Linux虚拟内存(swap)调优篇-“swappiness”,“vm.dirty_background_ratio”和“vm.dirty_ratio”
Linux虚拟内存(swap)调优篇-“swappiness”,“vm.dirty_background_ratio”和“vm.dirty_ratio”
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
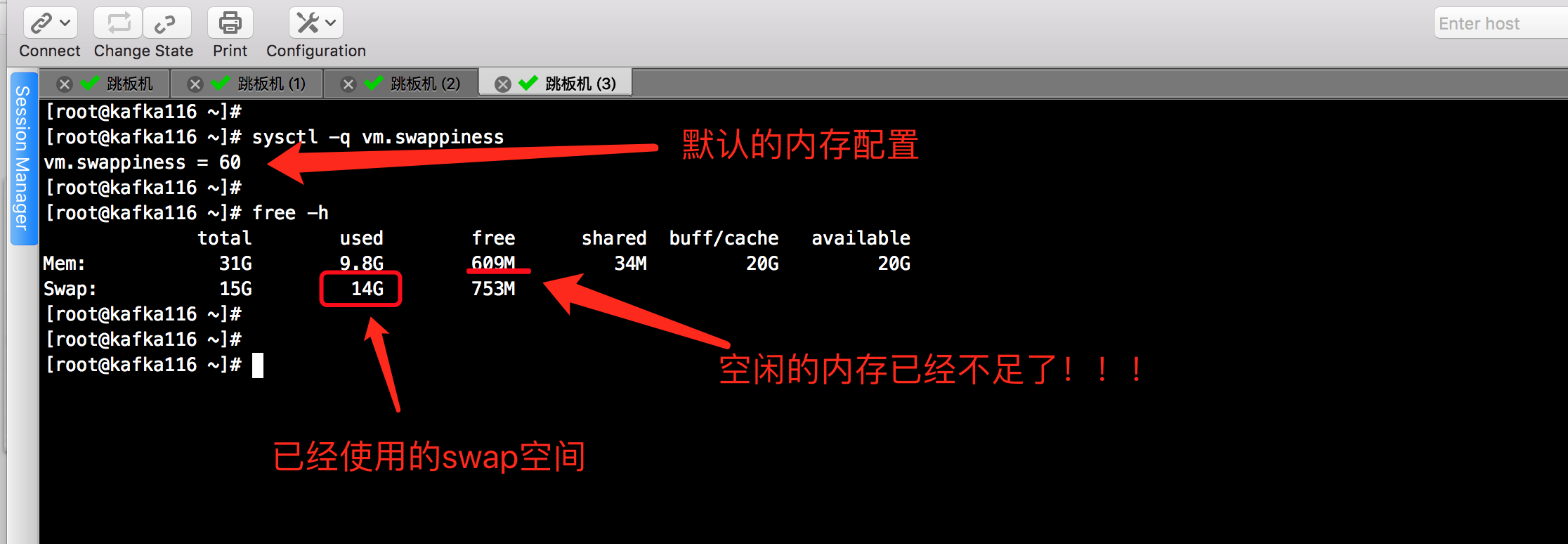
我的kafka集群在上线一段时间后,发现内存使用达到峰值时系统开始使用swap。在swap的过程中系统性能会有所下降,表现为较大的服务延迟。对这种情况,可以通过调节swappiness内核参数降低系统对swap的使用,从而避免不必要的swap对性能造成的影响。接下来,我们就一起学习一下如何调优该参数吧!
一.创建交换分区
1>.什么是虚拟内存
如果物理内存不够用时,可以将那些最近很少使用的页面数据(Page)置换出去,即切换到硬盘上,但是要注意的是内存文件的格式和硬盘中文件的格式是不一样的,所以这个分区必须格式化成跟内存兼容的模式不能转换成文件的格式。以便把内存的page直接存入这个分区,方便内存直接调用。而这个页面(page)数据对于32位的操作系统一个page大概是4K左右,对于64位操作系统这个page大小是可变的,4k-2M的大小都是比较常见的。事实上到底能使用多大的页面(page)取决于CPU而不取决于内存哟!这就是虚拟内存的概念。在linux上我们称之为交换分区。记住,虚拟内存必须是一个单独的分区。
2>.虚拟内存能代替物理内存运行程序吗?
答案是否定的,只是使用虚拟内存暂时保存数据,而不是代替物理内存运行程序。
3>.虚拟内存的作用
当运行某个大程序、大游戏,需要的内存超过空闲内存但小于物理内存总量时,会暂时把内存里这些数据放到磁盘上的虚拟内存里,空出物理内存运行游戏。等退出游戏后,又会把虚拟内存里的东西读出来,放回物理内存。所以,虚拟内存,并不是用来虚拟物理内存的,而是暂存数据的。如果对内存的需求大于物理内存总量,那虚拟内存设多大都不管用。电脑内存太低,根本的方法还是增加物理内存,才能流畅。虚拟内存机制上就不管用,即使管用,比物理内存低100倍的速度,也管不上什么实际的作用。所以,虚拟内存大了是没用的,反而白占用磁盘空间。
4>.交换分区常用的参数介绍
交换分区:
mkswap 格式化为虚拟内存
-L label 指定卷标
swapon 启动虚拟内存
-a 启动所有的虚拟分区
-p:指定优先级
swapoff 关闭虚拟内存
更多参数请参考man mkswap
5>.案例实操-创建交换分区的步骤
[root@yinzhengjie ~]# fdisk /dev/sdb #对第二块硬盘进行分区调整 WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u'). Command (m for help): p #查看当前分区情况 Disk /dev/sdb: 10.7 GB, bytes
heads, sectors/track, cylinders
Units = cylinders of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk identifier: 0x8614a108 Device Boot Start End Blocks Id System
/dev/sdb1 + Linux
/dev/sdb2 Linux
/dev/sdb3 Linux
/dev/sdb4 + Extended
/dev/sdb5 Linux
/dev/sdb6 + Linux #我想讲第6个分区弄成交换分区。 Command (m for help): t #调整分区ID
Partition number (-): #选择分区编号为6
Hex code (type L to list codes): L #查看分区类型所对应的ID号,我们发现“”就是交换分区的编号 Empty NEC DOS Minix / old Lin bf Solaris
FAT12 Plan Linux swap / So c1 DRDOS/sec (FAT-
XENIX root 3c PartitionMagic Linux c4 DRDOS/sec (FAT-
XENIX usr Venix OS/ hidden C: c6 DRDOS/sec (FAT-
FAT16 <32M PPC PReP Boot Linux extended c7 Syrinx
Extended SFS NTFS volume set da Non-FS data
FAT16 4d QNX4.x NTFS volume set db CP/M / CTOS / .
