Elasticsearch(4)--- 基本概念(Index、Type、Document、集群、节点、分片及副本、倒排索引)
这篇博客讲到基本概念包括: Index、Type、Document。集群,节点,分片及副本,倒排索引。
一、Index、Type、Document
1、Index
index:索引是文档(Document)的容器,是一类文档的集合。
索引这个词在 ElasticSearch 会有三种意思:
1)、索引(名词)
类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库(Database)。索引由其名称(必须为全小写字符)进行标识。
2)、索引(动词)
保存一个文档到索引(名词)的过程。这非常类似于SQL语句中的 INSERT关键词。如果该文档已存在时那就相当于数据库的UPDATE。
3)、倒排索引
关系型数据库通过增加一个B+树索引到指定的列上,以便提升数据检索速度。索引ElasticSearch 使用了一个叫做 倒排索引 的结构来达到相同的目的。
2、Type
Type 可以理解成关系数据库中Table。
之前的版本中,索引和文档中间还有个类型的概念,每个索引下可以建立多个类型,文档存储时需要指定index和type。从6.0.0开始单个索引中只能有一个类型,
7.0.0以后将将不建议使用,8.0.0 以后完全不支持。
弃用该概念的原因:
我们虽然可以通俗的去理解Index比作 SQL 的 Database,Type比作SQL的Table。但这并不准确,因为如果在SQL中,Table 之前相互独立,同名的字段在两个表中毫无关系。
但是在ES中,同一个Index 下不同的 Type 如果有同名的字段,他们会被 Luecence 当作同一个字段 ,并且他们的定义必须相同。所以我觉得Index现在更像一个表,
而Type字段并没有多少意义。目前Type已经被Deprecated,在7.0开始,一个索引只能建一个Type为_doc
3、Document
Document Index 里面单条的记录称为Document(文档)。等同于关系型数据库表中的行。
我们来看下一个文档的源数据
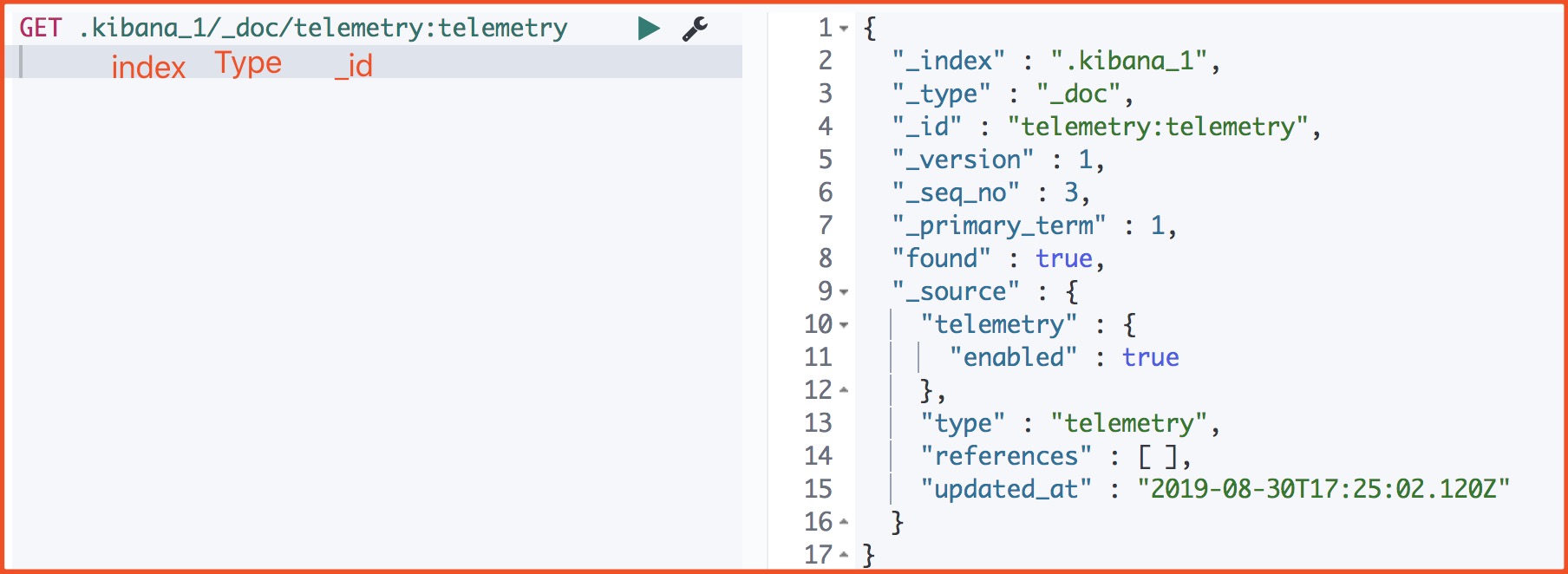
