第十三节、SURF特征提取算法
上一节我们已经介绍了SIFT算法,SIFT算法对旋转、尺度缩放、亮度变化等保持不变性,对视角变换、仿射变化、噪声也保持一定程度的稳定性,是一种非常优秀的局部特征描述算法。但是其实时性相对不高。
SURF(Speeded Up Robust Features)算法改进了特征了提取和描述方式,用一种更为高效的方式完成特征点的提取和描述。
一 使用快速Hessian算法和SURF来提取和检测特征
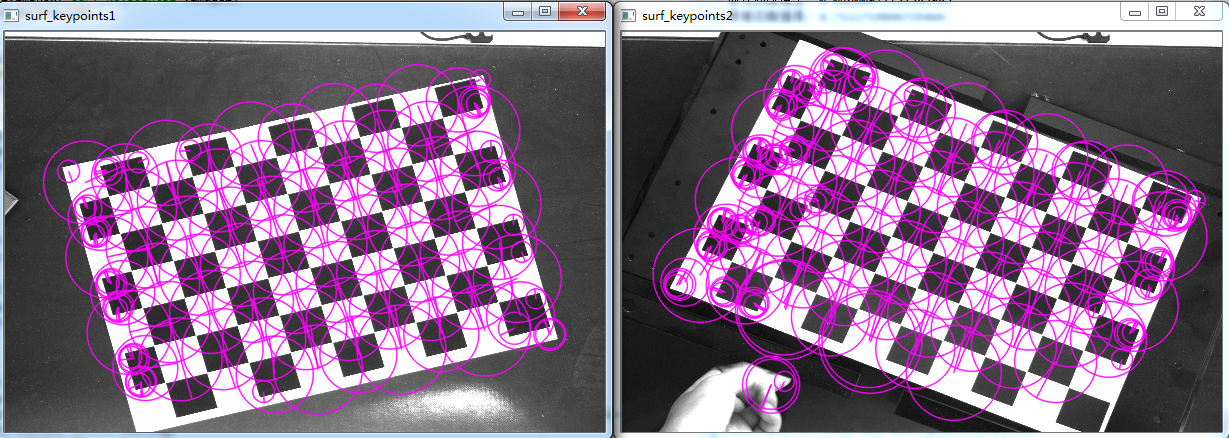
我们先用OpenCV库函数演示一下快速Hessian算法和SURF来提取的效果,然后再来讲述一下SURF算法的原理。
SURF特征检测算法由Herbert Lowe于2006年发表,该算法比SIFT算法快好几倍,它吸收了SIFT算法的思想。
SURF算法采用快速Hessian算法检测关键点,而SURF算子会通过一个特征向量来描述关键点周围区域的情况。这和SIFT算法很像,SIFT算法分别采用DoG和SIFT算子来检测关键点和提取关键点的描述符。下面我们来演示一个例子:
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 24 20:09:32 2018 @author: lenovo
""" # -*- coding: utf-8 -*-
"""
Created on Wed Aug 22 16:53:16 2018 @author: lenovo
""" '''
SURF算法
'''
import cv2
import numpy as np img = cv2.imread('./image/cali.bmp')
img = cv2.resize(img,dsize=(600,400))
#转换为灰度图像
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#创建一个SURF对象
surf = cv2.xfeatures2d.SURF_create(20000)
#SIFT对象会使用Hessian算法检测关键点,并且对每个关键点周围的区域计算特征向量。该函数返回关键点的信息和描述符
keypoints,descriptor = surf.detectAndCompute(gray,None)
print(type(keypoints),len(keypoints),keypoints[0])
print(descriptor.shape)
#在图像上绘制关键点
img = cv2.drawKeypoints(image=img,keypoints = keypoints,outImage=img,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
cv2.imshow('surf_keypoints',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
我们把Hessian阈值设置为20000,阈值越高,能识别的特征就越少,因此可以采用试探法来得到最优检测。

二 SURF算法原理
1、SURF特征检测的步骤
- 尺度空间的极值检测:搜索所有尺度空间上的图像,通过Hessian来识别潜在的对尺度和选择不变的兴趣点。
- 特征点过滤并进行精确定位。
- 特征方向赋值:统计特征点圆形邻域内的Harr小波特征。即在60度扇形内,每次将60度扇形区域旋转0.2弧度进行统计,将值最大的那个扇形的方向作为该特征点的主方向。
