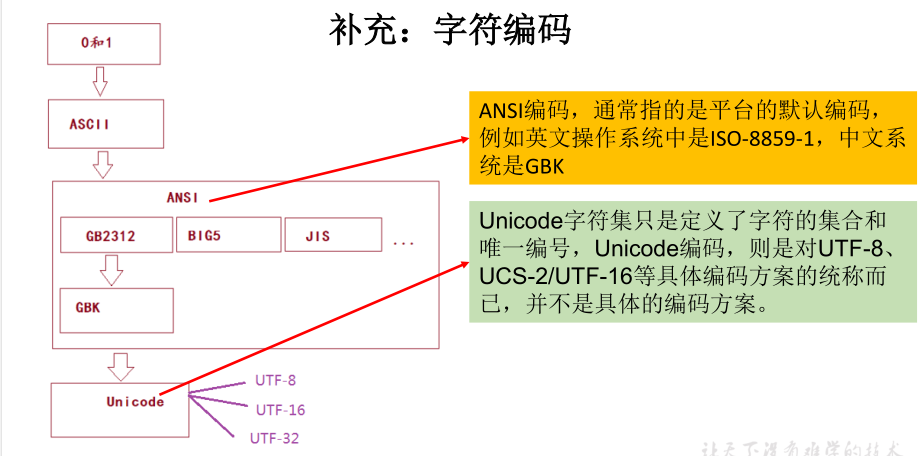
补充:字符编码ASCII、 ISO8859-1、GB2312、GBK、Unicode、UTF-8
补充:字符编码
编码表的由来
计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识
别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表。
这就是编码表。
常见的编码表
ASCII:美国标准信息交换码。
用一个字节的7位可以表示。
ISO8859-1:拉丁码表。欧洲码表
用一个字节的8位表示。
GB2312:中国的中文编码表。最多两个字节编码所有字符
GBK:中国的中文编码表升级,融合了更多的中文文字符号。最多两个字节编码
Unicode:国际标准码,融合了目前人类使用的所有字符。为每个字符分配唯一的
字符码。所有的文字都用两个字节来表示。
UTF-8:变长的编码方式,可用1-4个字节来表示一个字符。


Unicode不完美,这里就有三个问题,一个是,我们已经知道,英文字母只用
一个字节表示就够了,第二个问题是如何才能区别Unicode和ASCII?计算机
怎么知道两个字节表示一个符号,而不是分别表示两个符号呢?第三个,如果
和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,
就少了很多值无法用于表示字符,不够表示所有字符。Unicode在很长一段时
间内无法推广,直到互联网的出现。
面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-
8就是每次8个位传输数据,而UTF-16就是每次16个位。这是为传输而设计的
编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯
一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的
Unicode编码是UTF-8和UTF-16。



编码: 字符串------字节数组
解码: 字节数组-----字符串
转换流的编码应用
可以将字符按指定编码格式存储
可以对文本数据按指定编码格式来解读
指定编码表的动作由构造器完成
补充:字符编码ASCII、 ISO8859-1、GB2312、GBK、Unicode、UTF-8的更多相关文章
- 关于字符编码精简介绍 ANSI GB2312 UTF8 UNICODE
- 彻底搞清楚字符编码: ASCII, ISO_8859, GB2312,UCS, Unicode, Utf-8
彻底搞清楚字符编码: ASCII, ISO_8859, GB2312,UCS, Unicode, U 1.ASCII: 0-127(128-255未使用),美国标准 2.IS0-8859-1(lati ...
- BIG5, GB(GB2312, GBK, ...), Unicode编码, UTF8, WideChar, MultiByte, Char说明与区别
汉语unicode编译方式,BIG5是繁体规范,GB是简体规范 GB是大陆使用的国标码,BIG5码,又叫大五码,是台湾使用的繁体码. BIG5编码, GB编码(GB2312, GBK, ...), U ...
- 字符编码,pyton中的encode,decode,unicode()
1.在计算机处理的程序中,对字符的处理有两种方式:编码或译码(encoding),解码(decoding) encoding:将字符串中的字符转换到对应编码字符集对应的代码点 ...