HPFS/NTFS 4e QNX4.x 2nd part Linux plaintext de Dell Utility
AIX 4f QNX4.x 3rd part 8e Linux LVM df BootIt
AIX bootable OnTrack DM Amoeba e1 DOS access
a OS/ Boot Manag OnTrack DM6 Aux Amoeba BBT e3 DOS R/O
b W95 FAT32 CP/M 9f BSD/OS e4 SpeedStor
c W95 FAT32 (LBA) OnTrack DM6 Aux a0 IBM Thinkpad hi eb BeOS fs
e W95 FAT16 (LBA) OnTrackDM6 a5 FreeBSD ee GPT
f W95 Ext'd (LBA) 55 EZ-Drive a6 OpenBSD ef EFI (FAT-12/16/
OPUS Golden Bow a7 NeXTSTEP f0 Linux/PA-RISC b
Hidden FAT12 5c Priam Edisk a8 Darwin UFS f1 SpeedStor
Compaq diagnost SpeedStor a9 NetBSD f4 SpeedStor
Hidden FAT16 < GNU HURD or Sys ab Darwin boot f2 DOS secondary
Hidden FAT16 Novell Netware af HFS / HFS+ fb VMware VMFS
Hidden HPFS/NTF Novell Netware b7 BSDI fs fc VMware VMKCORE
AST SmartSleep DiskSecure Mult b8 BSDI swap fd Linux raid auto
1b Hidden W95 FAT3 PC/IX bb Boot Wizard hid fe LANstep
1c Hidden W95 FAT3 Old Minix be Solaris boot ff BBT
1e Hidden W95 FAT1
Hex code (type L to list codes): #设置该分区的标号
Changed system type of partition to (Linux swap / Solaris) Command (m for help): P #查看当前分区情况 Disk /dev/sdb: 10.7 GB, bytes
heads, sectors/track, cylinders
Units = cylinders of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk identifier: 0x8614a108 Device Boot Start End Blocks Id System
/dev/sdb1 + Linux
/dev/sdb2 Linux
/dev/sdb3 Linux
/dev/sdb4 + Extended
/dev/sdb5 Linux
/dev/sdb6 + Linux swap / Solaris Command (m for help): W #保存并退出
