【学习笔记】tensorflow文件读取
先看下文件读取以及读取数据处理成张量结果的过程:
一般数据文件格式有文本、excel和图片数据。那么TensorFlow都有对应的解析函数,除了这几种。还有TensorFlow指定的文件格式。
TensorFlow还提供了一种内置文件格式TFRecord,二进制数据和训练类别标签数据存储在同一文件。模型训练前图像等文本信息转换为TFRecord格式。TFRecord文件是protobuf格式。数据不压缩,可快速加载到内存。TFRecords文件包含 tf.train.Example protobuf,需要将Example填充到协议缓冲区,将协议缓冲区序列化为字符串,然后使用该文件将该字符串写入TFRecords文件。在图像操作我们会介绍整个过程以及详细参数。
文件读取
文件队列构造
tf.train.string_input_producer(string_tensor, ,shuffle=True):将输出字符串(例如文件名)输入到管道队列
- string_tensor:含有文件名的1阶张量
- num_epochs:过几遍数据,默认无限过数据
- return:具有输出字符串的队列
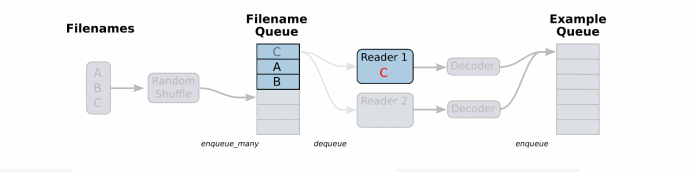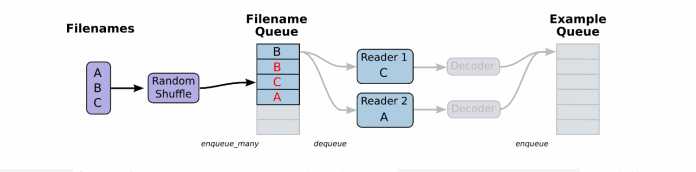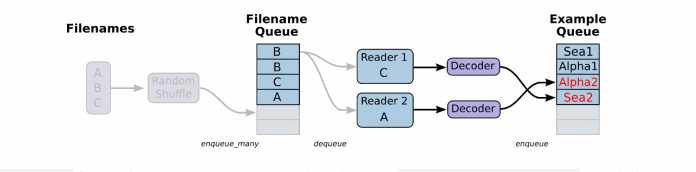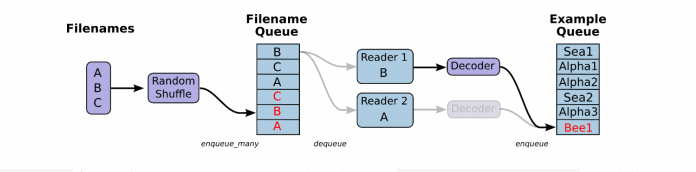
将文件名列表交给tf.train.string_input_producer函数。string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。一过程是比较均匀的,因此它可以产生均衡的文件名队列。
这个QueueRunner工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。根据你的文件格式,选择对应的文件阅读器,然后将文件名队列提供给阅读器的read方法。阅读器的read方法会输出一个键来表征输入的文件和其中纪录(对于调试非常有用),同时得到一个字符串标量,这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
文件阅读器
根据文件格式,选择对应的文件阅读器
class tf.TextLineReader:阅读文本文件逗号分隔值(CSV)格式,默认按行读取
class tf.FixedLengthRecordReader(record_bytes):要读取每个记录是固定数量字节的二进制文件
- record_bytes:整型,指定每次读取的字节数
tf.TFRecordReader:读取TfRecords文件
文件内容解码器
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
tf.decode_csv(records,record_defaults=None,field_delim = None,name = None):将CSV转换为张量,与tf.TextLineReader搭配使用
- records:tensor型字符串,每个字符串是csv中的记录行
- field_delim:默认分割符”,”
- record_defaults:参数决定了所得张量的类型,并设置一个值在输入字符串中缺少使用默认值
tf.decode_raw(bytes,out_type,little_endian = None,name = None) :将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用,二进制读取为uint8格式
开启线程操作
tf.train.start_queue_runners(sess=None,coord=None):收集所有图中的队列线程,并启动线程
- sess:所在的会话中
- coord:线程协调器
- return:返回所有线程队列
管道读端批处理
tf.train.batch(tensors,batch_size,num_threads = 1,capacity = 32,name=None):读取指定大小(个数)的张量
- tensors:可以是包含张量的列表
- batch_size:从队列中读取的批处理大小
- num_threads:进入队列的线程数
- capacity:整数,队列中元素的最大数量
- return:tensors
tf.train.shuffle_batch(tensors,batch_size,capacity,min_after_dequeue, num_threads=1,) :乱序读取指定大小(个数)的张量
- min_after_dequeue:留下队列里的张量个数,能够保持随机打乱
CSV文件读取案例
import tensorflow as tf
import os
def readcsv(filelist):
"""
读取csv文件
"""
# 构造文件队列
file_queue = tf.train.string_input_producer(filelist)
# 构建阅读器
reader = tf.TextLineReader()
key, value = reader.read(file_queue)
# 对每行内容进行解码
records = [["None"], ["None"]]
example, label = tf.decode_csv(value, record_defaults=records)
# 批处理
example_batch, label_batch = tf.train.batch([example, label], batch_size=10, num_threads=1, capacity=10)
return example_batch, label_batch
if __name__ == '__main__':
filelist = os.listdir("./data/csvdata")
filelist = ["./data/csvdata/{}".format(i) for i in filelist]
example_batch, label_batch = readcsv(filelist)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
# 线程协调器
coord = tf.train.Coordinator()
# 开启读取文件线程
threads = tf.train.start_queue_runners(sess, coord=coord)
# 打印数据
print(sess.run([example_batch, label_batch]))
coord.request_stop()
coord.join()
【学习笔记】tensorflow文件读取的更多相关文章
- Linux学习笔记之文件读取过程
0x00 概述 对于Linux系统来说,一切的数据都起源于磁盘中存储的文件.Linux文件系统的结构及其在磁盘中是如何存储的?操作系统是怎样找到这些文件进行读取的?这一章主要围绕这几个问题进行介绍(以 ...
