MapReduce过程<原创>
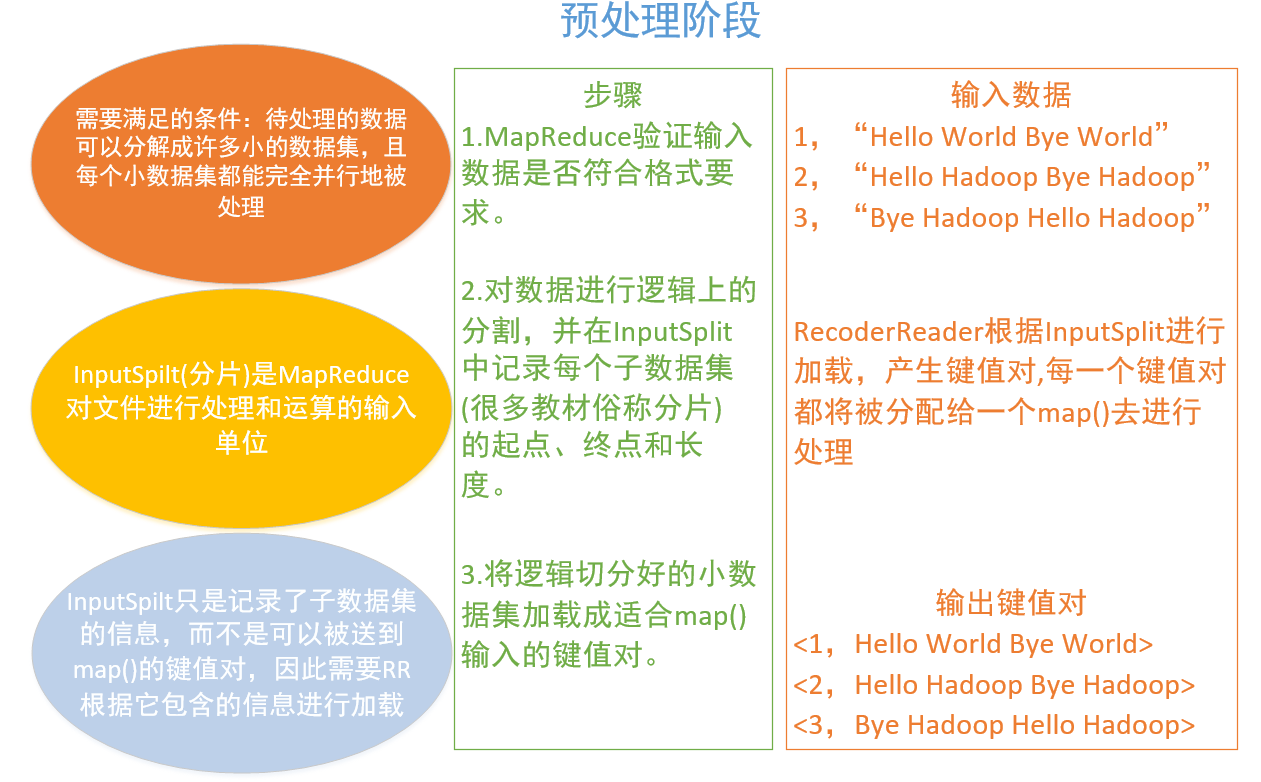
一、预处理阶段
二、Map阶段
一个Map任务被JobTracker(管家)分配到多个TaskTracker(弟弟)执行,如下图所示,弟弟的map()只负责拆分,虽然map()输出两个相同的键值对,但它并不会对两个重复的键值对进行合并,而且输出的键值对也是无序的,没有按照字母顺序排列。而这些工作都会交给Shuffle(洗牌)阶段去做。

三、Shuffle阶段
Shuffle阶段实际上并不是一个和Map阶段和Reduce阶段独立的阶段,实际上它分为Map端的Shuffle阶段和Reduce端的阶段,为了方便讨论,就把这个两个子阶段放在一起讨论,统称为Shuffle阶段。
(一)Map端的Shuffle阶段
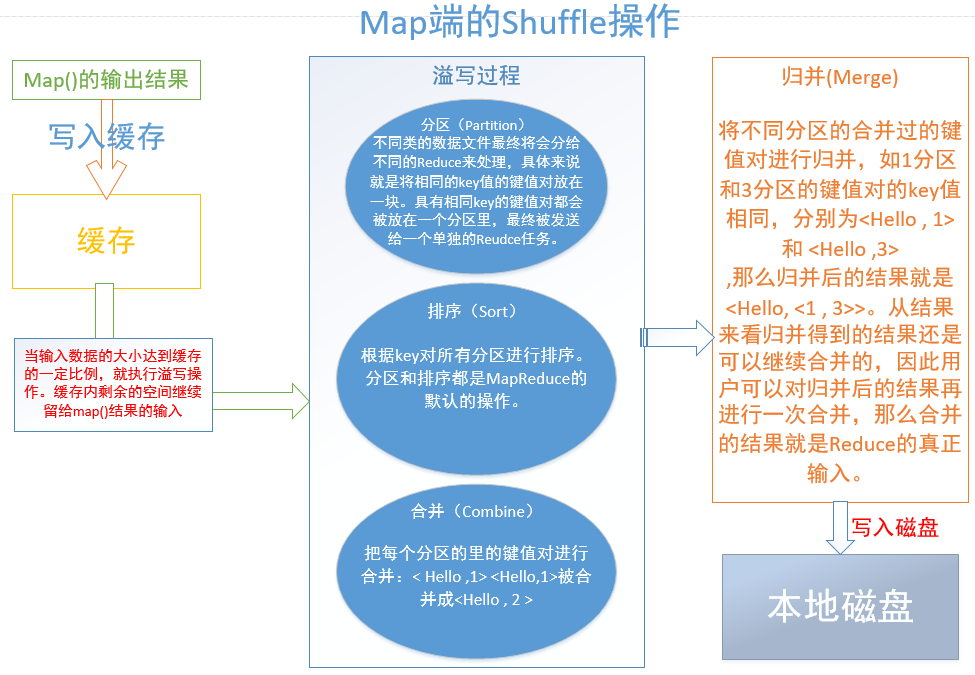
每个map()任务都会被分配一块缓存,对于每个map()的输出数据,不是直接写入磁盘,而是先写入缓存里,当缓存达到一定比例时对它进行溢写操作,将溢写好的数据进行归并(、合并)发送到本地磁盘,并清空该数据占用的缓存,还在执行的map()们可以继续不停地将结果写入缓存。之所以这样设计,是为了减少I/O消耗,节省了时间。
溢写,包括分区(Partiyion)、排序(Sort)、合并(Combine)。溢写过程,是在缓存中完成的。
看过巨佬的博客之后对错误的理解进行了更正:每个分区含有多个不同key值的键值对,而不是一个分区只含有一种key值对应的多个键值对。举例:
1分区: < Hello ,1> <Hello ,1 > <Hadoop ,1 > , 2分区:<World ,1 > <World ,1>
即key值为Hello的键值对全部被分到1分区,其他分区不会存在key值为Hello的键值对,而1分区除了Hello还有多个其他的key值的键值对存在。
合并(Combine)与归并(Merge)的区别:
合并是针对每个分区内部的键值对的操作,而归并是针对磁盘中的多个溢写文件的操作,将多个溢写文件归并成一个大的溢写文件。