- 字符编码-ASCII,GB2312,GBK,GB18030
ASCII ASCII,GB2312,GBK,GB18030依次增加,向下兼容. 手机只需要支持GB2312 电脑中文windows只支持GBK 发展历程 如果你使用编译器是python2.0版本,默 ...
- 字符编码ascii、unicode、utf-‐8、gbk 的关系
ASIIC码: 计算机是美国人发明和最早使用的,他们为了解决计算机处理字符串的问题,就将数字字母和一些常用的符号做成了一套编码,这个编码就是ASIIC码.ASIIC码包括数字大小写字母和常用符号,一共 ...
- 字符编码之间的相互转换 UTF8与GBK(转载)
转载自http://www.cnblogs.com/azraelly/archive/2012/06/21/2558360.html UTF8与GBK字符编码之间的相互转换 C++ UTF8编码转换 ...
- 字符编码ASCII、Unicode、GB
计算机的存储都是二进制的,那么我们平时看到的各种字符都需要通过按照一定的格式转换成为二进制才能在被计算机识别与处理.这个过程便成为编码.常见的编码方式有ASCII.Unicode.GB2312等. 1 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码 ASCII,Unicode 和 UTF-8 概念扫盲
今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步搞清楚. 下面就是我的笔记,主要用来整理自己的思 ...
随机推荐
- 使用越来越广泛的2FA双因素认证,缘何越发受到推崇?
大家好,我是vzn呀,又见面了. 随着互联网在生活方方面面的应用,日常少不了要登录各个网站或者应用.或者是银行转账等需要验证自己身份的场景.从早期的输入账号密码来登录,到后来普遍开始通过手机验证码进行 ...
- JDBC批处理Select语句
本文由 ImportNew - 刘志军 翻译自 Javaranch.如需转载本文,请先参见文章末尾处的转载要求. 注:为了更好理解本文,请结合原文阅读 在上一篇文章中提到了PreparedStatem ...
- 13TB的StarRocks大数据库迁移过程
公司有一套StarRocks的大数据库在大股东的腾讯云环境中,通过腾讯云的对等连接打通,通过dolphinscheduler调度datax离线抽取数据和SQL计算汇总,还有在大股东的特有的Flink集 ...
- 整合Sleuth
Sleuth是 springcloud 分布式跟踪解决方案. Sleuth 术语: 跨度(span ) :Sleuth 的基本工作单元,他用一个64位的id唯一标识.出ID外,span还包含 其他的数 ...
- C#生成二维码的两种方式(快看二维码)
前言 最近在做项目的时候遇到一个需求是将文本内容生成二维码图片的,对于这个需求那就直接上手(两种方法,我比较喜欢第二种方式,往上面也是有很多的方法.这里只作为个人纪录) 方法一:ThoughtWork ...
- PictureMarkerSymbol透明的问题
由于我使用的是位图图片,所以不可能将图片背景处理成透明.不过还是可以通过参数的设定来达到这种效果. PictureMarkerSymbol pPMS = new PictureMarkerSymbol ...
- R数据分析:cox模型如何做预测,高分文章复现
今天要给大家分享的文章是 Cone EB, Marchese M, Paciotti M, Nguyen DD, Nabi J, Cole AP, Molina G, Molina RL, Minam ...
- 中电金信:加快企业 AI 平台升级,构建金融智能业务新引擎
在当今数字化时代的浪潮下,人工智能(AI)技术的蓬勃发展正为各行业带来前所未有的变革与创新契机.尤其是在金融领域,AI 模型的广泛应用已然成为提升竞争力.优化业务流程以及实现智能化转型的关键驱动力 ...
- JavaWeb HttpSession
/** * 使用session共享数据 */ public class SessionDemo1 extends HttpServlet { @Override protected void doPo ...
- Qt编写地图综合应用44-悬浮工具条
一.前言 百度地图内置了悬浮工具条,可以自行开启,包括离线地图也可以开启,用到了DrawingManager这个库,鼠标绘制工具条库,提供鼠标绘制点.线.面.多边形(矩形.圆)的编辑工具条的开源代码库 ...