python文件的路径问题补充上一篇内容
上次的路径问题还没解决就被勒索病毒的木马器给搞了两周多, 拖拖拖到现在又开始纠结路径问题...还是学习能力不足啊...
补充一下路径问题的知识, 毕竟jupyter notebook跟IDE测试的时候有不同的结果, 是不是换个更好的IDE来测试避免这种基础问题比较好呢?
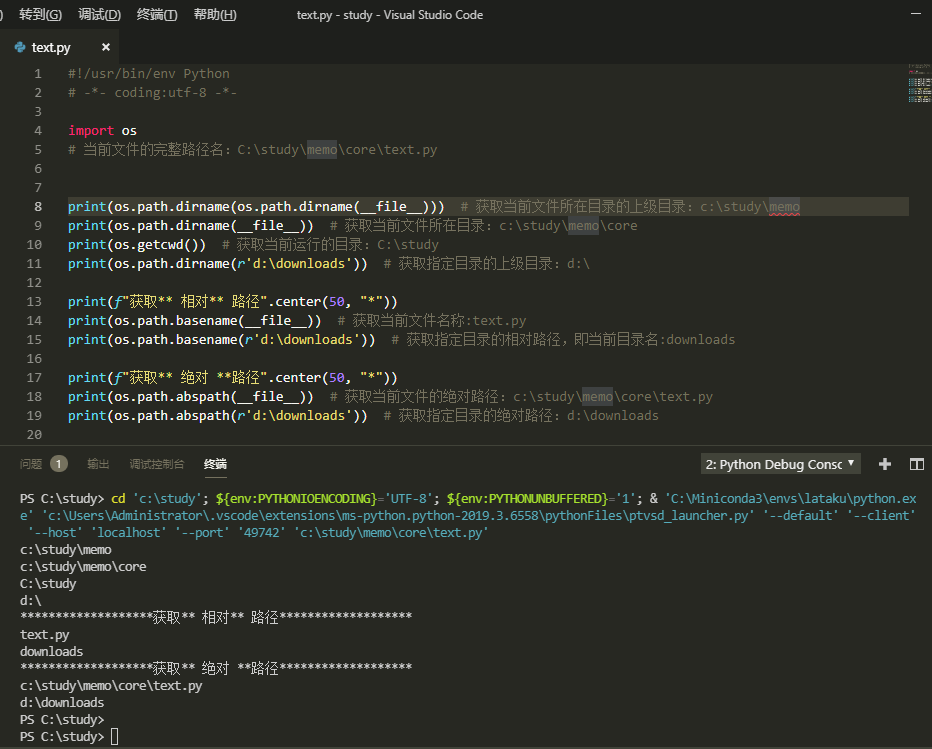
第一种
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import os
# 当前文件的完整路径名:C:\study\memo\core\text.py
print(os.path.dirname(os.path.dirname(__file__))) # 获取当前文件所在目录的上级目录:c:\study\memo
print(os.path.dirname(__file__)) # 获取当前文件所在目录:c:\study\memo\core
print(os.getcwd()) # 获取当前运行的目录:C:\study
print(os.path.dirname(r'd:\downloads')) # 获取指定目录的上级目录:d:\
print(f"获取** 相对** 路径".center(50, "*"))
print(os.path.basename(__file__)) # 获取当前文件名称:text.py
print(os.path.basename(r'd:\downloads')) # 获取指定目录的相对路径,即当前目录名:downloads
print(f"获取** 绝对 **路径".center(50, "*"))
print(os.path.abspath(__file__)) # 获取当前文件的绝对路径:c:\study\memo\core\text.py
print(os.path.abspath(r'd:\downloads')) # 获取指定目录的绝对路径:d:\downloads
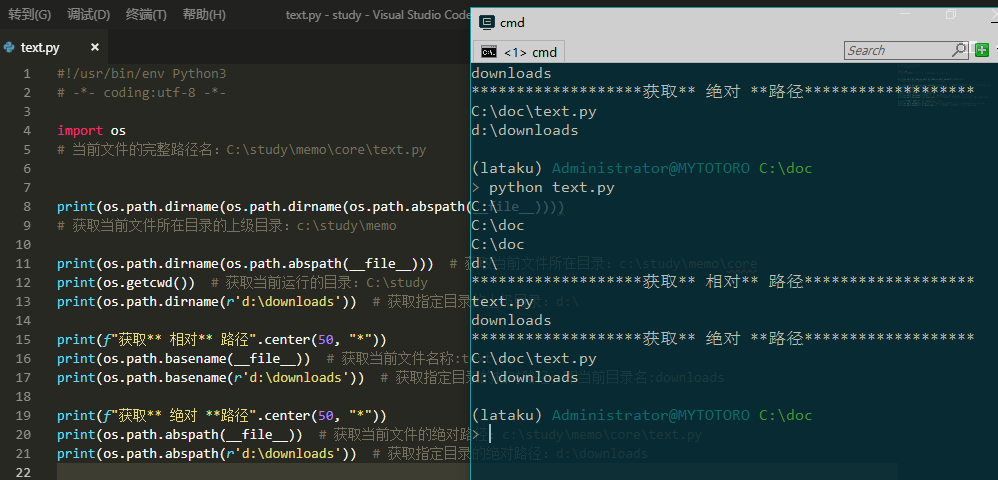
第二种, file前面加了个abspath
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import os
# 当前文件的完整路径名:C:\study\memo\core\text.py
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 获取当前文件所在目录的上级目录:c:\study\memo
print(os.path.dirname(os.path.abspath(__file__))) # 获取当前文件所在目录:c:\study\memo\core
print(os.getcwd()) # 获取当前运行的目录:C:\study
print(os.path.dirname(r'd:\downloads')) # 获取指定目录的上级目录:d:\
print(f"获取** 相对** 路径".center(50, "*"))
print(os.path.basename(__file__)) # 获取当前文件名称:text.py
print(os.path.basename(r'd:\downloads')) # 获取指定目录的相对路径,即当前目录名:downloads
print(f"获取** 绝对 **路径".center(50, "*"))
print(os.path.abspath(__file__)) # 获取当前文件的绝对路径:c:\study\memo\core\text.py
print(os.path.abspath(r'd:\downloads')) # 获取指定目录的绝对路径:d:\downloads
刚开始学习的时候常常会不清楚运行的路径,多测试一下多print一下没坏处
python文件的路径问题补充上一篇内容的更多相关文章
- python文件及路径管理函数
glob模块 说明: 1.glob是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,就类似于Windows下的文件搜索, 支持通配符操作 *.?.[] 这三个通配符,*代表0 ...