_index 文档所属索引名称。
_type 文档所属类型名。
_id Doc的主键。在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
_version 文档的版本信息。Elasticsearch通过使用version来保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失。
_seq_no 严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
primary_term primary_term也和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
found 查询的ID正确那么ture, 如果 Id 不正确,就查不到数据,found字段就是false。
_source 文档的原始JSON数据。
二、集群,节点,分片及副本
1、集群
ElasticSearch集群实际上是一个分布式系统,它需要具备两个特性:
1)高可用性
a)服务可用性:允许有节点停止服务;
b)数据可用性:部分节点丢失,不会丢失数据;
2)可扩展性
随着请求量的不断提升,数据量的不断增长,系统可以将数据分布到其他节点,实现水平扩展;
一个集群中可以有一个或者多个节点;
集群健康值
green:所有主要分片和复制分片都可用yellow:所有主要分片可用,但不是所有复制分片都可用red:不是所有的主要分片都可用
当集群状态为 red,它仍然正常提供服务,它会在现有存活分片中执行请求,我们需要尽快修复故障分片,防止查询数据的丢失;
2、节点(Node)
1)节点是什么?
a)节点是一个ElasticSearch的实例,其本质就是一个Java进程;
b)一台机器上可以运行多个ElasticSearch实例,但是建议在生产环境中一台机器上只运行一个ElasticSearch实例;
Node 是组成集群的一个单独的服务器,用于存储数据并提供集群的搜索和索引功能。与集群一样,节点也有一个唯一名字,默认在节点启动时会生成一个uuid作为节点名,
该名字也可以手动指定。单个集群可以由任意数量的节点组成。如果只启动了一个节点,则会形成一个单节点的集群。
3、分片
