ELASTICSEARCH 搜索的评分机制
从我们在elasticsearch复合框输入搜索语句到结果显示,展现给我们的是一个按score得分从高到底排好序的结果集。下面就来学习下elasticsearch怎样计算得分。
Lucene(或 Elasticsearch)使用 布尔模型(Boolean model) 查找匹配文档, 并用一个名为 实用评分函数(practical scoring function) 的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率(term frequency/inverse document frequency) 和 向量空间模型(vector space model),同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
Lucene计算评分的公式:
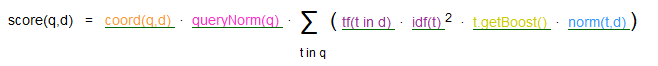
这个评分公式有6个部分组成:
coord(q,d) 评分因子,基于文档中出现查询项的个数。越多的查询项在一个文档中,说明文档的匹配程度越高。
queryNorm(q)查询的标准查询
tf(t in d) 指项t在文档d中出现的次数frequency。具体值为次数的开根号。
idf(t) 反转文档频率, 出现项t的文档数docFreq
t.getBoost 查询时候查询项加权
norm(t,d) 长度相关的加权因子
1、tf(t in d) 词频
tf(t in d) = √frequency
即出现的个数进行开方,这个没什么可以讲述的,实际打分也是如此。
2、idf(t)反转文档频率
这个的意思是出现的逆词频数,即召回的文档在总文档中出现过多少次,这个的计算在ES中与lucene中有些区别,只有在分片数为1的情况下,与lucene的计算是一致的,如果不唯一,那么每一个分片都有一个不同的idf的值,它的计算方式如下所示:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
其中,log是以e为底的,不是以10或者以2为底,这点需要注意,numDocs是指所有的文档个数,如果有分片的话,就是指的是在当前分片下总的文档个数,docFreq是指召回文档的个数,如果有分片对应的也是在当前分片下召回的个数,这点是计算的时候与lucene不同之处,如果想验证是否正确,只需将分片shard的个数设置为1即可
3、queryNorm(q)查询的标准查询
queryNorm(q) = 1 / √sumOfSquaredWeights
上述公式是ES官网的公式,这是在默认query boost为1,并且在默认term boost为1 的情况下的打分,其中
sumOfSquaredWeights =idf(t1)*idf(t1)+idf(t2)*idf(t2)+...+idf(tn)*idf(tn)
其中n为在query里面切成term的个数,但是上面全部是在默认为1的情况下的计算,实际上的计算公式如下所示:
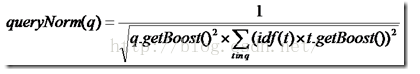
4、coord(q,d)协调因子
coord(q,d)=overlap / maxoverlap
其中overlap是检索命中query中term的个数,maxoverlap是query中总共的term个数
5、t.getboost()
对于每一个term的权值,没仔细研究这个项,个人理解的是,如果对一个field设置boost,那么如果在这个boost召回的话,每一个term的boost都是该field的boost
6、norm(t,d)
对于field的标准化因子,在官方给的解释是field越短,如果召回的话权重越大