- 特征点描述:沿着特征点主方向周围的邻域内,取$4×4$个矩形小区域,统计每个小区域的Haar特征,然后每个区域得到一个4维的特征向量。一个特征点共有64维的特征向量作为SURF特征的描述子。
2、构建Hessian(黑塞矩阵)
构建Hessian矩阵的目的是为了生成图像稳定的边缘点(突变点),跟Canny、拉普拉斯边缘检测的作用类似,为特征提取做准备。构建Hessian矩阵的过程对应着SIFT算法中的DoG过程。
黑塞矩阵(Hessian Matrix)是由一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。由德国数学家Ludwin Otto Hessian于19世纪提出。
对于一个图像$I(x,y)$,其Hessian矩阵如下:
$$H(I(x,y))=\begin{bmatrix} \frac{\partial^2I}{\partial{x^2}} & \frac{\partial^2I}{\partial{x}\partial{y}} \\ \frac{\partial^2I}{\partial{x}\partial{y}} & \frac{\partial^2I}{\partial{y^2}} \end{bmatrix}$$
H矩阵的判别式是:
$$Det(H)=\frac{\partial^2I}{\partial{x^2}}*\frac{\partial^2I}{\partial{y^2}}-\frac{\partial^2I}{\partial{x}\partial{y}} * \frac{\partial^2I}{\partial{x}\partial{y}}$$
在构建Hessian矩阵前需要对图像进行高斯滤波,经过滤波后的Hessian矩阵表达式为:
$$H(x,y,\sigma)=\begin{bmatrix} L_{xx}(x,y,\sigma) & L_{xy}(x,y,\sigma) \\ L_{xy}(x,y,\sigma) & L_{yy}(x,y,\sigma) \end{bmatrix}$$
其中$(x,y)$为像素位置,$L(x,y,\sigma)=G(\sigma)*I(x,y)$,代表着图像的高斯尺度空间,是由图像和不同的高斯卷积得到。
我们知道在离散数学图像中,一阶导数是相邻像素的灰度差:
$$L_x=L(x+1,y)-L(x,y)$$
二阶导数是对一阶导数的再次求导:
$$L_{xx}=[L(x+1,y)-L(x,y)]-[L(x,y)-L(x-1,y)]$$
$$=L(x+1,y)+L(x-1,y)-2L(x,y)$$
反过来看Hessian矩阵的判别式,其实就是当前点对水平方向二阶偏导数乘以垂直方向二阶偏导数再减去当前水平、垂直二阶偏导的二次方:
$$Det(H)=L_{xx}*L_{yy}-L_{xy}*L_{xy}$$
通过这种方法可以为图像中每个像素计算出其H行列式的决定值,并用这个值来判别图像局部特征点。Hession矩阵判别式中的$L(x,y)$是原始图像的高斯卷积,由于高斯核服从正太分布,从中心点往外,系数越来越小,为了提高运算速度,SURF算法使用了盒式滤波器来替代高斯滤波器$L$,所以在$L_{xy}$上乘了一个加权系数0.9,目的是为了平衡因使用盒式滤波器近似所带来的误差,则H矩阵判别式可表示为:
$$Det(H)=L_{xx}*L_{yy}-(0.9*L_{xy})^2$$
盒式滤波器和高斯滤波器的示意图如下:

上面两幅图是$9×9$高斯滤波器模板分别在图像垂直方向上二阶导数$L_{yy}$和$L_{xy}$对应的值,下边两幅图是使用盒式滤波器对其近似,灰色部分的像素值为0,黑色为-2,白色为1.