- Linux系统学习笔记:文件I/O
Linux支持C语言中的标准I/O函数,同时它还提供了一套SUS标准的I/O库函数.和标准I/O不同,UNIX的I/O函数是不带缓冲的,即每个读写都调用内核中的一个系统调用.本篇总结UNIX的I/O并 ...
- MySQL学习笔记-数据库文件
数据库文件 MySQL主要文件类型有如下几种 参数文件:my.cnf--MySQL实例启动的时候在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了某种内存结构的大小等设置,还介绍了参数类 ...
- Django:学习笔记(8)——文件上传
Django:学习笔记(8)——文件上传 文件上传前端处理 本模块使用到的前端Ajax库为Axio,其地址为GitHub官网. 关于文件上传 上传文件就是把客户端的文件发送给服务器端. 在常见情况(不 ...
- Liunx学习笔记(三) 文件权限
一.文件权限 1.查看文件权限 (1)文件权限 在 Linux 中对于文件有四种访问权限,列举如下: 可读取:r,Readable 可写入:w,Writable 可执行:x,Execute 无权限:- ...
- Java学习-013-文本文件读取实例源代码(两种数据返回格式)
此文源码主要为应用 Java 读取文本文件内容实例的源代码.若有不足之处,敬请大神指正,不胜感激! 1.读取的文本文件内容以一维数组[LinkedList<String>]的形式返回,源代 ...
- SpringMVC:学习笔记(8)——文件上传
SpringMVC--文件上传 说明: 文件上传的途径 文件上传主要有两种方式: 1.使用Apache Commons FileUpload元件. 2.利用Servlet3.0及其更高版本的内置支持. ...
- APUE学习笔记3_文件IO
APUE学习笔记3_文件IO Unix中的文件IO函数主要包括以下几个:open().read().write().lseek().close()等.这类I/O函数也被称为不带缓冲的I/O,标准I/O ...
- 【数学建模】MATLAB学习笔记——函数式文件
MATLAB学习笔记——函数式文件 引入函数式文件 说明: 函数式文件主要用于解决计算中的参数传递和函数调用的问题. 函数式的标志是它的第一行为function语句. 函数式文件可以有返回值,也可以没 ...
随机推荐
- Kotlin基础
1.函数也是对象,可以作为参数和返回值 2.使用驼峰命名,尽量避免下划线 3.public函数应当有说明文档 4.lambda中花括号内前后都应该有空格 5.空值安全检查 var s: String ...
- 算法与数据结构(四) 图的物理存储结构与深搜、广搜(Swift版)
开门见山,本篇博客就介绍图相关的东西.图其实就是树结构的升级版.上篇博客我们聊了树的一种,在后边的博客中我们还会介绍其他类型的树,比如红黑树,B树等等,以及这些树结构的应用.本篇博客我们就讲图的存储结 ...
- 坦白说bug
安卓收藏他发的图片就可以在收藏里看到了哦 苹果直接搜索聊天记录就行了哦(人 •͈ᴗ•͈)۶♡♡比心心
- 【安富莱二代示波器教程】第16章 附件A---电阻屏触摸校准
第16章 附件A---电阻屏触摸校准 二代示波器的触摸校准比较简单,随时随地都可以做触摸校准,按下K1按键即可校准.有时候我们做触摸校准界面,需要在特定的界面才可以进入触摸校准状态,非常繁琐 ...
- SSL/TLS握手过程
----------------------------------专栏导航----------------------------------HTTPS协议详解(一):HTTPS基础知识 HTTPS ...
- Javascript高级编程学习笔记(89)—— Canvas(6) 变换
变换 通过上下文的变化,可以对图像进行处理后再将其绘制到画布上 当我们创建上下文时,会以默认值初始化变化矩阵,在默认的变换矩阵下所有处理都按描述直接绘制. 而当我们为上下文应用变换时,会导致使用不同的 ...
- Javascript高级编程学习笔记(86)—— Canvas(3)绘制矩形
绘制矩形 矩形是唯一一种可以直接在2D上下文中绘制的形状. 与矩形有关的方法包括: fillRect() strokeRect() clearRect() 上述方法都接收四个参数: 绘制矩形的 X 坐 ...
- [Swift]LeetCode811. 子域名访问计数 | Subdomain Visit Count
A website domain like "discuss.leetcode.com" consists of various subdomains. At the top le ...
- Build Assimp library for Android
Build Assimp library for Android 首先各路教程中有推荐使用 NDK 或者 STANDALONE TOOLCHAIN 编译的,根据我的理解,这两种方式都是可以的,如果能直 ...
- 想成为Python全栈开发工程师必须掌握的技能
什么是Python全栈工程师? 即从前端页面的实现,到后台代码的编写,再到数据库的管理,一人可以搞定一个公司网站的所有事情,真正实现全栈开发. 全栈只是个概念 也分很多种类 真正的全栈工程师涵盖了we ...