UTF8 UTF16 之间的互相转换
从UCS-2到UTF-8的编码方式如下(没有处理扩展面):
| UCS-2编码(16进制) | UTF-8 字节流(二进制) |
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
typedef unsigned long UTF32; /* at least 32 bits */
typedef unsigned short UTF16; /* at least 16 bits */
typedef unsigned char UTF8; /* typically 8 bits */
typedef unsigned int INT; /*
UCS-2编码 UTF-8 字节流(二进制)
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
*/ #define UTF8_ONE_START (0xOOO1)
#define UTF8_ONE_END (0x007F)
#define UTF8_TWO_START (0x0080)
#define UTF8_TWO_END (0x07FF)
#define UTF8_THREE_START (0x0800)
#define UTF8_THREE_END (0xFFFF) void UTF16ToUTF8(UTF16* pUTF16Start, UTF16* pUTF16End, UTF8* pUTF8Start, UTF8* pUTF8End)
{
UTF16* pTempUTF16 = pUTF16Start;
UTF8* pTempUTF8 = pUTF8Start; while (pTempUTF16 < pUTF16End)
{
if (*pTempUTF16 <= UTF8_ONE_END
&& pTempUTF8 + 1 < pUTF8End)
{
//0000 - 007F 0xxxxxxx
*pTempUTF8++ = (UTF8)*pTempUTF16;
}
else if(*pTempUTF16 >= UTF8_TWO_START && *pTempUTF16 <= UTF8_TWO_END
&& pTempUTF8 + 2 < pUTF8End)
{
//0080 - 07FF 110xxxxx 10xxxxxx
*pTempUTF8++ = (*pTempUTF16 >> 6) | 0xC0;
*pTempUTF8++ = (*pTempUTF16 & 0x3F) | 0x80;
}
else if(*pTempUTF16 >= UTF8_THREE_START && *pTempUTF16 <= UTF8_THREE_END
&& pTempUTF8 + 3 < pUTF8End)
{
//0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
*pTempUTF8++ = (*pTempUTF16 >> 12) | 0xE0;
*pTempUTF8++ = ((*pTempUTF16 >> 6) & 0x3F) | 0x80;
*pTempUTF8++ = (*pTempUTF16 & 0x3F) | 0x80;
}
else
{
break;
}
pTempUTF16++;
}
*pTempUTF8 = 0;
} void UTF8ToUTF16(UTF8* pUTF8Start, UTF8* pUTF8End, UTF16* pUTF16Start, UTF16* pUTF16End)
{
UTF16* pTempUTF16 = pUTF16Start;
UTF8* pTempUTF8 = pUTF8Start; while (pTempUTF8 < pUTF8End && pTempUTF16+1 < pUTF16End)
{
if (*pTempUTF8 >= 0xE0 && *pTempUTF8 <= 0xEF)//是3个字节的格式
{
//0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
*pTempUTF16 |= ((*pTempUTF8++ & 0xEF) << 12);
*pTempUTF16 |= ((*pTempUTF8++ & 0x3F) << 6);
*pTempUTF16 |= (*pTempUTF8++ & 0x3F); }
else if (*pTempUTF8 >= 0xC0 && *pTempUTF8 <= 0xDF)//是2个字节的格式
{
//0080 - 07FF 110xxxxx 10xxxxxx
*pTempUTF16 |= ((*pTempUTF8++ & 0x1F) << 6);
*pTempUTF16 |= (*pTempUTF8++ & 0x3F);
}
else if(*pTempUTF8 >= 0 && *pTempUTF8 <= 0x7F)//是1个字节的格式
{
//0000 - 007F 0xxxxxxx
*pTempUTF16 = *pTempUTF8++;
}
else
{
break;
}
pTempUTF16++;
}
*pTempUTF16 = 0;
} int main()
{
UTF16 utf16[256] = {L"你a好b吗234中国~!"};
UTF8 utf8[256]; UTF16ToUTF8(utf16, utf16+wcslen(utf16), utf8, utf8+256); memset(utf16, 0, sizeof(utf16)); UTF8ToUTF16(utf8, utf8 + strlen(utf8), utf16, utf16+256); return 0;
}