Primary Shard(主分片)
ES中的shard用来解决节点的容量上限问题,,通过主分片,可以将数据分布到集群内的所有节点之上。
它们之间关系
一个节点对应一个ES实例;
一个节点可以有多个index(索引);
一个index可以有多个shard(分片);
一个分片是一个lucene index(此处的index是lucene自己的概念,与ES的index不是一回事);
主分片数是在索引创建时指定,后续不允许修改,除非Reindex
一个索引中的数据保存在多个分片中(默认为一个),相当于水平分表。一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,
但是应用程序是直接与索引而不是与分片进行交互。
Replica Shard(副本)
副本有两个重要作用:
1、服务高可用:由于数据只有一份,如果一个node挂了,那存在上面的数据就都丢了,有了replicas,只要不是存储这条数据的node全挂了,数据就不会丢。因此分片副本不会与
主分片分配到同一个节点;
2、扩展性能:通过在所有replicas上并行搜索提高搜索性能.由于replicas上的数据是近实时的(near realtime),因此所有replicas都能提供搜索功能,通过设置合理的replicas
数量可以极高的提高搜索吞吐量
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划,因为主分片数是在索引创建时预先设定的,后续无法修改。
分片数设置过小
导致后续无法增加节点进行水平扩展。
导致分片的数据量太大,数据在重新分配时耗时;
分片数设置过大
影响搜索结果的相关性打分,影响统计结果的准确性;
单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
三、倒排索引
ES的搜索功能是基于lucene,而lucene搜索的基本原理就是倒叙索引,倒序排序的结果跟分词的类型有关。
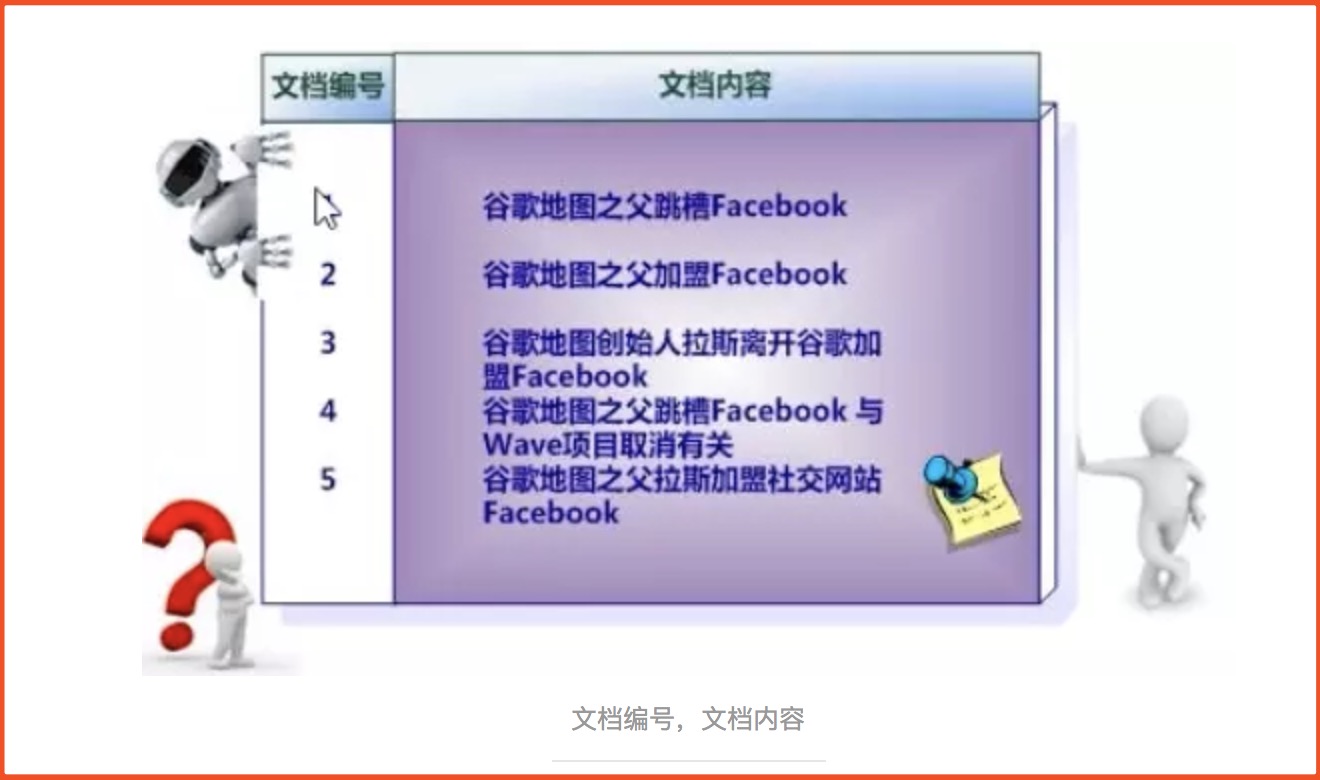
举例
1、假设文档集合包含五个文档,毎个文档内容如图所示,在图中最左端一栏是每个文档对应的文挡编号。
如图(盗图)
