Hadoop记录-fair公平调度队列管理
<?xml version="1.0"?>
<allocations>
<queue name="root">
<queue name="default">
<minResources>2048 mb,4 vcores</minResources>
<maxResources>2000000 mb,660 vcores</maxResources>
<maxRunningApps>80</maxRunningApps>
<aclSubmitApps>*</aclSubmitApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode> </queue>
<queue name="queue_a">
<minResources>2048 mb,4 vcores</minResources>
<maxResources>102400 mb,148 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<aclSubmitApps>*</aclSubmitApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode>
</queue>
<queue name="queue_b">
<minResources>2048 mb,4 vcores</minResources>
<maxResources>102400 mb,148 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<aclSubmitApps>*</aclSubmitApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode>
</queue>
</queue>
</allocations>
beeline -u " jdbc:hive2://10.202.77.201:10000" -n hive -p hive
set hive.execution.engine=tez;
nohup hive --service hiveserver2 &
nohup hive --service metastore &
hive -S -e "select * from xxx" --S静音模式不打印MR2的进度信息 e加载hql查询语句
hive -f test.hql --加载一个hql文件
source test.hql
for f in 'rpm -qa | grep xxx';do rpm -e --nodeps ${f} done;
磁盘空间满了,kill超时太长的job
cd hive/yarn/local1/usercache/hive/appcache
su yarn
yarn application -kill job名
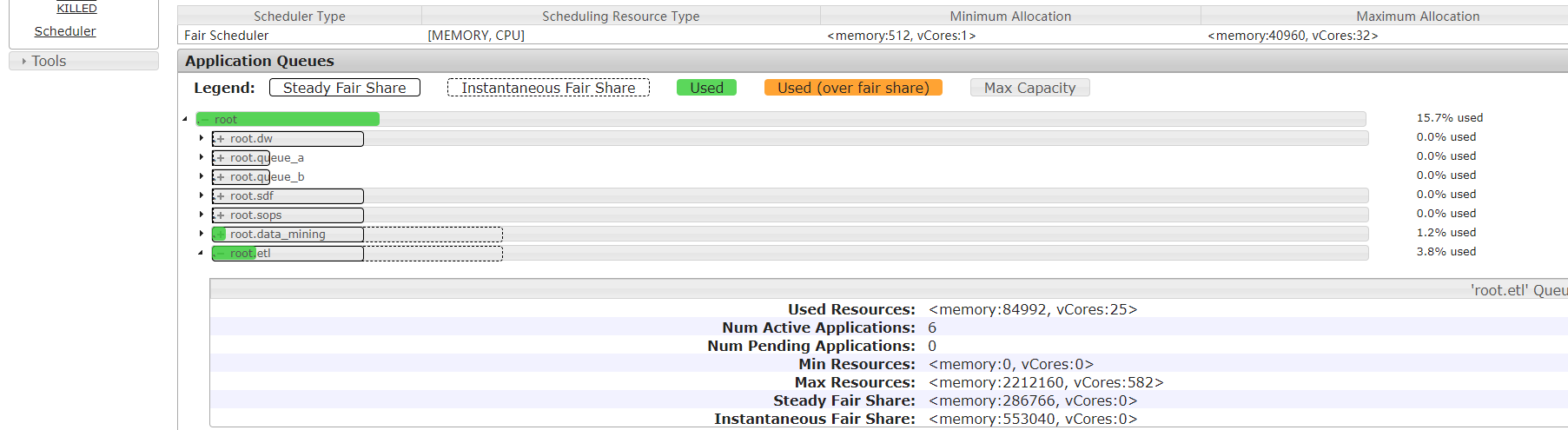
Hadoop记录-fair公平调度队列管理的更多相关文章
- Hadoop记录-MRv2(Yarn)运行机制
1.MRv2结构—Yarn模式运行机制 Client---客户端提交任务 ResourceManager---资源管理 ---Scheduler调度器-资源分配Containers ----在Yarn ...
- hadoop记录-Hadoop参数汇总
Hadoop参数汇总 linux参数 以下参数最好优化一下: 文件描述符ulimit -n 用户最大进程 nproc (hbase需要 hbse book) 关闭swap分区 设置合理的预读取缓冲区 ...