UTF-16 并不比 UTF-8 更受待见, 只是 Windows 默认使用 UTF-16 而已, 所以不得不在它们之间做转换(如果你还在使用非 Unicode 编码, 那你已经是受到微软的毒害了)
当然, 万恶的微软还是给出了更简单的方法的, 那就是下面的两个函数:
WideCharToMultiByte
将UTF-16(宽字符)字符串映射到新的字符串。新的字符串不一定来自多字节字符集。(那你取这个名字是闹哪样? 多字节字符集是什么鬼??? 你怎么不去屎)
https://msdn.microsoft.com/en-us/library/windows/desktop/dd374130(v=vs.85).aspx
MultiByteToWideChar
将字符串映射到UTF-16(宽字符)字符串。字符串不一定来自多字节字符集。
https://msdn.microsoft.com/en-us/library/windows/desktop/dd319072(v=vs.85).aspx
程序: 将 UTF-16 编码的字符串转换为 UTF-8 编码, 并在控制台输出
#include <Windows.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h> void use(const char *utf8str) {
system("Pause");
system("chcp 65001");
if (utf8str == NULL) {
printf("NULL\n");
return;
}
printf("%s\n", utf8str);
} char *utf16to8(const wchar_t *str) {
if (str == NULL) {
return NULL;
}
int cBuf = 0; // 缓冲区大小
// 计算缓冲区需要的大小, 如果函数成功, 则返回值至少是 1 (UTF-8以0x00结尾)
if (cBuf = WideCharToMultiByte(
CP_UTF8,
0,
str,
-1,
NULL,
0,
NULL,
NULL), !cBuf ){
// 计算失败
fprintf(stderr, "计算内存失败!");
return NULL;
}
printf("缓冲区大小 %d .\n", cBuf);
char *buf = NULL; // 指向缓冲区
buf = (char *)malloc(cBuf); // 分配缓冲区
if (!WideCharToMultiByte(
CP_UTF8,
0,
str,
-1,
buf,
1024,
NULL,
NULL) ){
fprintf(stderr, "转换失败!\n");
return NULL;
}
// 返回缓冲区地址
return buf;
} void run() {
const wchar_t *str = L"Hello你好我的朋友!";
char *utf8str = utf16to8(str);
use(utf8str);
free(utf8str);
} int main(int argc, char* argv[]) {
run();
system("Pause");
return EXIT_SUCCESS;
}
Output如下------>
缓冲区大小 25 .
请按任意键继续. . .
Active code page: 65001
Hello你好我的朋友!
Press any key to continue . . .
上面这个函数调用了两次 WideCharToMultiByte(), 第一次是计算转换所需的空间, 第二次开始转换(It's stupid!)
那么依葫芦画瓢, 你现在可以将 UTF-8 -> UTF16了吗?
补两张图

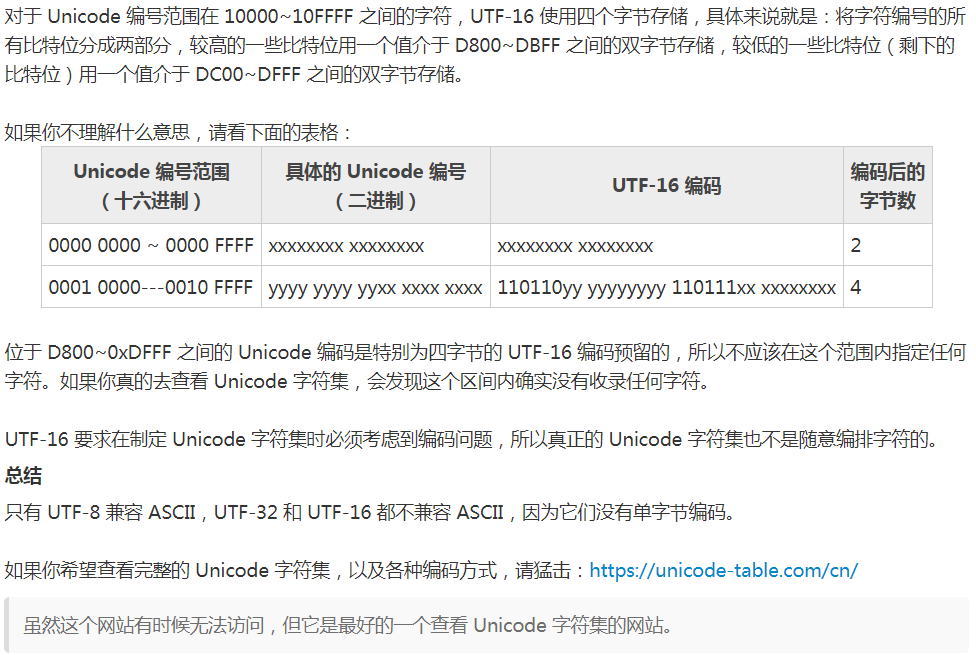
最终版本:
wchar_t *
utf8to16(const char *str) {
if (str == NULL) return L"(null)";
// 计算缓冲区需要的大小, 如果函数成功, 则返回 UTF-8 字符数量, 所以无法确定具体字节数
int cBuf = MultiByteToWideChar(CP_UTF8, 0, str, -1, NULL, 0);
if (cBuf == 0) return L"(null)";
wchar_t *buf = malloc(cBuf * 4);
if (cBuf != MultiByteToWideChar(CP_UTF8, 0, str, -1, buf, cBuf)) return L"(null)";
return buf;
} char *
utf16to8(const wchar_t *str) {
if (str == NULL) return "(null)";
// 计算缓冲区需要的大小, 如果函数成功, 则返回具体字节数, 所以 cBuf 至少是 1 (UTF-8以0x00结尾)
int cBuf = WideCharToMultiByte(CP_UTF8, 0, str, -1, NULL, 0, NULL, NULL);
if (cBuf < 1) return "(null)";
char *buf = malloc(cBuf); // 分配缓冲区
if (cBuf != WideCharToMultiByte(CP_UTF8, 0, str, -1, buf, 1024, NULL, NULL)) return "(null)";
return buf;
}
UTF8 UTF16 之间的互相转换的更多相关文章
- (转) Unicode(UTF-8, UTF-16)令人混淆的概念
原文地址:http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html 为啥需要Unicode 我们知道计算机其实挺笨的,它只认识010 ...