2、首先要用分词系统将文挡自动切分成单词序列,记录下哪些文挡包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。
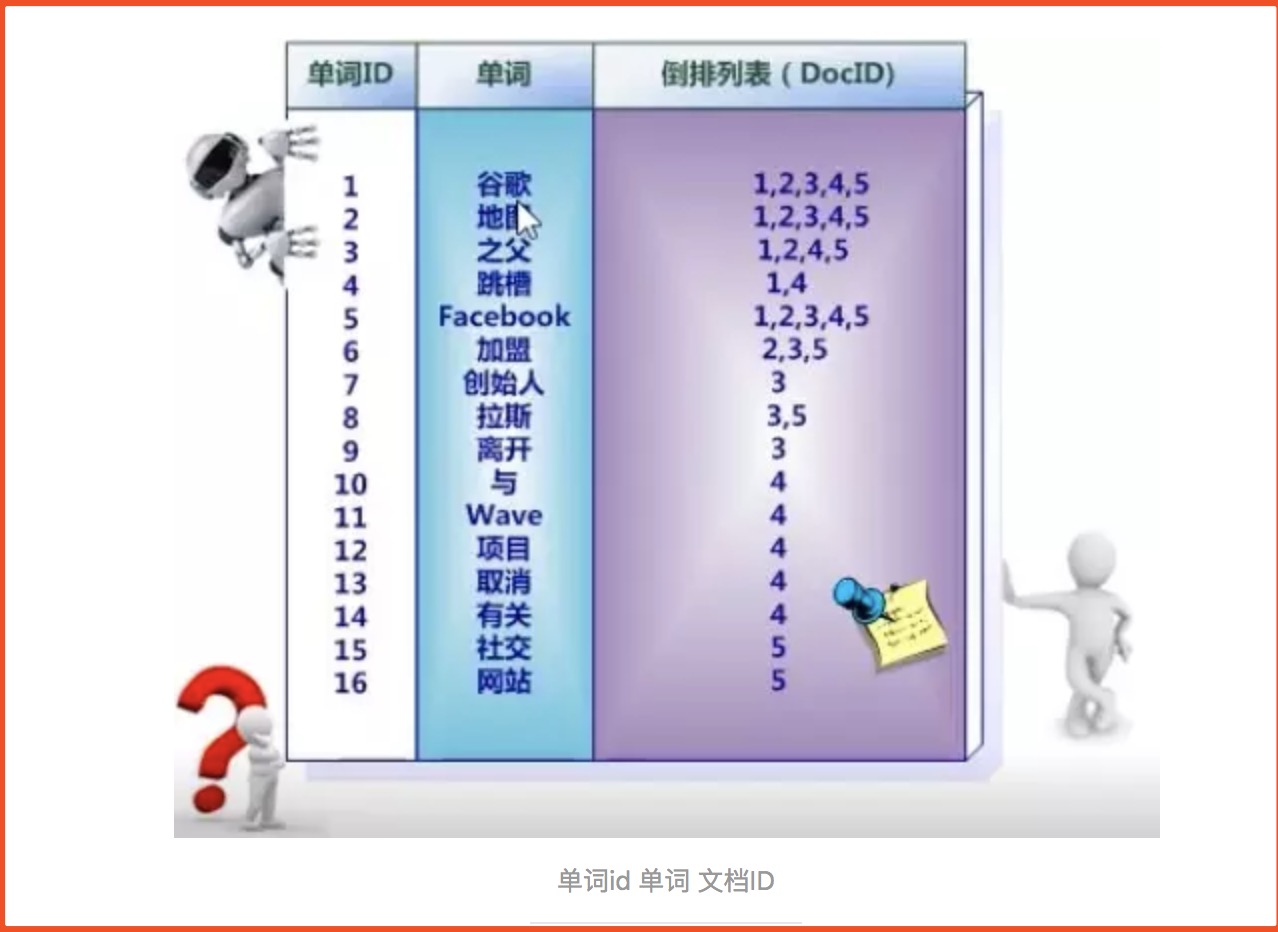
3、索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息。文档中的句子被划分为一个个term(term 用来表示一个单词或词语,取决于使用的分词方式),
倒叙索引中存储着term,term的出现频率(tf,term frequency)和出现位置(倒叙索引中的单词是按顺序排列的,这张图没有体现出来),请注意这里的文档内容是document
中的一个字段,也就是说每个被索引了的字段都有自己的倒叙索引

一次简单的搜索流程
假设我们搜索谷歌地图之父,搜索流程会是这样
- 分词,分词插件将句子分为3个term
谷歌,地图,之父 - 将这3个term拿到倒叙索引中去查找(会很高效,比如二分查找),如果匹配到了就拿对应的文档id,获得文档内容
但是,如何确定结果顺序?
这里要引入_score的概念,对于term的匹配,lucene会对其打分,得分越高,排名越靠前.这里要介绍几个相关的概念
- TF(term frequency),词频,term在当前document中出现的频率,一个term在当前document中出现5次要比出现1次更相关,打分也会更高
- IDF(inverse doucment frequency),逆向文档频率,term在所有document中出现的频率,这个频率越高,该term对应的分值越低
- 字段长度归一值,简单来说就是字段越短,字段的权重越高, 比如 term `我`在匹配 `我123`和`我123456`时,`我123`的得分会更高.Elasticsearch(4)--- 基本概念(Index、Type、Document、集群、节点、分片及副本、倒排索引)的更多相关文章
- 实例展示elasticsearch集群生态,分片以及水平扩展.
elasticsearch用于构建高可用和可扩展的系统.扩展的方式可以是购买更好的服务器(纵向扩展)或者购买更多的服务器(横向扩展),Elasticsearch能从更强大的硬件中获得更好的性能,但是纵 ...