- hadoop学习笔记肆--元数据管理机制
1.首先,认识几个名词 (1).NameNode中读.写.以及DataNode映射等信息叫做“元数据” ,NameNode元数据存放位置有.内存.fsimage.edits log三个位置. (2). ...
- Hadoop记录-hdfs转载
Hadoop 存档 每个文件均按块存储,每个块的元数据存储在namenode的内存中,因此hadoop存储小文件会非常低效.因为大量的小文件会耗尽namenode中的大部分内存.但注意,存储小文件所需 ...
- Hadoop记录-hadoop介绍
1.hadoop是什么? Hadoop 是Apache基金会下一个开源的大数据分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心,为用户提供了系统底层细节透明的分布式基础架构. ...
- spark的task调度器(FAIR公平调度算法)
FAIR 调度策略的树结构如下图所示: FAIR 调度策略内存结构 FAIR 模式中有一个 rootPool 和多个子 Pool, 各个子 Pool 中存储着所有待分配的 TaskSetMagage ...
- hadoop记录-hive常见设置
分区表 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;create tabl ...
- Hadoop记录-JMX参数
Yarn metrics参数说明 获取Yarn jmx信息:curl -i http://xxx:8088/jmx Hadoop:service=ResourceManager,name=FSOpDu ...
- Hadoop记录-日常运维操作
1.Active NameNode hang死,未自动切换 #登录当前hang死 Active namenode主机,停止Namenode,触发自动切换.hadoop-daemon.sh stop n ...
随机推荐
- 实验九 在JSP中使用数据库
实验性质:验证性 实验学时: 1学时 实验地点: 一 .实验目的与要求 1. 掌握在JSP中使用数据库的方法. 2. 掌握JSP对数据库的基本操作:增.删.改.查. 二. 实验内容 1.JSP访问数据 ...
- 【AGC014E】Blue and Red Tree 并查集 启发式合并
题目描述 有一棵\(n\)个点的树,最开始所有边都是蓝边.每次你可以选择一条全是蓝边的路径,删掉其中一条,再把这两个端点之间连一条红边.再给你一棵树,这棵树的所有边都是红边,问你最终能不能把原来的树变 ...
- Eclipse中项目Project Explorer视图与Package Explorer视图
Package Explorer视图: Project Explorer视图 两种视图的切换:
- Docker 私有仓库 Harbor registry 安全认证搭建 [Https]
Harbor源码地址:https://github.com/vmware/harborHarbort特性:基于角色控制用户和仓库都是基于项目进行组织的, 而用户基于项目可以拥有不同的权限.基于镜像的复 ...
- [UOJ317]【NOI2017】游戏 题解
题意 小 L 计划进行 \(n\) 场游戏,每场游戏使用一张地图,小 L 会选择一辆车在该地图上完成游戏. 小 L 的赛车有三辆,分别用大写字母 A.B.C 表示.地图一共有四种,分别用小写字 ...
- 自学Linux命令行与Shell脚本之路
自学Linux命令行与Shell脚本之路[第一回]:初识Linux 1.1 自学Linux Shell1.1-Linux初识 1.2 自学Linux Shell1.2-Linux目录结构 1.3 ...
- bzoj1009 GT考试 (kmp+矩阵优化dp)
设f[i][j]是到第i位 已经匹配上了j位的状态数 然后通过枚举下一位放0~9,可以用kmp处理出一个转移的矩阵 然后就可以矩阵快速幂了 #include<bits/stdc++.h> ...
- 发现环 (拓扑或dfs)
题目链接:http://lx.lanqiao.cn/problem.page?gpid=T453 问题描述 小明的实验室有N台电脑,编号1~N.原本这N台电脑之间有N-1条数据链接相连,恰好构成一个树 ...
- redux源码解析-redux的架构
redux很小的一个框架,是从flux演变过来的,尽管只有775行,但是它的功能很重要.react要应用于生成环境必须要用flux或者redux,redux是flux的进化产物,优于flux. 而且r ...
- 【洛谷P1903】数颜色
题目大意:给定一个长度为 N 的序列,每个点有一个颜色.现给出 M 个操作,支持单点修改颜色和询问区间颜色数两个操作. 题解:学会了序列带修改的莫队. 莫队本身是不支持修改的.带修该莫队的本质也是对询 ...