java解析HTML之神器------Jsoup
背景:公司项目要对接第三方商城的商品到自己的商城来卖,商品详情给了个链接url,因为对方的商品详情有他们的物流说明,售后信息,所以要求去掉这部分的代码
@Test
public void getItemDetail() throws IOException { String url="https://www.xxx.com";//此处url作了处理,不能提供真实url,防止泄密,侵权,大家可以自己找一个url来完
String itemDetail = getItemDetail(url);
System.out.println(itemDetail);
} private String getItemDetail(String url){
//思路:通过请求获取html文本,通过选择器找到对应的标签,然后找到该标签的父标签,最后将父标签移除
String itemDetailHtml = NetUtil.httpGet(url, Maps.newHashMap());//获取商品详情
if(StringUtils.isBlank(itemDetailHtml)){ return null;
}
Document parse = Jsoup.parse(itemDetailHtml);
//也可以直接使用url来解析,下面注释所示
//URL linkUrl = new URL(url);
// Document parse=Jsoup.parse(linkUrl,5000);
if(parse==null){ return null;
}
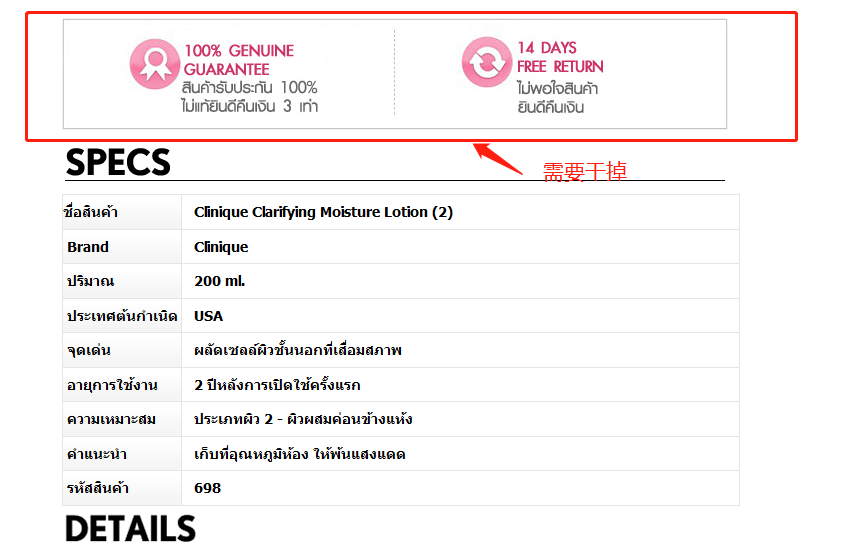
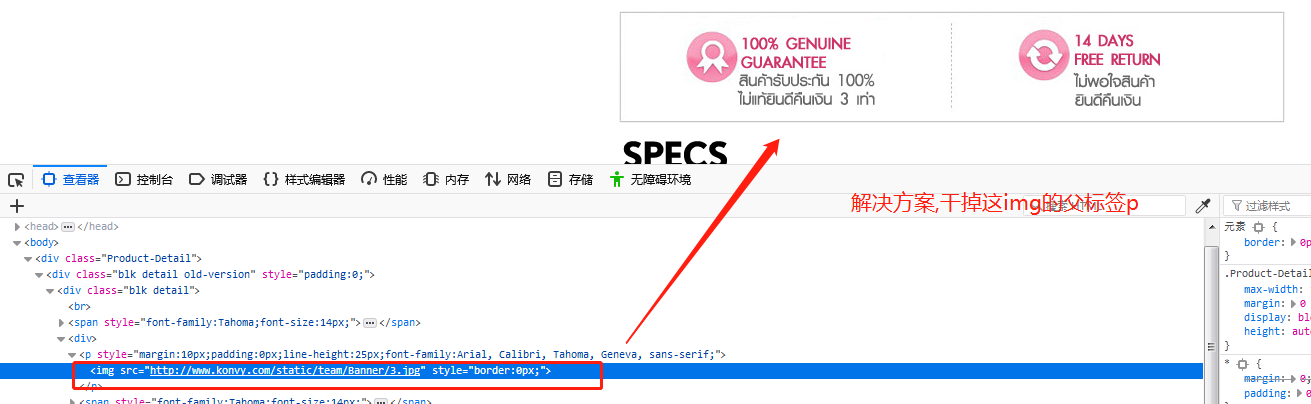
//干掉头部图片
//Jsoup强大之处在于可以使用css选择器,但要注意img[src='http://www.konvy.com/static/team/Banner/3.jpg'],属性值这里加了引号,这样会取不到值,下面才是正确的
Elements topImgEls = parse.select("img[src=http://www.konvy.com/static/team/Banner/3.jpg]"); //头部url
if(null!=topImgEls && topImgEls.size()>=1){
