍一下函数式编程与面向对象相比的一些特点和差异. 函数作为一等公民 在理解函数作为一等公民这句话时,让我们先来看一下一种非常常 ...
- Java8 函数式编程详解
Java8 函数式编程详解 Author:Dorae Date:2017年11月1日23:03:26 转载请注明出处 说起Java8,可能很多人都已经知道其最大的改进,就是引入了Lambda表达式与S ...
- [2017.02.23] Java8 函数式编程
以前学过Haskell,前几天又复习了其中的部分内容. 函数式编程与命令式编程有着不一样的地方,函数式编程中函数是第一等公民,通过使用少量的几个数据结构如list.map.set,以及在这些数据结构上 ...
- Java8函数式编程以及Lambda表达式
第一章 认识Java8以及函数式编程 尽管距离Java8发布已经过去7.8年的时间,但时至今日仍然有许多公司.项目停留在Java7甚至更早的版本.即使已经开始使用Java8的项目,大多数程序员也仍然采 ...
- Java8函数式编程的宏观总结
1.java8优势通过将行为进行抽象,java8提供了批量处理数据的并行类库,使得代码可以在多核CPU上高效运行. 2.函数式编程的核心使用不可变值和函数,函数对一个值进行处理,映射成另一个值. 3. ...
随机推荐
- Bootstarp 使用布局
实现 Bootstrap 基本布局 看到了一篇 20 分钟打造 Bootstrap 站点的文章,内容有点老,重新使用 Bootstrap3 实现一下,将涉及的内容也尽可能详细说明. 1. 创建基本的页 ...
- TS+React+Redux 使用之搭建环境
使用 create-react-app 构建 1.全局安装create-react-app npm install -g create-react-app 2.创建一个项目 create-react- ...
- java方法的调用
各种方法的调用实例 package cn.edu.fhj.day004; public class FunctionDemo { // 定义全局的变量 public int a = 3; public ...
- 【PHP版】火星坐标系 (GCJ-02) 与百度坐标系 (BD-09ll)转换算法
首先感谢java版作者@宋宋宋伟,java版我是看http://blog.csdn.net/coolypf/article/details/8569813 然后根据java代码修改成了php代码. & ...
- CentOS 7.3/Linux .net core sdk 安装
执行下列命令,安装.NET Core SDK(微软官方教程地址 https://www.microsoft.com/net/learn/get-started/linuxcentos) 点开链接,选择 ...
- 20175324 mycp
具体描述: 编写MyCP.java 实现类似Linux下cp XXX1 XXX2的功能,要求MyCP支持两个参数: java MyCP -tx XXX1.txt XXX2.bin 用来把文本文件(内容 ...
- 【记录】Windows 操作系统常用快捷命令
https://www.lifewire.com/command-line-commands-for-control-panel-applets-2626060 打印机 control pr ...
- ubuntu安装输入法
sudo apt-get install ibus-pinyin sudo ibus-setup
- python获取函数注释 __doc__
使用 help 函数 可以查看 函数的注释内容 但是它也有点"添油加醋" 其实函数的注释被保存在 __doc__属性里面 PS 双下划线 def f(): "&quo ...
- [Swift]LeetCode70. 爬楼梯 | Climbing Stairs
You are climbing a stair case. It takes n steps to reach to the top. Each time you can either climb ...