其中d.getboost表明如果该文档权重越大那么久越重要
f.getboost表明该field的权值越大,越重要
lengthnorm表示该field越长,越不重要,越短,越重要,在官方文档给出的公式中,默认boost全部为1,在此给出官方文档的打分公式:
norm(d) = 1 / √numTerms
如查询解析语句得分:
_search?explain
{
"query": {
"multi_match": {
"query": "居夷集第三卷",
"fields": [
"title",
"keywords",
"author"
]
}
}
}
multi_match默认选择fields中得分最高的作为最终的得分相当于max(field_score),如下图:红框1的得分是属性keywords中居在文档id=51时的得分(红框1= 红框2 * 红框3)
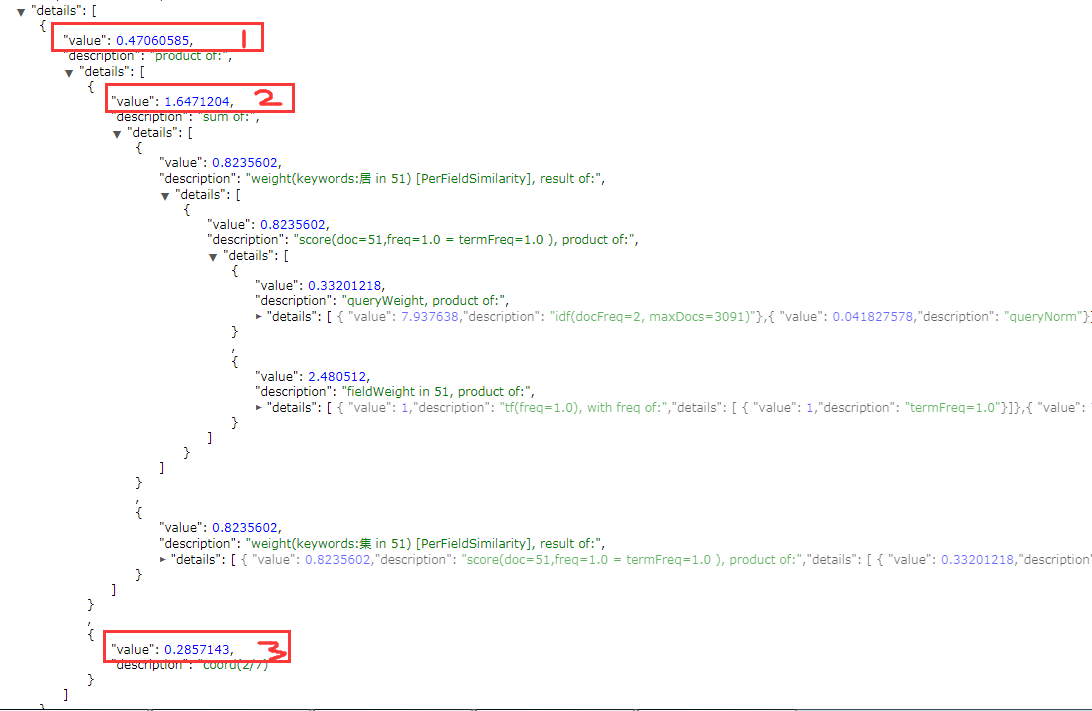
具体的计算公式:红框2处的得分由 queryWeight * fieldWeight 两部分的乘积组成。词频tf(t),反向文档频率idf(t)
如:queryWeight = idf(t) * queryNorm(d)
idf(t) = ( 1+ln( maxDocs / (docFreq +1 ) ) ) = (1 + ln ( 3091 / ( 2 +1 )) 注意这个是自然对数

再来看一个只有一个分片的索引来加深刚才的计算,其实在es的head插件中显示的得分的计算公式实际可以对应的就是:
sumScore = partScore1 +partScore2 +partScore3 + ...
partScore = queryWeight * fieldWeight
queryWeight = idf(t) * queryNorm(d)
fieldweight = idf * tf * fieldnorm
总得分:0.5216244 = 0.119818024 + 0.119818024 + 0.119818024 + 0.119818024 + 0.04235228
partScore 1 : 0.119818024 = 0.4792721 * 0.25
queryWeight : 0.4792721 =( 1 + ln( 2 / (1+1 ) ) ) * (1/ √ (1*1+1*1+1*1+1*1 + 0.5945349*0.5945349))
fieldweight : 0.25 = 1 * 1 * 0.25







Reference:
[1] http://blog.csdn.net/molong1208/article/details/50623948
[2] http://www.cnblogs.com/forfuture1978/archive/2010/03/07/1680007.html
[3] https://www.elastic.co/guide/cn/elasticsearch/guide/current/scoring-theory.html
ELASTICSEARCH 搜索的评分机制的更多相关文章
- lucene 的评分机制
lucene 的评分机制 elasticsearch是基于lucene的,所以他的评分机制也是基于lucene的.评分就是我们搜索的短语和索引中每篇文档的相关度打分. 如果没有干预评分算法的时候,每次 ...
- Elasticseach的评分机制
lucene 的评分机制 elasticsearch是基于lucene的,所以他的评分机制也是基于lucene的.评分就是我们搜索的短语和索引中每篇文档的相关度打分. 如果没有干预评分算法的时候,每次 ...
- 看完这篇还不会 Elasticsearch 搜索,那我就哭了!