Element topImgEl = topImgEls.get(0);//获取第一个元素
Element topPEL = topImgEl.parent();//获取该img标签的父标签P标签
topPEL.remove();//整个p标签移除,元素可以将自己从整个document中移除
}
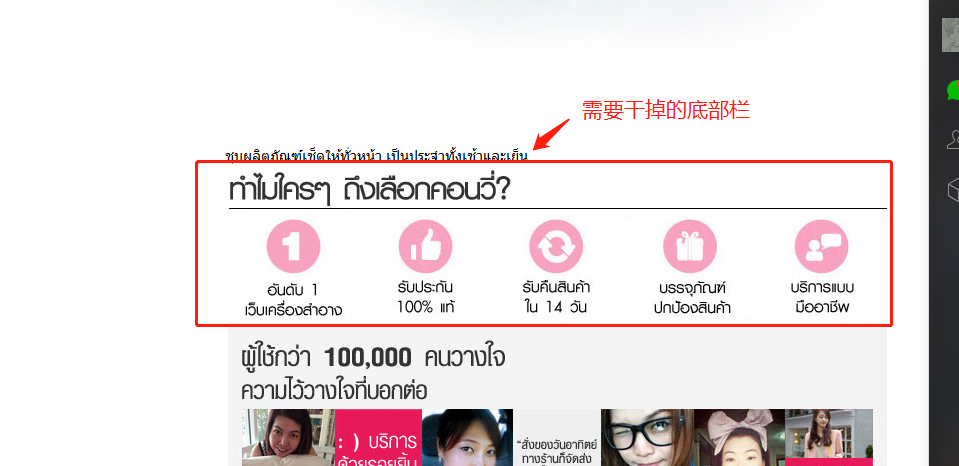
//干掉底部图片
Elements aEls= parse.select("a[href=http://www.konvy.com/account/signup.php]");//底部第一张图片
if(null!=aEls && aEls.size()>=1){
Element aEL = aEls.get(0);//获取底部a标签
Element pBottom1 = aEL.parent();//获取底部a标签的父标签P
pBottom1.remove();//底部标签自己移除自己
} Elements imgElsBottom = parse.select("img[src=http://www.konvy.com/static/team/Banner/shipping%2024h.jpg]");//底部第二张图片
if(null!=imgElsBottom && imgElsBottom.size()>0){
Element imgBttom = imgElsBottom .get(0); //底部第二张图片
Element pBottom2 = imgBttom.parent();//底部第二张图片的父标签
pBottom2.remove();//底部第二张图片的父标签进行移除
} return parse.toString();
}

依赖:<dependency>
<groupId>org.jsoup</groupId>
<artifactId>com.springsource.org.jsoup</artifactId>
<version>1.5.2</version>
</dependency>
java解析HTML之神器------Jsoup的更多相关文章
- JSoup——用Java解析html网页内容
当需要从网页上获取信息时,需要解析html页面.筛选指定标签,并获取其值是必不可少的操作,解析html页面这方面的利器,Python有BeautifulSoup,Java一直没有好的工具,之前的Htm ...