- Unicode(UTF-8, UTF-16)令人混淆的概念(转)
文章转自http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html (http://swiftlet.net/archives/cat ...
- 关于编码:Unicode/UTF-8/UTF-16/UTF-32
关于编码,绕不开下面这些概念 ①Unicode/UTF-8/UTF-16/UTF-32 ②大小端字节序(big-endian/little-endian) ③BOM(Byte Order Mark) ...
- Unicode(UTF-8, UTF-16)令人混淆的概念----我看完了 不错
来自:http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html ---------------------------------- ...
- 【转】Unicode(UTF-8, UTF-16)令人混淆的概念
参考地址:http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html Java中,char类型用UTF-16编码描述一个代码单元 为啥 ...
- 细说:Unicode, UTF-8, UTF-16, UTF-32, UCS-2, UCS-4
1. Unicode与ISO 10646 全世界很多个国家都在为自己的文字编码,并且互不想通,不同的语言字符编码值相同却代表不同的符号(例如:韩文编码EUC-KR中“한국어”的编码值正好是汉字编码GB ...
- Unicode 字符集及UTF-8 UTF-16编码
很久以前发在他处的一篇博文,今天翻出来重新整理了一下 Unicode 字符集 共分为 17 个平面(plane), 分别对应 U+xx0000 - U+xxFFFF 的 code points, 其中 ...
- 从字节理解Unicode(UTF8/UTF16)
如果你不知道或者不了解什么是Unicode/UTF8/UTF16,请详细阅读这篇文章(这也是这篇博文的先决条件): 学点编码知识又不会死:Unicode的流言终结者和编码大揭秘 但是如果你看完以上文章 ...
- 一句话理解字符编码(Unicode ,UTF8,UTF16)
Unicode和ASCII码属于同一级别的,都是字符集,字符集规定从1到这个字符集的最大范围每个序号都各表示什么意思.比如ASCII字符集中序号65表示"A". 那接下来的UTF8 ...
随机推荐
- input type=file上传控件老问题
// 1.用INPUT控制上传文件时,点击INPUT控件出现文件选择框. // 2.如果在手机上使用时,一般不会出现这种较丑的 // 3.于是就自然想到将控件隐藏,然后用一个按钮代替,点击按钮时在函数 ...
- LVS搭建负载均衡(一)NAT模型
应用场景:LVS配置负载均衡方式之一:nat 测试环境: 测试步骤: 1. 在主机lvs上安装ipvsadm lvs~]# yum install ipvsadm -y lvs~]# ipvsadm ...
- Codeforces Round #516 (Div. 2)D. Labyrinth(BFS)
题目链接:http://codeforces.com/contest/1064/problem/D 题目大意:给你一个n*m的图,图中包含两种符号,'.'表示可以行走,'*'表示障碍物不能行走,规定最 ...
- 牛客网Wannafly挑战赛25A 因子(数论 素因子分解)
链接:https://www.nowcoder.com/acm/contest/197/A来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 262144K,其他语言5242 ...
- Spring注解方式实现任务调度
原文:http://docs.spring.io/spring/docs/4.0.1.BUILD-SNAPSHOT/javadoc-api/ 注解类型:EnableScheduling @Target ...
- 点击a标签不跳转的办法
方法1: <a href="http://www.baidu.com" onclick="return false"></a> 方法2: ...
- 对PDF的操作
PDF是个常见的格式,当我们需要对PDF做操作时,可以主要利用PDFbox和itext.这里主要介绍PDfbox,itext自己去 查找资料.添加pom配置. <dependency> & ...
- PHP中empty,is_null,isset的区别
有时候分不清这几个的区别,特此记录,以备不时之需 isset 判断变量是否已存在 empty 判断变量是否为空或为0 is_null 判断变量是否为NULL 变量 empty is_null isse ...
- 【译】12. Java反射——类的动态加载和重新加载
原文地址:http://tutorials.jenkov.com/java-reflection/dynamic-class-loading-reloading.html 博主最近比较忙,争取每周翻译 ...
- Ubuntu: Windows Help Tools For Ubuntu
Virtual Box https://www.virtualbox.org/wiki/Linux_Downloads 装不上Wine时直接装虚拟机吧.RTX真是个坑爹的东西,找不到替代的客户端 迅雷 ...