那么为什么盒式滤波器可以提高运算速度呢?这就涉及到积分图的使用,盒式滤波器对图像的滤波转化成计算图像上不同区域间像素的加减运算问题,这正是积分图的强项,只需要简单积分查找积分图就可以完成。
3、构造尺度空间
同SIFT算法一样,SURF算法的尺度空间由$O$组$S$层组成,不同的是,SIFT算法下一组图像的长宽均是上一组的一半,同一组不同层图像之间尺寸一样,但是所使用的尺度空间因子(高斯模糊系数$\sigma$)逐渐增大;而在SURF算法中,不同组间图像的尺寸都是一致的,不同的是不同组间使用的盒式滤波器的模板尺寸逐渐增大,同一组不同层图像使用相同尺寸的滤波器,但是滤波器的尺度空间因子逐渐增大。如下图所示:

4、特征点过滤并进行精确定位
SURF特征点的定位过程和SIFT算法一致,将经过Hessian矩阵处理的每个像素点(即获得每个像素点Hessian矩阵的判别式值)与其图像域(相同大小的图像)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。如图所示,中间的检测点要和其所在图像的$3×3$邻域8个像素点,以及其相邻的上下两层$3×3$邻域18个像素点,共26个像素点进行比较。
初步定位出特征点后,再经过滤除能量比较弱的关键点以及错误定位的关键点,筛选出最终的稳定的特征点。

5、计算特征点主方向
SIFT算法特征点的主方向是采用在特征点邻域内统计其梯度直方图,横轴是梯度方向的角度,纵轴是梯度方向对应梯度幅值的累加,取直方图bin最大的以及超过最大80%的那些方向作为特征点的主方向。
而在SURF算法中,采用的是统计特征点圆形邻域内的Harr小波特征,即在特征点的圆形邻域内,统计60度扇形内所有点的水平、垂直Harr小波特征总和,然后扇形以0.2弧度大小的间隔进行旋转并再次统计该区域内Harr小波特征值之后,最后将值最大的那个扇形的方向作为该特征点的主方向。该过程示意图如下:

Harr特征的具体内容可以参考第九节、人脸检测之Haar分类器。
6、生成特征描述
在SIFT算法中,为了保证特征矢量的旋转不变性,先以特征点为中心,在附近邻域内将坐标轴旋转$\theta$(特征点的主方向)角度,然后提取特征点周围$4×4$个区域块,统计每小块内8个梯度方向,这样一个关键点就可以产生128维的SIFT特征向量。
SURF算法中,也是提取特征点周围$4×4$个矩形区域块,但是所取得矩形区域方向是沿着特征点的主方向,而不是像SIFT算法一样,经过旋转$\theta$角度。每个子区域统计25个像素点水平方向和垂直方向的Haar小波特征,这里的水平和垂直方向都是相对主方向而言的。该Harr小波特征为水平方向值之和、垂直方向值之和、水平方向值绝对值之和以及垂直方向绝对之和4个方向。该过程示意图如下:
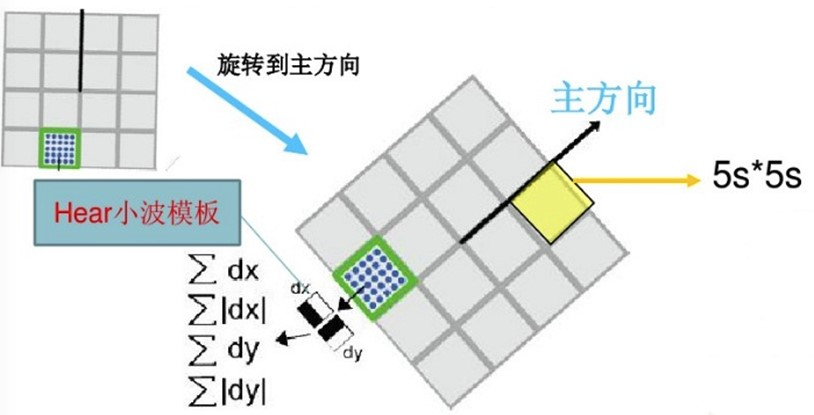
把这4个值作为每个子块区域的特征向量,所以一共有$4×4×4$=64维向量作为SURF特征的描述子,比SIFT特征的描述子减少了一半。
三 特征点匹配
与SIFT特征点匹配类似,SURF也是通过计算两个特征点间特征向量的欧氏距离来确定匹配度,欧式距离越短,代表两个特征点的匹配度越好。不同的是SURF还加入了Hessian矩阵迹(矩阵特征值的和)的判断,如果两个特征点的矩阵迹正负号相同,代表着两个特征点具有相同方向上的对比度变化,如果不同,说明这两个特征点的对比度方向是相反的,即使欧氏距离为0,也直接剔除。
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 24 20:09:32 2018 @author: lenovo
""" # -*- coding: utf-8 -*-
"""
Created on Wed Aug 22 16:53:16 2018 @author: lenovo
""" '''
SURF算法
'''
import cv2
import numpy as np '''1、加载图片'''
img1 = cv2.imread('./image/cali1.bmp',cv2.IMREAD_GRAYSCALE)
img1 = cv2.resize(img1,dsize=(600,400))
img2 = cv2.imread('./image/cali2.bmp',cv2.IMREAD_GRAYSCALE)
img2 = cv2.resize(img2,dsize=(600,400))
image1 = img1.copy()
image2 = img2.copy() '''2、提取特征点'''
#创建一个SURF对象