- Atitit.html解析器的选型 jsoup nsoup ,java c# .net 版本
Atitit.html解析器的选型 jsoup nsoup ,java c# .net 版本 1. 框架选型的要求1 1.1. 文档多1 1.2. 跨平台1 2. html解析器特性:1 2.1. j ...
- java解析xml实例——获取天气信息
获取xml并解析其中的数据: package getweather.xml; import java.io.IOException; import java.util.HashMap; import ...
- java解析xml文件练习——通过应用包名获取应用图标即其他信息(基于魅族应用商店)
1.解析包名数据文件(txt文件),并生成包名数组: package jsouphtml; import java.io.BufferedReader; import java.io.File; im ...
- java解析xml的三种方法
java解析XML的三种方法 1.SAX事件解析 package com.wzh.sax; import org.xml.sax.Attributes; import org.xml.sax.SAXE ...
- atitit.java解析sql语言解析器解释器的实现
atitit.java解析sql语言解析器解释器的实现 1. 解析sql的本质:实现一个4gl dsl编程语言的编译器 1 2. 解析sql的主要的流程,词法分析,而后进行语法分析,语义分析,构建sq ...
- java 解析XML文档
Java 解析XML文档 一.解析XML文档方式: 1.DOM方式:将整个XML文档读取到内存中,按照XML文件的树状结构图进行解析. 2.SAX方式:基于事件的解析,只需要加载XML中的部分数据,优 ...
- Java 解析 XML
Java 解析 XML 标签: Java基础 XML解析技术有两种 DOM SAX DOM方式 根据XML的层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象 优点 ...
- JAVA解析XML的四种方式
java解析xml文件四种方式 1.介绍 1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准.DOM是以层次结构组织的节点或信息片断的集合.这 ...
随机推荐
- oracle基本查询
- 【Axure RP8.1】一款专业的快速原型设计工具
Axure RP是一款专业的快速原型设计工具.Axure(发音:Ack-sure),代表美国Axure公司:RP则是Rapid Prototyping(快速原型)的缩写.Axure RP是美国Axur ...
- 雷林鹏分享:jQuery EasyUI 数据网格 - 设置排序
jQuery EasyUI 数据网格 - 设置排序 本实例演示如何通过点击列表头来排序数据网格(DataGrid). 数据网格(DataGrid)的所有列可以通过点击列表头来排序.您可以定义哪列可以排 ...
- python 数据分类赋值
问题描述:在数据预处理时,往往需要对描述性数据进行分类赋值或对数据进行分级赋值. 首先,会想到用for循环,依次判断赋值: for n in range(len(data1)): print(n) i ...
- 20165309 《网络对抗技术》 Kali安装
20165309 <网络对抗技术> Kali安装 1. 目的要求 下载 安装 网络 共享 软件源 2. 主要步骤 下载系统镜像文件 进入Kali官网下载,我选择的是64位版本: 虚拟机设置 ...
- ArcGIS中KML转为shp文件
问题:如何将KML转为shp文件? 方法: 1.打开ArcMap -> ArcToolbox: 2.在ArcToolbox中选择“转换工具”-> “由KML转出” -> “KML转图 ...
- nigix反向代理
参考: https://www.cnblogs.com/yycc/p/8185748.html
- elasticSearch安装 Kibana安装 Sense安装
安装最新版本,安装6.*版本 先提示一个重要的事情,kibana新版本不需要安装Sense, 官方的是老版的Kibana才需要,我们现在用devTool http://localhost:5601/a ...
- markdown在线编辑插件mditor
官方地址 https://bh-lay.github.io/mditor/ ##使用方法 #1.页面添加dom ```javascript <textarea id="md_edito ...
- Python3 Tcp未发送/接收完数据即被RST处理办法
一.背景说明 昨天一个同事让帮忙写个服务,用于接收并返回他那边提交过来的数据,以便其查看提交的数据及格式是否正确. 开始想用django写个接口,但写接口接口名称就得是定死的,他那边只能向这接口提交数 ...