The partition table has been altered! Calling ioctl() to re-read partition table.
Syncing disks.
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# fdisk -l /dev/sdb #查看分区信息 Disk /dev/sdb: 10.7 GB, bytes
heads, sectors/track, cylinders
Units = cylinders of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk identifier: 0x8614a108 Device Boot Start End Blocks Id System
/dev/sdb1 + Linux
/dev/sdb2 Linux
/dev/sdb3 Linux
/dev/sdb4 + Extended
/dev/sdb5 Linux
/dev/sdb6 + Linux swap / Solaris
[root@yinzhengjie ~]#
调整分区为交换分区(swap)格式
[root@yinzhengjie ~]# kpartx -af /dev/sdb
[root@yinzhengjie ~]# partx -a /dev/sdb #重读分区表信息,其实也可以不用敲击这些命令的如果你是一块新硬盘的话。
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
BLKPG: Device or resource busy
error adding partition
[root@yinzhengjie ~]#
用partx 重读一下分区表,避免系统未识别最新分区信息。
[root@yinzhengjie ~]# mkswap /dev/sdb6 #将分区格式化成swap格式
Setting up swapspace version , size = KiB
no label, UUID=41687bb2-c775-489c-9b32-1e4be73c233b #看见没有,这里是“no label”,是因为我没有定义卷标名。
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# mkswap -L myswap /dev/sdb6 #用-L参数定义一个卷标名。
Setting up swapspace version , size = KiB
LABEL=myswap, UUID=0553b99a-ee75--8eda-70c591206467 #看见没,“LABEL=myswap”这就是我定义的卷标名称。
[root@yinzhengjie ~]#
用mkswap定义卷标名称
[root@yinzhengjie ~]# cat /proc/meminfo | grep "^S" #查看当前交换分区大小
SwapCached: kB
SwapTotal: kB #目前交换分区大小为2G
SwapFree: kB #表示空闲交换分区大小
Shmem: kB
Slab: kB
SReclaimable: kB
SUnreclaim: kB