对于两个键值对< a ,1 >和< a ,1>,合并的结果是 <a , 2 >:合并实际上就是在map端执行reduce的操作,是为了减少网络传输开销,但是并不是所有的情况都能使用合并操作,可通过调用job.setCombinerClass(MyReduce.class)设置这一操作;
而归并的结果是<a,<1,1>>,合并是不是默认MapReduce的默认操作,归并是默认操作。归并的结果是可以继续合并再作为最终结果发送到本地磁盘作为Reduce的输入的。
(二)Reduce端的Shuffle阶段
1.领取数据
Map端的Shuffle阶段将合并或归并好的数据发送到本地磁盘里。在Map任务开始后,Reduce会不断的通过RPC通信协议来询问JobTracker(管家),Map任务是否已经完成。JobTracker检测到一个Map任务完成后会通知相关的Reduce来领取属于自己的数据。一般系统中会存在多个Map机器,Reduce需要使用多线程同时从多个Map机器领取数据。
2.归并、输出
尽管每个map()都在之前进行过合并、归并处理,但当Reduce从多个Map机器中领取回数据后,Reduce机器的缓冲中又存在着相同的可以合并的键值对、具有相同key值的键值对也会被归并。在这个阶段,合并也不是默认的,需要用户自定义。和Map端的Shuffle阶段不同的是,当前阶段生成多个文件发送给Reduce阶段。
三、Reduce阶段
对不同分区的相同key对应的值进行相加,输出最后的结果。并写入到HDFS系统中,也就是写入磁盘。
一定要看:
巨佬博客(一看就懂系列):https://www.cnblogs.com/npumenglei/p/3631244.html
MapReduce过程<原创>的更多相关文章
- MapReduce过程(包括Shuffle)详解
首先,map的输入数据默认一个一个的键值对,键就是每一行首字母的偏移量,值就是每一行的值了. 然后每一个输入的键值对都会用我们定义的map函数去处理,这里用wordcount来举例的话就是,每一个键值 ...