本文主要介绍 ElasticSearch 搜索相关的知识,首先会介绍下 URI Search 和 Request Body Search,同时也会学习什么是搜索的相关性,如何衡量相关性. Search ...
- Solr In Action 笔记(2) 之 评分机制(相似性计算)
Solr In Action 笔记(2) 之评分机制(相似性计算) 1 简述 我们对搜索引擎进行查询时候,很少会有人进行翻页操作.这就要求我们对索引的内容提取具有高度的匹配性,这就搜索引擎文档的相似性 ...
- ElasticSearch搜索介绍四
ElasticSearch搜索 最基础的搜索: curl -XGET http://localhost:9200/_search 返回的结果为: { "took": 2, &quo ...
- Lucene Scoring 评分机制
原文出处:http://blog.chenlb.com/2009/08/lucene-scoring-architecture.html Lucene 评分体系/机制(lucene scoring)是 ...
- Lucene 的 Scoring 评分机制
转自: http://www.oschina.net/question/5189_7707 Lucene 评分体系/机制(lucene scoring)是 Lucene 出名的一核心部分.它对用户来 ...
- Elasticsearch搜索结果返回不一致问题
一.背景 这周在使用Elasticsearch搜索的时候遇到一个,对于同一个搜索请求,会出现top50返回结果和排序不一致的问题.那么为什么会出现这样的问题? 后来通过百度和google,发现这是因为 ...
- ElasticStack学习(六):ElasticSearch搜索初探
一.ElasticSearch搜索介绍 1.ElasticSearch搜索方式主要分为以下两种: 1).URI Search:此种查询主要是使用Http的Get方法,在URL中使用查询参数进行查询: ...
随机推荐
- Matplotlib学习---用seaborn画矩阵图(pair plot)
矩阵图非常有用,人们经常用它来查看多个变量之间的联系. 下面用著名的鸢尾花数据来画一个矩阵图.从sklearn导入鸢尾花数据,然后将其转换成pandas的DataFrame类型,最后用seaborn画 ...
- 【BZOJ1419】Red is good 期望DP
题目大意 桌面上有\(R\)张红牌和\(B\)张黑牌,随机打乱顺序后放在桌面上,开始一张一张地翻牌,翻到红牌得到\(1\)美元,黑牌则付出\(1\)美元.可以随时停止翻牌,在最优策略下平均能得到多少钱 ...
- 洛谷P4891 序列(势能线段树)
洛谷题目传送门 闲话 考场上一眼看出这是个毒瘤线段树准备杠题,发现实在太难调了,被各路神犇虐哭qwq 考后看到各种优雅的暴力AC......宝宝心里苦qwq 思路分析 题面里面是一堆乱七八糟的限制和性 ...
- android startActivityForResult 使用实例
ActivityForResult.java public class ActivityForResult extends Activity { Button bn; EditText city; @ ...
- 【arc073e】Ball Coloring(线段树,贪心)
[arc073e]Ball Coloring(线段树,贪心) 题面 AtCoder 洛谷 题解 大型翻车现场,菊队完美压中男神的模拟题 首先钦定全局最小值为红色,剩下的袋子按照其中较大值排序. 枚举前 ...
- css- @media @font-face 的理解
在我的博客园定制的css中有2个之前没有遇到的csss属性@font-face @media @media 在css文件中的使用如下 ` @media screen and (max-width: 1 ...
- <Android基础>(一)
第一章Android 2003年10月,Andy Rubin等人创办了Android公司.2005年8月谷歌收购. 1.1 Android全貌 1.1.1 Android系统架构 1.Linux内核层 ...
- 「SHOI2016」黑暗前的幻想乡 解题报告
「SHOI2016」黑暗前的幻想乡 sb题想不出来,应该去思考原因,而不是自暴自弃 一开始总是想着对子树做dp,但是状态压不起去,考虑用容斥消减一些条件变得好统计,结果越想越乱. 期间想过矩阵树定理, ...
- 工作队列.py
#对列模式图Work Queue背后的主要思想是避免立即执行资源密集型任务的时,需要等待其他任务完成.所以我们把任务安排的晚一些,我们封装一个任务到消息中并把它发送到队列,一个进程运行在后端发送并最终 ...
- Linux基本命令总结(三)
接上篇: 11,more命令,功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上. more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示 ...