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# swapon /dev/sdb6 #启用我们已经格式化好的交换分区“/dev/sdb”
[root@yinzhengjie ~]# cat /proc/meminfo | grep "^S" #再次查看当前交换分区大小
SwapCached: kB
SwapTotal: kB #我们发现交换分区大小变大了2G
SwapFree: kB
Shmem: kB
Slab: kB
SReclaimable: kB
SUnreclaim: kB
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# swapoff /dev/sdb6 #关闭交换分区“/dev/sdb”
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# cat /proc/meminfo | grep "^S" #验证是否关闭成功
SwapCached: kB
SwapTotal: kB #发现的确是少了2G的空间
SwapFree: kB
Shmem: kB
Slab: kB
SReclaimable: kB
SUnreclaim: kB
[root@yinzhengjie ~]#
swapon和swapoff的用法展示
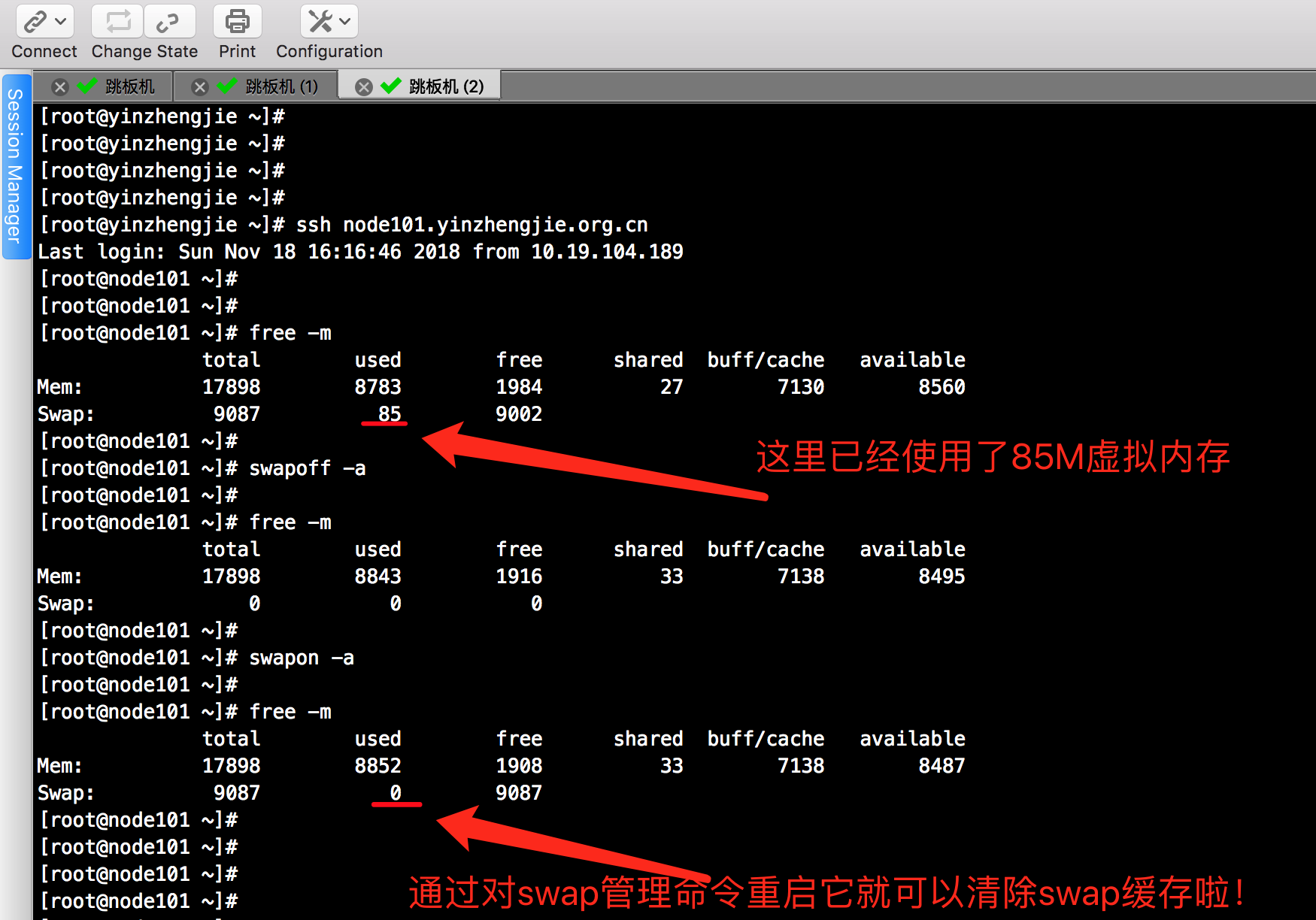
6>.Linux清除swap方法
想要了解更多关于文件系统的知识,详情请参考:https://www.cnblogs.com/yinzhengjie/p/6840563.html。
7>.swap分区使用说明
我本人并不推荐大家使用swap分区,因为它会降低服务器性能。 早期由于工业原因内存相对较贵,因此很多软件在设计之初都考虑尽可能的使用磁盘来代替内存,但是磁盘的I/O性能要和内存的I/O性能完全是天壤之别。比如在大数据领域Hadoop的一个MapReduce组件,该计算框架就尽可能使用磁盘,这是导致它计算速度很慢的一个原因,这也是为什么后来Spark和Flink崛起埋下伏笔。 因此,在生产环境中我们应该尽量禁用虚拟内存,比如阿里云的服务器默认就是禁用虚拟内存的,我在生产环境中也是直接禁用虚拟内存的。但有的服务器内存相对较小,比如8G,担心程序发生OOM.于是为了留一手才被迫使用虚拟内存。 如果非要使用虚拟内存建议参考以下几点:
()尽可能使用较块的设备,比如固态硬盘;
()如果使用磁盘建议使用扇区靠外的分区,这样在查找数据时速度相对较块;
()生产环境中虚拟磁盘不建议超过8G;
二.swappiness参数在内存与交换分区之间优化作用
swappiness的值的大小对如何使用swap分区是有着很大的联系的。先前,人们建议把vm.swapiness设置为0,它意味着“除非发生内存益处,否则不要进行内存交换”。直到Linux内核3.5-rcl版本发布,这个值的意义才发生了变化。这个变化被一直到其他的发行版本上,包括RedHat企业版内核2.6.32-303。在发生变化之后,0意味着“在任何情况下都不要发生交换”。所以现在建议把这个值设置为1。swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。