- python 文件和路径操作函数小结
1: os.listdir(path) //path为目录 功能相当于在path目录下执行dir命令,返回为list类型 print os.listdir('..') 2: os.path.walk( ...
- Python文件操作,with open as追加文本内容实例
最常见的读写操作 import re with open('/Users/Mr.Long/Desktop/data.txt', 'w') as f: f.write('hello world') 就这 ...
- 评论抓取:Python爬取微信在APPStore上的评论内容及星级
#完整程序如下: import requests import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_stat ...
- ie下获取上传文件全路径
ie下获取上传文件全路径,3.5之后的火狐是没法获取上传文件全路径的 /*获取上传文件路径*/ function getFilePath(obj) { var form = $(this).paren ...
- 初学Python——文件操作第二篇
前言:为什么需要第二篇文件操作?因为第一篇的知识根本不足以支撑基本的需求.下面来一一分析. 一.Python文件操作的特点 首先来类比一下,作为高级编程语言的始祖,C语言如何对文件进行操作? 字符(串 ...
- python-模块入门二(模块循环导入,区分python文件的两种用途,模块搜索路径,软件开发的目录规范)
一.模块的循环导入问题 run.py # import m1 # 第一次导入 m1.py # 错误示范 ''' print('正在导入m1') from m2 import y #第一次导入m2 x= ...
- python 全栈开发,Day29(昨日作业讲解,模块搜索路径,编译python文件,包以及包的import和from,软件开发规范)
一.昨日作业讲解 先来回顾一下昨日的内容 1.os模块 和操作系统交互 工作目录 文件夹 文件 操作系统命令 路径相关的 2.模块 最本质的区别 import会创建一个专属于模块的名字, 所有导入模块 ...
- python使用os.listdir和os.walk获得文件的路径
python使用os.listdir和os.walk获得文件的路径 目录 情况1:在一个目录下面只有文件,没有文件夹,这个时候可以使用os.listdir 情况2:递归的情况,一个目录下面既有目录 ...
随机推荐
- APICloud学习第二天——操作云数据库
//连接apicloud云数据库 var model=api.require('model'); model.config({ appId: 'A6008558346855', appKey: '60 ...
- canvans生成图片<p>标签文字不居中
尝试使用magin 0px auto ;width:100%解决.
- luogu 1291 概率期望递推
非常好的递推 公式啥的懒得写了,直接放链接哈哈哈https://www.luogu.org/problemnew/solution/P1291 #include<bits/stdc++.h> ...
- UE4网络同步属性笔记
GameMode只有服务端有,适合写游戏逻辑.PlayerController每个客户端拥有一个,并拥有主控权.GameState在服务端同步到全端. CLIENT生成的Actor对其有Authori ...
- iTOP-4418开发板Android 5.1/4.4丨Linux + Qt5.7丨Ubuntu12.04系统
核心板参数 尺寸:50mm*60mm 高度:核心板连接器组合高度1.5mm PCB层数:6层PCB沉金设计 4418 CPU:ARM Cortex-A9 四核 S5P4418处理器 1.4GHz 68 ...
- AB PLC首次IP地址如何分配
AB PLC首次IP地址如何分配,这里介绍的方法是针对CompactLogix和ControlLogix控制器 一.准备工作 AB PLC控制器一台,本文以5069-L330ER为例,将其通电: 笔记 ...
- C# 处理文件,视频,音频,压缩包下载
文章介绍了通过HttpWebRequest和HttpWebResponse实现视频下载的功能:首先HttpWebRequest类利用HTTP 协议和服务器交互,再由HttpWebResponse返回来 ...
- 谷歌浏览器安装json格式化插件
1.下载JsonView扩展程序压缩包 下载地址:https://github.com/gildas-lormeau/JSONView-for-Chrome 点击[Clone or download] ...
- Oracle SQL性能优化总结
1. SQL语句执行步骤 语法分析> 语义分析> 视图转换 >表达式转换> 选择优化器 >选择连接方式 >选择连接顺序 >选择数据的搜索路径 >运行“执 ...
- vue面试题总结
1.vue双向绑定的实现原理2.js的继承和原型链3.es6语法箭头函数和普通函数的区别 普通函数的this总是指向它的直接调用者. 在严格模式下,没找到直接调用者,则函数中的this是undefin ...