surf = cv2.xfeatures2d.SURF_create(25000)
#SIFT对象会使用Hessian算法检测关键点,并且对每个关键点周围的区域计算特征向量。该函数返回关键点的信息和描述符
keypoints1,descriptor1 = surf.detectAndCompute(image1,None)
keypoints2,descriptor2 = surf.detectAndCompute(image2,None)
print('descriptor1:',descriptor1.shape,'descriptor2',descriptor2.shape)
#在图像上绘制关键点
image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
image2 = cv2.drawKeypoints(image=image2,keypoints = keypoints2,outImage=image2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
cv2.imshow('surf_keypoints1',image1)
cv2.imshow('surf_keypoints2',image2)
cv2.waitKey(20) '''3、特征点匹配'''
matcher = cv2.FlannBasedMatcher()
matchePoints = matcher.match(descriptor1,descriptor2)
print(type(matchePoints),len(matchePoints),matchePoints[0]) #提取强匹配特征点
minMatch = 1
maxMatch = 0
for i in range(len(matchePoints)):
if minMatch > matchePoints[i].distance:
minMatch = matchePoints[i].distance
if maxMatch < matchePoints[i].distance:
maxMatch = matchePoints[i].distance
print('最佳匹配值是:',minMatch)
print('最差匹配值是:',maxMatch) #获取排雷在前边的几个最优匹配结果
goodMatchePoints = []
for i in range(len(matchePoints)):
if matchePoints[i].distance < minMatch + (maxMatch-minMatch)/16:
goodMatchePoints.append(matchePoints[i]) #绘制最优匹配点
outImg = None
outImg = cv2.drawMatches(img1,keypoints1,img2,keypoints2,goodMatchePoints,outImg,matchColor=(0,255,0),flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
cv2.imshow('matche',outImg)
cv2.waitKey(0)
cv2.destroyAllWindows()
我们来看一看特征点匹配效果,可以看到好多点都匹配错误,这主要与我选择的图片有关,由于我选择的图片是用来做相机标点的,而当我们使用SURF算法提取特征点,图片上大部分特征点都具有相同的性质,特征向量也近似相等,因此在匹配时会出现很大的误差。
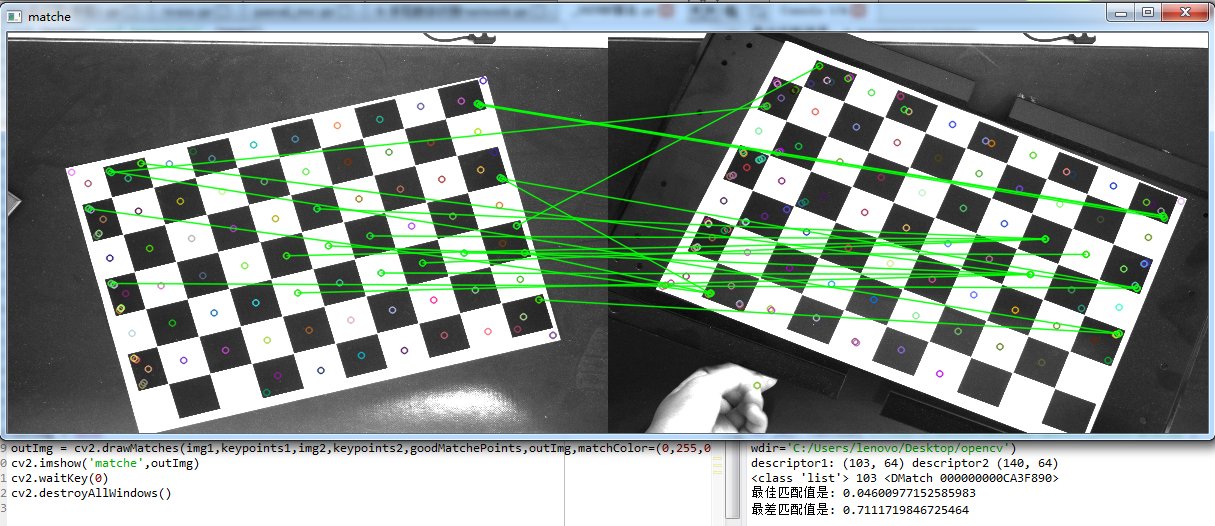
下面我们更换两张图片,再次进行特征点匹配:

我们可以看到这个匹配效果比刚才好了不少,而且我对Hessian阈值也进行了修改,这个值需要自己不断的调整,以达到自己的期望。但是总体上来看,我们选择的这两幅图片亮度和对比度差异都是很大的,而且拍摄所使用的相机也是不同的,左侧是我自己用手机拍摄到的,右侧是从网上下载的,匹配能有这样的效果也已经不错了。但是如果我们想达到更高的匹配度,我们应该尽量选择两张更为相似的图片。下面是我稍微修改后的代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 24 20:09:32 2018 @author: lenovo
""" # -*- coding: utf-8 -*-
"""
Created on Wed Aug 22 16:53:16 2018 @author: lenovo
""" '''