1>.linux的swappiness参数的默认设置为60([root@yinzhengjie ~]# cat /proc/sys/vm/swappiness)
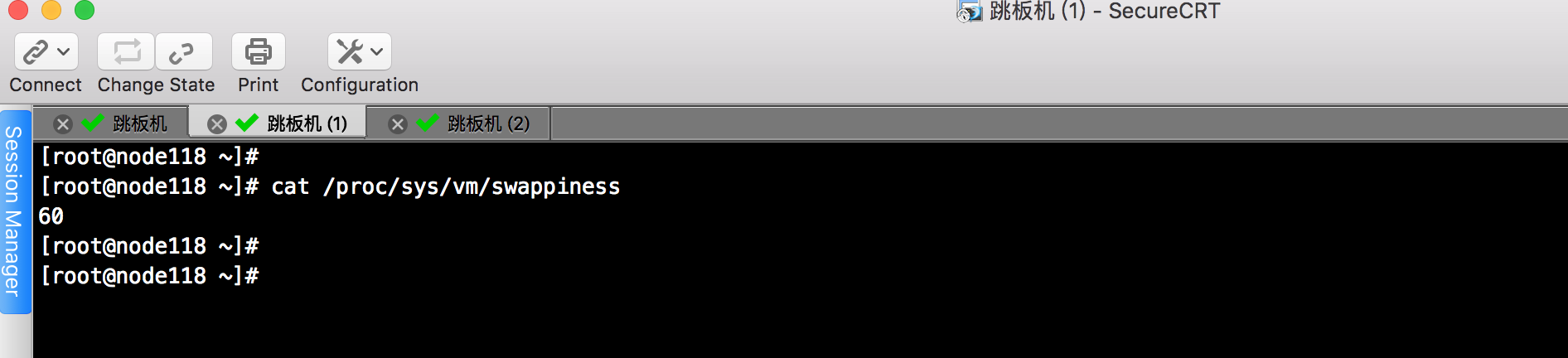
也就是说,你的内存在使用到100-60=40%的时候,就开始出现有交换分区的使用。大家知道,内存的速度会比磁盘快很多,这样子会加大系统io,同时造的成大量页的换进换出,严重影响系统的性能,所以我们在操作系统层面,要尽可能使用内存,对该参数进行调整。
2>.临时调整swappiness的方法([root@yinzhengjie ~]# sysctl vm.swappiness=1)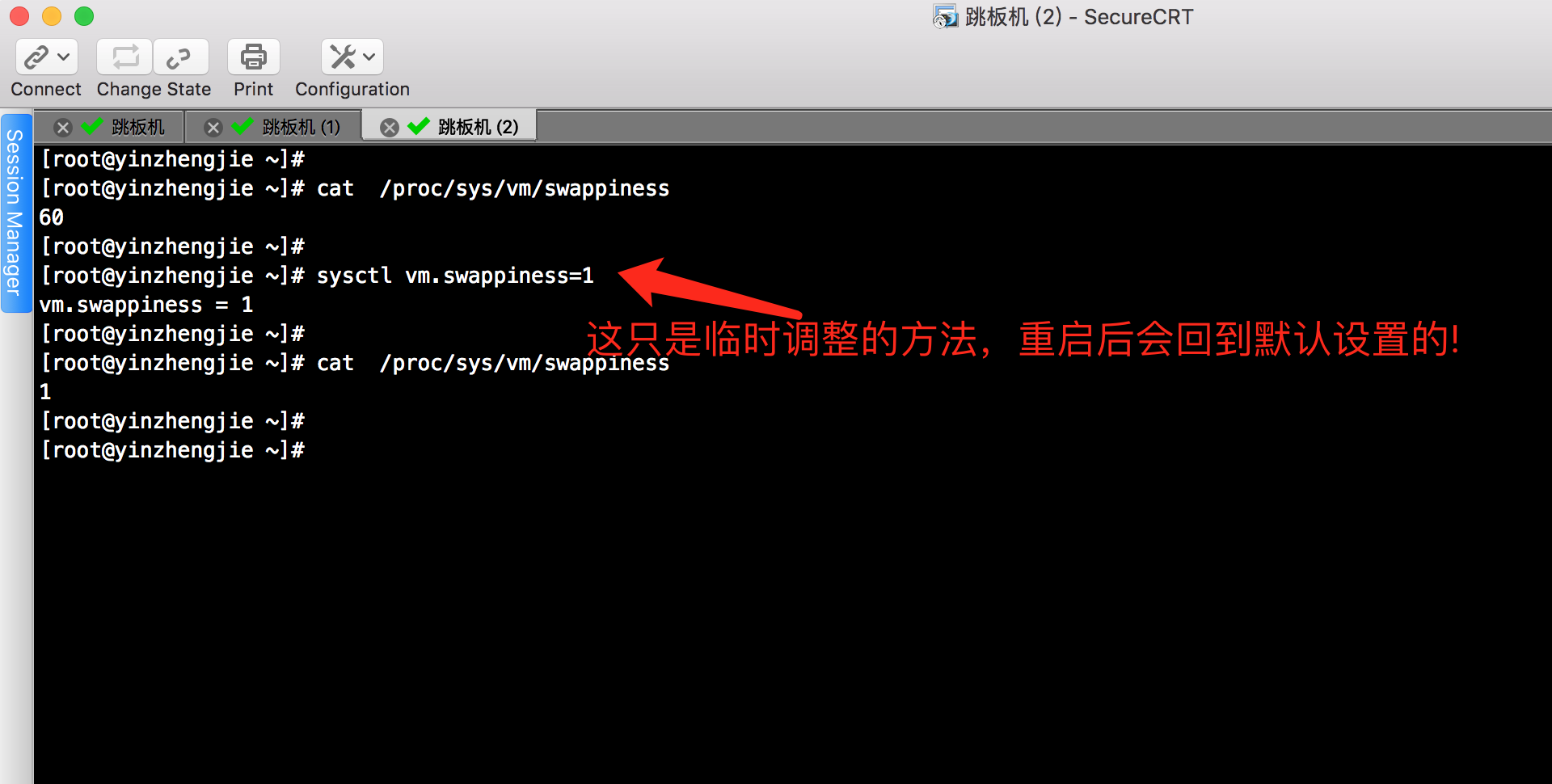
3>.永久调整swappiness的方法([root@yinzhengjie ~]# echo "vm.swappiness=1" >> /etc/sysctl.conf)
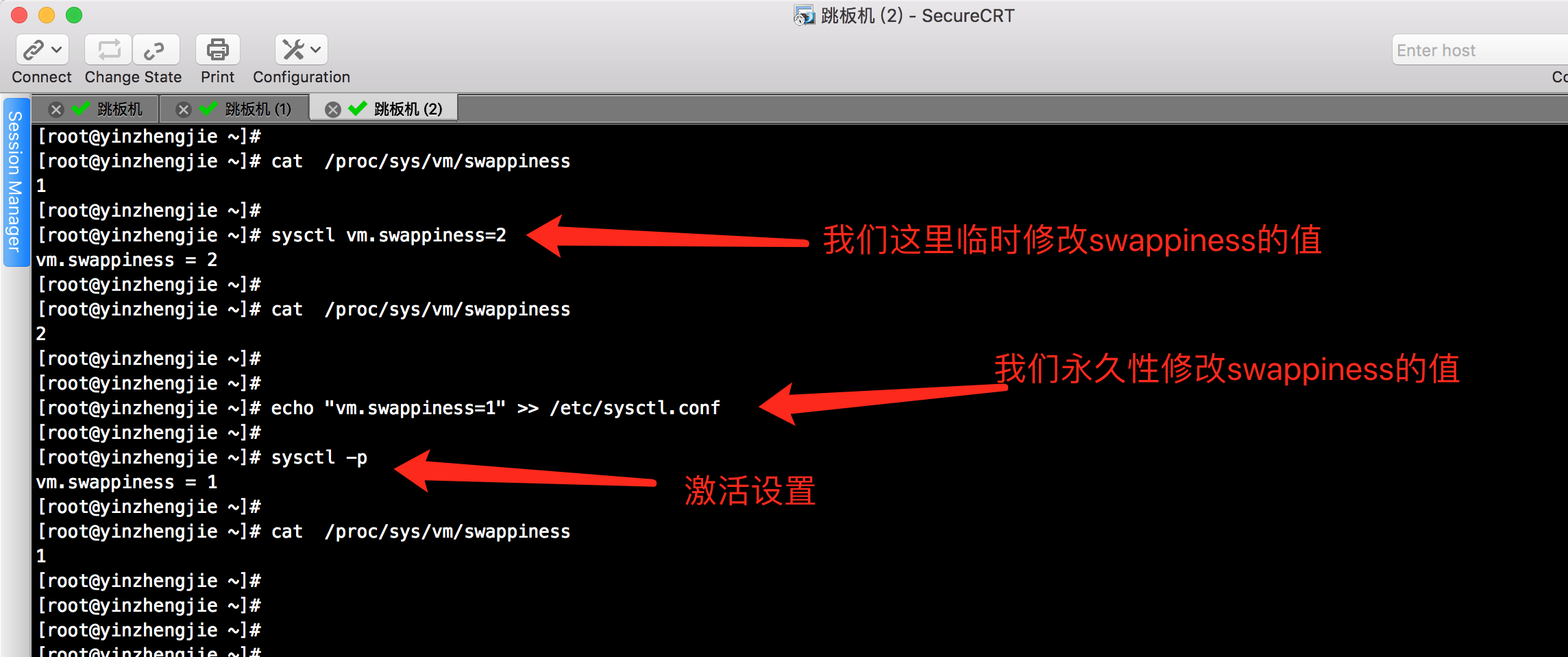
在linux中,可以通过修改swappiness内核参数,降低系统对swap的使用,从而提高系统的性能。简单地说这个参数定义了系统对swap的使用倾向,默认值为60,值越大表示越倾向于使用swap。不推荐设为0,因为这样做会对3.5以上的kernel禁止对swap的使用,我推荐打击设置一个较小对值,比如1,它只是最大限度地降低了使用swap的可能性。
4>.查看swappiness参数的当前设置

三.使用vm.dirty_ratio和vm.dirty_background_ratio更好的Linux磁盘缓存和性能
1>.脏页对概念
脏页是linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
2>.相关参数解释
[root@yinzhengjie ~]# sysctl -a | grep dirty
vm.dirty_background_bytes =
vm.dirty_background_ratio =
vm.dirty_bytes =
vm.dirty_expire_centisecs =
vm.dirty_ratio =
vm.dirty_writeback_centisecs =
[root@yinzhengjie ~]# vm.dirty_background_ratio :
是内存可以填充“脏数据”的百分比。这些“脏数据”在稍后是会写入磁盘的,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。举一个例子,我有32G内存,那么有3.2G的内存可以待着内存里,超过3.2G的话就会有后来进程来清理它。 vm.dirty_ratio:
是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值。如果脏数据超过这个数量,新的IO请求将会被阻挡,直到脏数据被写进磁盘。这是造成IO卡顿的重要原因,但这也是保证内存中不会存在过量脏数据的保护机制。 vm.dirty_background_bytes和vm.dirty_bytes是
指定这些参数的另一种方法。如果设置_bytes版本,则_ratio版本将变为0,反之亦然。 vm.dirty_expire_centisecs :