- 集群节点Elasticsearch升级
集群节点Elasticsearch升级 操作流程 1.首先执行Elasticsearch-1.2.2集群的索引数据备份 2.关闭elasticsearch-1.2.2集群的recovery.compr ...
- [转]搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- 搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- 搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)--配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- redis(6)--redis集群之分片机制(redis-cluster)
Redis-Cluster 即使是使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的节点,形成了木桶效应.而因为Redis是基于内存 ...
- Kubernetes从懵圈到熟练:读懂这一篇,集群节点不下线
排查完全陌生的问题,完全不熟悉的系统组件,是售后工程师的一大工作乐趣,当然也是挑战.今天借这篇文章,跟大家分析一例这样的问题.排查过程中,需要理解一些自己完全陌生的组件,比如systemd和dbus. ...
- Mongodb集群与分片 1
分片集群 Mongodb中数据分片叫做chunk,它是一个Collection中的一个连续的数据记录,但是它有一个大小限制,不可以超过200M,如果超出产生新的分片. 下面是一个简单的分片集群 ...
- 删除RAC集群节点
删除GRID集群节点:参考oracle database 11g RAC手册(第二版) 目前GRID集群中节点信息:[grid@node1 ~]$ olsnodesnode1node2node3nod ...
- redis集群与分片(2)-Redis Cluster集群的搭建与实践
Redis Cluster集群 一.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Re ...
随机推荐
- 实时数仓及olap可视化构建(基于mysql,将maxwell改成seatunnel可以快速达成异构数据源实时同步)
1. OLAP可视化实现(需要提前整合版本) Linux121 Linux122 Linux123 jupyter spark python3+SuperSet3.0 hive ClinckHouse ...
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
前言 程序员的终极追求是什么?当系统流量大增,用户体验却丝滑依旧?没错!然而,在大量文件传输.数据传递的场景中,传统的"数据搬运"却拖慢了性能.为了解决这一痛点,Linux 推出了 ...
- Eclipse 调试窗口无法显示,以及断点设置无效问题的解决方法
问题描述一:在下载了2020.3的Eclipse之后,调试程序,无法弹出调试窗口及变量信息. 解决方案:菜单栏:windows--show view--Other--找到Debug文件夹,可以挑选自己 ...
- Python网络爬虫第一弹
03.Python网络爬虫第一弹<Python网络爬虫相关基础概念> 爬虫介绍 引入 之前在授课过程中,好多同学都问过我这样的一个问题:为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那 ...
- Java 并发编程实战学习笔记——CountDownLatch的使用
public class CountDownLatch extends Object 一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待. 用给定的计数 初始化 Co ...
- CAD快速图层孤立、隐藏、锁定下载
AutoCAD快速图层孤立.隐藏.锁定插件下载 链接 AutoCAD Quick Layer Isolation, Hide, Lock Plugin Download Link MAG.fas&am ...
- 使用pjsip封装自定义软电话sdk
环境: window10_x64 & vs2022pjsip版本: 2.14.1python版本: 3.9.13 近期有关于windows环境下软电话sdk开发的需求,需要开发动态库给上层应用 ...
- R数据分析:净重新分类(NRI)和综合判别改善(IDI)指数的理解
对于分类预测模型的表现评估我们最常见的指标就是ROC曲线,报告AUC.比如有两个模型,我们去比较下两个模型AUC的大小,进而得出两个模型表现的优劣.这个是我们常规的做法,如果我们的研究关注点放在&qu ...
- 《Django 5 By Example》读后感
一. 为什么选择这本书? 本人的工作方向为Python Web方向,想了解下今年该方向有哪些新书出版,遂上packt出版社网站上看了看,发现这本书出版时间比较新(2024年9月),那就它了. 从202 ...
- JVM 语言的探索发现
又在 WIKI 上溜达了一下 https://en.wikipedia.org/wiki/List_of_JVM_languages,有一些新的发现: ColdFusion Markup Langua ...