SURF算法
'''
import cv2 '''1、加载图片'''
img1 = cv2.imread('./image/match1.jpg')
img1 = cv2.resize(img1,dsize=(600,400))
gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
img2 = cv2.imread('./image/match2.jpg')
img2 = cv2.resize(img2,dsize=(600,400))
gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
image1 = gray1.copy()
image2 = gray2.copy() '''2、提取特征点'''
#创建一个SURF对象
surf = cv2.xfeatures2d.SURF_create(10000)
#SIFT对象会使用Hessian算法检测关键点,并且对每个关键点周围的区域计算特征向量。该函数返回关键点的信息和描述符
keypoints1,descriptor1 = surf.detectAndCompute(image1,None)
keypoints2,descriptor2 = surf.detectAndCompute(image2,None)
print('descriptor1:',descriptor1.shape,'descriptor2',descriptor2.shape)
#在图像上绘制关键点
image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
image2 = cv2.drawKeypoints(image=image2,keypoints = keypoints2,outImage=image2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
cv2.imshow('surf_keypoints1',image1)
cv2.imshow('surf_keypoints2',image2)
cv2.waitKey(20) '''3、特征点匹配'''
matcher = cv2.FlannBasedMatcher()
matchePoints = matcher.match(descriptor1,descriptor2)
print(type(matchePoints),len(matchePoints),matchePoints[0]) #提取强匹配特征点
minMatch = 1
maxMatch = 0
for i in range(len(matchePoints)):
if minMatch > matchePoints[i].distance:
minMatch = matchePoints[i].distance
if maxMatch < matchePoints[i].distance:
maxMatch = matchePoints[i].distance
print('最佳匹配值是:',minMatch)
print('最差匹配值是:',maxMatch) #获取排雷在前边的几个最优匹配结果
goodMatchePoints = []
for i in range(len(matchePoints)):
if matchePoints[i].distance < minMatch + (maxMatch-minMatch)/4:
goodMatchePoints.append(matchePoints[i]) #绘制最优匹配点
outImg = None
outImg = cv2.drawMatches(img1,keypoints1,img2,keypoints2,goodMatchePoints,outImg,matchColor=(0,255,0),flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
cv2.imshow('matche',outImg)
cv2.waitKey(0)
cv2.destroyAllWindows()
参考文章:
[2]SURF算法
[5]SURF原理及源码解析(C++)
第十三节、SURF特征提取算法的更多相关文章
- Surf特征提取分析
Surf特征提取分析 Surf Hessian SIFT 读"H.Bay, T. Tuytelaars, L. V. Gool, SURF:Speed Up Robust Features[ ...