指定脏数据能存活的时间。在这里它的值是30秒。当 pdflush/flush/kdmflush 进行起来时,它会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。 vm.dirty_writeback_centisecs:
指定多长时间 pdflush/flush/kdmflush 这些进程会起来一次。
以上说明饮用自:https://blog.csdn.net/csCrazybing/article/details/78127308
3>.调整内核对脏页对处理方式可以让我们从中获益
脏页会被冲刷到磁盘上,调整内核对脏页的处理方式可以让我们从中获益。Kafka依赖I/O性能为生产者提供了快速的响应。这就是为什么日志片段一般要保存在快速磁盘上,不管是单个快速磁盘(如SSD)还是具有NVRAM缓存的磁盘子系统(如RAID)。这样一来,在后台刷新进程将脏页写入磁盘之前,可以减少脏页的数量,这个可以通过vm.dirty_backgroud_ratio设置为小于10的值来实现。改值指的是系统内存的百分比,大部分情况下设置为5就可以来。它不应该被设置为0,因为那样会促使内核频繁地刷新页面,从而降低内核为底层设备的磁盘写入提供缓冲的能力。
通过设置vm.dirty_ratio参数可以增加被内核进程刷新到磁盘之前的脏页数量,可以将它设置为大于20的值(这也是系统内存的百分比),这个值可设置的范围很广,60~80是个比较合理的区间。不过调整这个参数会带来一些风险,包括未刷新磁盘操作的数量和同步刷新引起的长时间I/O等待。如果篡改参数设置了较高的值,建议启用Kafka的复制功能,避免因系统崩溃造成数据丢失。
为了给这些参数设置合适的值,最好是在Kafka集群运行期间检查脏页的数量,不管是在生产环境还是在模拟环境。可以在“/proc/vmstat”文件里查看当前脏页的数量。
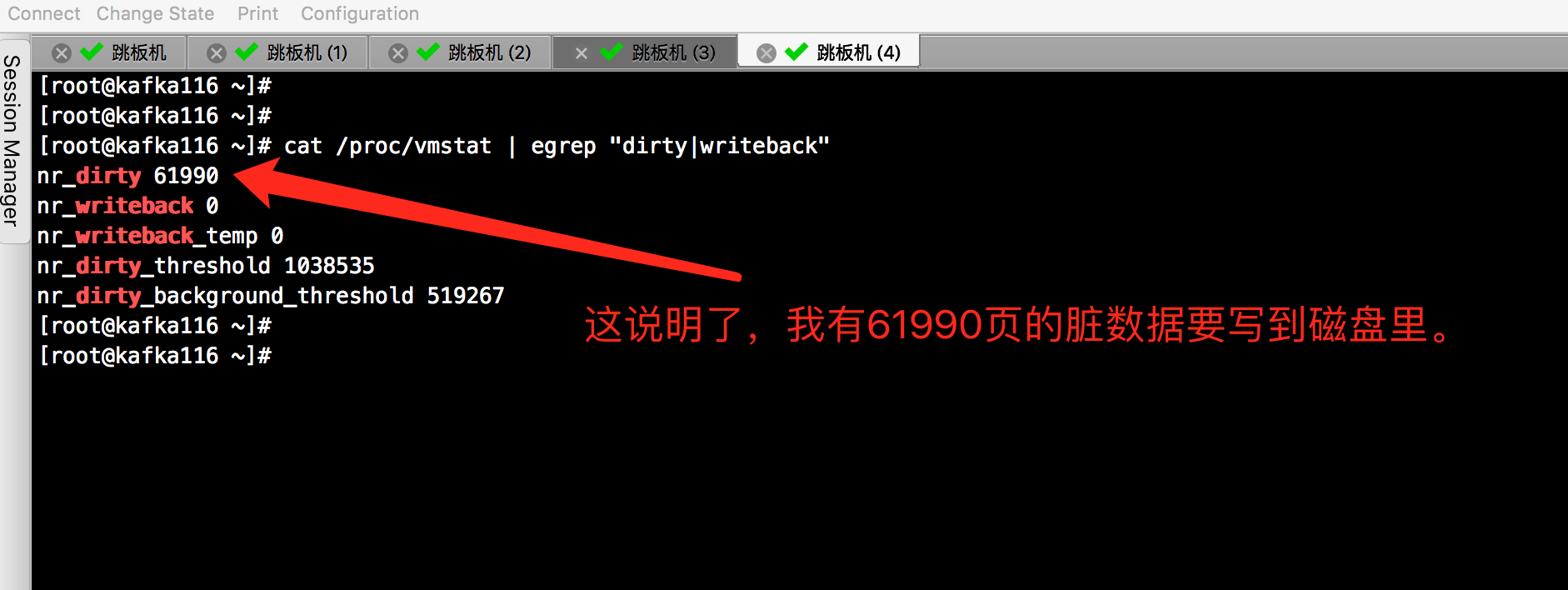
4>. 减少Cache(虚拟机的典型应用)
你可以针对要做的事情,来制定一个合适的值。
在一些情况下,我们有快速的磁盘子系统,它们有自带的带备用电池的NVRAM caches,这时候把数据放在操作系统层面就显得相对高风险了。所以我们希望系统更及时地往磁盘写数据。
可以在/etc/sysctl.conf中加入下面两行,并执行"sysctl -p" vm.dirty_background_ratio =
vm.dirty_ratio = 10 这是虚拟机的典型应用。不建议将它设置成0,毕竟有点后台IO可以提升一些程序的性能。
5>.增加Cache(适合数据并不是很重要的场景,要求读写的效率想到高的场景)
在一些场景中增加Cache是有好处的。例如,数据不重要丢了也没关系,而且有程序重复地读写一个文件。允许更多的cache,你可以更多地在内存上进行读写,提高速度。 vm.dirty_background_ratio =
vm.dirty_ratio = 80 有时候还会提高vm.dirty_expire_centisecs 这个参数的值,来允许脏数据更长时间地停留。
6>.增减兼有(如果你部署kafka集群的话,我推荐使用这个方案,在《Kafka 权威指南》一书中,也有相关的记载哟!)