- MapReduce过程详解(基于hadoop2.x架构)
本文基于hadoop2.x架构详细描述了mapreduce的执行过程,包括partition,combiner,shuffle等组件以及yarn平台与mapreduce编程模型的关系. mapredu ...
- Hadoop - MapReduce 过程
Hadoop - MapReduce 一.MapReduce设计理念 map--->映射 reduce--->归纳 mapreduce必须构建在hdfs之上的一种大数据离线计算框架 在线: ...
- MapReduce 过程详解
Hadoop 越来越火, 围绕Hadoop的子项目更是增长迅速, 光Apache官网上列出来的就十几个, 但是万变不离其宗, 大部分项目都是基于Hadoop common MapReduce 更是核心 ...
- WordCount示例深度学习MapReduce过程(1)
我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功.在终端中用命令创建一个文件夹,简单的向两个文件中各写入一段话,然后运行Hadoop,Wou ...
- 关于mapreduce过程中出现的错误:Too many fetch-failures
Reduce task启动后第一个阶段是shuffle,即向map端fetch数据.每次fetch都可能因为connect超时,read超时,checksum错误等原因而失败.Reduce task为 ...
- hadoop的mapreduce过程
http://www.cnblogs.com/sharpxiajun/p/3151395.html 下面我从逻辑实体的角度讲解mapreduce运行机制,这些按照时间顺序包括:输入分片(input s ...
- MapReduce过程详解及其性能优化
http://blog.csdn.net/aijiudu/article/details/72353510 废话不说直接来一张图如下: 从JVM的角度看Map和Reduce Map阶段包括: 第一读数 ...
- WordCount示例深度学习MapReduce过程
转自: http://blog.csdn.net/yczws1/article/details/21794873 . 我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测 ...
随机推荐
- spring cloud 实践坑点记录
用spring cloud 微服务框架有一段时间了有一些坑点在这里给大家记录一下希望大家用得着 1.当我们使用聚合性能监控的时候,我们采用 rabbitmq作为消息中间件来收集性能信息最后在使用Tur ...
- IntelliJ IDEA LicenseServer激活及使用
一.激活 IntelliJ IDEA下载地址:https://www.jetbrains.com/idea/download/#section=windows 原文地址:http://blog.csd ...
- vue项目,ie11 浏览器报 Promise 未定义的错误
报错: {description: "“Promise”未定义", message: "“Promise”未定义", name: "Referenc ...
- 转://Oracle not in查不到应有的结果(NULL、IN、EXISTS详解)
问题: 语句1 : Select * from table1 A where A.col1 not in ( select col1 from table2 B ) ...
- SQL模糊查询排序问题
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 需求描述 查询表中名字带指定关键字的数据 完全匹配放在第一位 前匹配放在第二位 ...
- P1460 健康的荷斯坦奶牛 Healthy(DFS)
思路:这道题还是用了小小的剪枝,这里要注意的是该题有很多中构建树的顺序,但是,在这众多顺序中不一定都能保证输出的方案字典序最小. 构建搜索树:如图构建 剪枝,emmm,看代码: #include< ...
- 【转】Xposed出现 java.lang.IllegalAccessError: Class ref in pre-verified class resolved to unexpected implementation
Xposed出现 java.lang.IllegalAccessError: Class ref in pre-verified class resolved to unexpected implem ...
- 003_生成器(generator)内部解析
#http://kb.cnblogs.com/page/87128/(未看完)
- 裸奔的智能插座:博联Broadlink SP2/SP mini的分析、破解
https://www.jianshu.com/p/028b10bc3dd1 智能设备的联动通常采用IFTTT的方式,但这种方式受限于官方软件提供的功能.想要自主地灵活控制,需要有官方SDK,或知道协 ...
- day25 Python
一.day24复习 class school: x=1 #__init__初始化函数,用来帮类实例化一个具体的对象 def __init__(self,name,addr): #前面的Name是一个需 ...