- OpenCV Using Python——基于SURF特征提取和金字塔LK光流法的单目视觉三维重建 (光流、场景流)
https://blog.csdn.net/shadow_guo/article/details/44312691 基于SURF特征提取和金字塔LK光流法的单目视觉三维重建 1. 单目视觉三维重建问题 ...
- centos LB负载均衡集群 三种模式区别 LVS/NAT 配置 LVS/DR 配置 LVS/DR + keepalived配置 nginx ip_hash 实现长连接 LVS是四层LB 注意down掉网卡的方法 nginx效率没有LVS高 ipvsadm命令集 测试LVS方法 第三十三节课
centos LB负载均衡集群 三种模式区别 LVS/NAT 配置 LVS/DR 配置 LVS/DR + keepalived配置 nginx ip_hash 实现长连接 LVS是四层LB ...
- (转)第二十三节 inotify事件监控工具
第二十三节 inotify事件监控工具 标签(空格分隔): Linux实战教学笔记-陈思齐 原文:http://www.cnblogs.com/chensiqiqi/p/6542268.html 第1 ...
- 【特征检测】BRISK特征提取算法
[特征检测]BRISK特征提取算法原创hujingshuang 发布于2015-07-24 22:59:21 阅读数 17840 收藏展开简介 BRISK算法是2011年ICCV上< ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
随机推荐
- Java多线程2:线程的使用及其生命周期
一.线程的使用方式 1.继承Thread类,重写父类的run()方法 优点:实现简单,只需实例化继承类的实例,即可使用线程 缺点:扩展性不足,Java是单继承的语言,如果一个类已经继承了其他类,就无法 ...
- Delphi MDI 子窗体的创建和销毁 [zhuan]
1.如果要创建一个mdi child,先看是否有这个child 存在,如果有,则用它,如果没有再创建 //该函数判断MDI 子窗体是否存在,再进行创建和显示function isInclude(for ...
- django CBV视图源码分析
典型FBV视图例子 url路由系统 from django.conf.urls import url from django.contrib import admin from luffycity.v ...
- 自定义Wed框架
Wed框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web框架了. 半成品自定义wed框架 impor ...
- ☆ [HDU4825] Xor Sum「最大异或和(Trie树)」
传送门:>Here< 题意:给出一个集合,包含N个数,每次询问给出一个数x,问x与集合中的一个数y异或得到最大值时,y是多少? 解题思路 由于N,M非常大,暴力显然不行.抓住重点是异或,所 ...
- 【BZOJ3814】【清华集训2014】简单回路 状压DP
题目描述 给你一个\(n\times m\)的网格图和\(k\)个障碍,有\(q\)个询问,每次问你有多少个不同的不经过任何一个障碍点且经过\((x,y)\)与\((x+1,y)\)之间的简单回路 \ ...
- codeforces 600E . Lomsat gelral (线段树合并)
You are given a rooted tree with root in vertex 1. Each vertex is coloured in some colour. Let's cal ...
- 使用IDEA部署项目到远程服务器
1.选择Tools -> Deployment -> Configuration... 2.配置连接信息,Linux服务器一般都选择SFTP 3.配置本地上传文件路径.远程上传文件路径 4 ...
- [CF438D]The Child and Sequence【线段树】
题目大意 区间取模,区间求和,单点修改. 分析 其实算是一道蛮简单的水题. 首先线段树非常好解决后两个操作,重点在于如何解决区间取模的操作. 一开始想到的是暴力单点修改,但是复杂度就飙到了\(mnlo ...
- Chinese Mahjong UVA - 11210 (DFS)
先记录下每一种麻将出现的次数,然后枚举每一种可能得到的麻将,对于这个新的麻将牌,去判断可不可能胡,如果可以胡,就可以把这张牌输出出来. 因为eye只能有一张,所以这个是最好枚举的,就枚举每张牌成为ey ...