有时候系统需要应对突如其来的高峰数据,它可能会拖慢磁盘。(比如说,每个小时开始时进行的批量操作等)
这个时候需要容许更多的脏数据存到内存,让后台进程慢慢地通过异步方式将数据写到磁盘当中。 vm.dirty_background_ratio =
vm.dirty_ratio = 80 这个时候,后台进行在脏数据达到5%时就开始异步清理,但在80%之前系统不会强制同步写磁盘。这样可以使IO变得更加平滑。
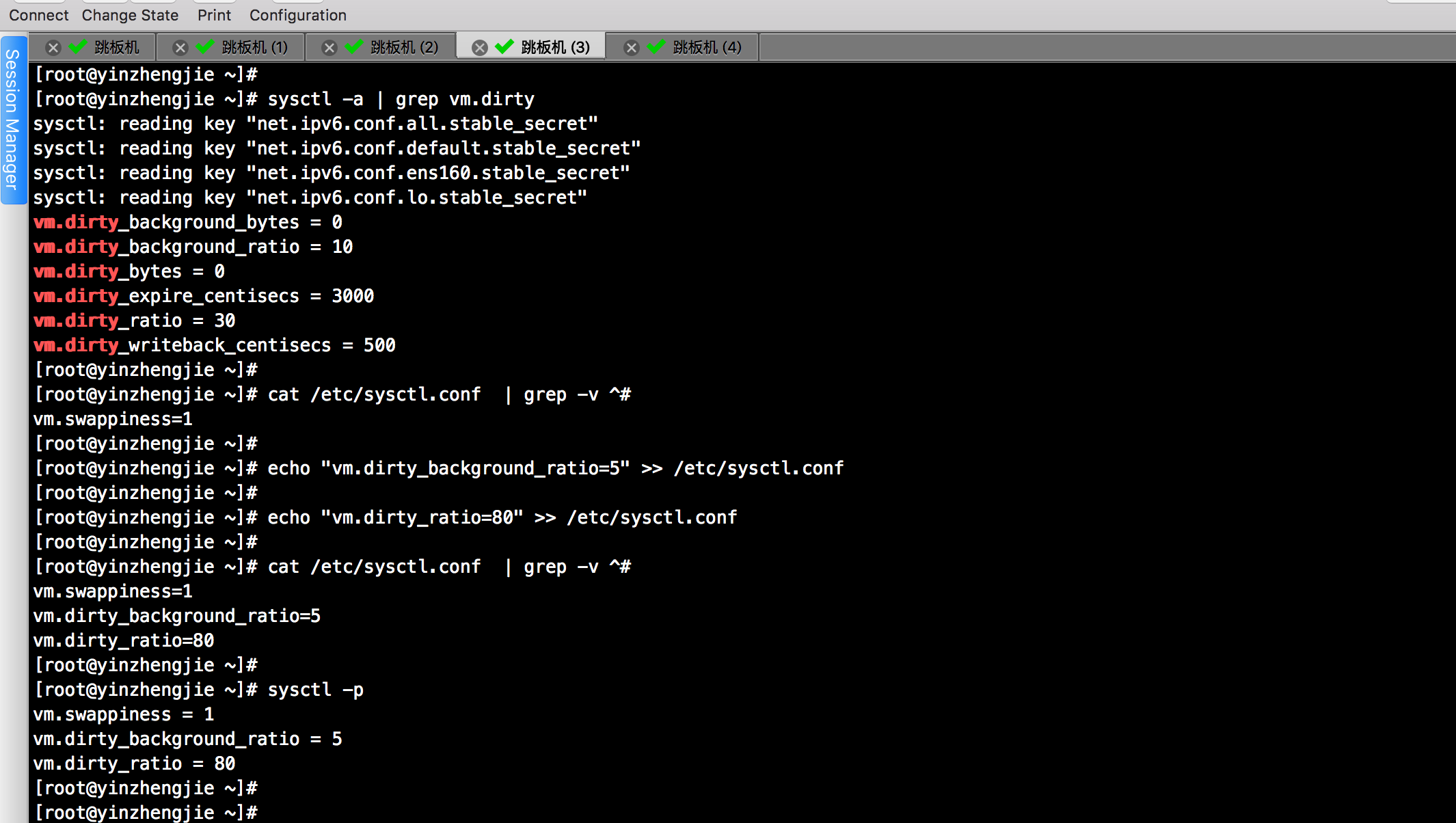
7>.案例实操-调整内核对脏页的处理方式
[root@yinzhengjie ~]# sysctl -a | grep vm.dirty
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens160.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.dirty_background_bytes =
vm.dirty_background_ratio =
vm.dirty_bytes =
vm.dirty_expire_centisecs =
vm.dirty_ratio =
vm.dirty_writeback_centisecs =
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# cat /etc/sysctl.conf | grep -v ^#
vm.swappiness=
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# echo "vm.dirty_background_ratio=5" >> /etc/sysctl.conf
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# echo "vm.dirty_ratio=80" >> /etc/sysctl.conf
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# cat /etc/sysctl.conf | grep -v ^#
vm.swappiness=
vm.dirty_background_ratio=
vm.dirty_ratio=
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# sysctl -p
vm.swappiness =
vm.dirty_background_ratio =
vm.dirty_ratio =
[root@yinzhengjie ~]#
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# sysctl -a | grep vm.dirty
sysctl: reading key "net.ipv6.conf.all.stable_secret"
sysctl: reading key "net.ipv6.conf.default.stable_secret"
sysctl: reading key "net.ipv6.conf.ens160.stable_secret"
sysctl: reading key "net.ipv6.conf.lo.stable_secret"
vm.dirty_background_bytes =
vm.dirty_background_ratio =
vm.dirty_bytes =
vm.dirty_expire_centisecs =
vm.dirty_ratio =
vm.dirty_writeback_centisecs =
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# sysctl -q vm.dirty_background_ratio
vm.dirty_background_ratio =
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# sysctl -q vm.dirty_ratio
vm.dirty_ratio =
[root@yinzhengjie ~]#
[root@yinzhengjie ~]#
Linux虚拟内存(swap)调优篇-“swappiness”,“vm.dirty_background_ratio”和“vm.dirty_ratio”的更多相关文章
- 《Kafka权威指南》读书笔记-操作系统调优篇
<Kafka权威指南>读书笔记-操作系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大部分Linux发行版默认的内核调优参数配置已经能够满足大多数应用程序的运 ...
- 大数据集群Linux CentOS 7.6 系统调优篇
大数据集群Linux CentOS 7.6 系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.设置主机hosts文件 1>.修改主机名 [root@node100 ...
- Linux网卡调优篇-禁用ipv6与优化socket缓冲区大小
Linux网卡调优篇-禁用ipv6与优化socket缓冲区大小 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一般在内网环境中,我们几乎是用不到IPV6,因此我们没有必要把多不 ...
- MySQL 优化之 Linux系统层面调优
MySQL 一般运行于Linux系统中.对于MySQL的调优一般分为Linux操作系统层面的调优和MySQL层面的调优(当然还有架构层面.业务层面.应用程序层面的调优).操作系统主要是管理和分配硬件资 ...
- 高性能linux服务器内核调优
高性能linux服务器内核调优 首先,介绍一下两个命令1.dmesg 打印系统信息.有很多同学们服务器出现问题,看了程序日志,发现没啥有用信息,还是毫无解决头绪,这时候,你就需要查看系统内核抛出的异常 ...
- linux性能查看调优
一 linux服务器性能查看1.1 cpu性能查看1.查看物理cpu个数:cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc -l ...
- <JVM下篇:性能监控与调优篇>03-JVM监控及诊断工具-GUI篇
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- <JVM下篇:性能监控与调优篇>01-概述篇-02-JVM监控及诊断工具-命令行篇
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- MySQL 数据库规范--调优篇(终结篇)
前言 这篇是MySQL 数据库规范的最后一篇--调优篇,旨在提供我们发现系统性能变弱.MySQL系统参数调优,SQL脚本出现问题的精准定位与调优方法. 目录 1.MySQL 调优金字塔理论 2.MyS ...
随机推荐
- 数据库中事务的四大特性(ACID)
本篇讲诉数据库中事务的四大特性(ACID),并且将会详细地说明事务的隔离级别. 如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性: ⑴ 原子性(Atomicity) 原子性是指事务 ...
- css溢出显示省略号
单行溢出省略号 .show-detail li .info-name { width:278px; display:inline-block; /*下面是重点*/ overflow: hidden; ...
- Java 属性映射(DozerBeanMapper)
package com.kps.common.utils; import java.util.ArrayList; import java.util.Collection; import java.u ...
- C# int数组转string字符串
方式一:通过循环数组拼接的方式: int[] types = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; string result = string.Empty ...
- 局域网共享hfs 软件使用
前言 由于想从局域网同学电脑上偷点小片,又不想用u盘拷贝.所有在同学电脑上打开hfs软件,通过自己电脑ie浏览器(chrome不行报错)下载即可. 流程 1.两台电脑在同一局域网下,在同学电脑上打开h ...
- MT【251】椭圆中的好题
已知直线$l:x+y-\sqrt{3}=0$过椭圆$E:\dfrac{x^2}{a^2}+\dfrac{y^2}{b^2}=1,(a>b>0)$的右焦点且与椭圆$E$交于$A,B$两点,$ ...
- [FJOI2016]神秘数(脑洞+可持久化)
题目描述 一个可重复数字集合S的神秘数定义为最小的不能被S的子集的和表示的正整数.例如S={1,1,1,4,13}, 1 = 1 2 = 1+1 3 = 1+1+1 4 = 4 5 = 4+1 6 = ...
- es6+的javascript拓展内容
一.let,const 1.因为块级的作用域,这样打印01234,循环外打印i会报错 for (let i = 0; i < 5; i++) { setTimeout(console.log(i ...
- redux源码解析-函数式编程
提到redux,会想到函数式编程.什么是函数式编程?是一种很奇妙的函数式的编程方法.你会感觉函数式编程这么简单,但是用起来却很方便很神奇. 在<functional javascript> ...
- webpack入门(五)webpack CLI
webpack的CLI安装和命令 Installation $ npm install webpack -g The webpack command is now available globally ...