AI 实践|零成本生成SEO友好的TDK落地方案
之前写过一篇文章「Google搜索成最大入口,简单谈下个人博客的SEO」,文章里介绍了网页的描述信息TDK(Title、Description和Keywords)对SEO的重要作用,尽管已经意识到了TDK能够直接影响到SEO的效果,但仍存在随意编写或忽略的情况,究其原因,第一是懒散,嫌麻烦,第二是不懂,随便写写效果不佳。曾经幻想有一个工具既能读懂文章的意思,又对SEO比较的了解,可以根据文章内容自动生成SEO友好的TDK,一直以来也仅仅是幻想,但随着AI的出现,随着GPT的普及,让这件原本几乎不太可能实现的事情也变得容易了很多
写好文章丢给GPT,再配上一段提示词,GPT就能根据文章的内容生成SEO友好的slug、title、keywords和description等信息,例如我把上篇文章「 全程使用 AI 从 0 到 1 写了个小工具」的内容丢给DeepSeek,让他从SEO友好的角度生成文章的TDK等信息

可以看到DeepSeek生成的内容确实十分的专业,利用AI生成SEO友好的TDK已然可以实现了。虽然功能能够实现,但每次都要复制文章内容给GPT,还是麻烦的,于是考虑借助API来实现自动化,许多AI模型都有提供API,但几乎全都收费,提供API还免费的不多,调研了一圈,决定试用硅基流动,主要原因是当前邀请注册送2000万Token,同时也支持Json格式输出,这对于我后续要拿到数据做自动化处理可太重要了。也想试用的朋友可以用我的推荐链接注册或是填写我的推荐码:tqPo40nB,这样就能免费获得2000万的Token
实际体验下来2000万的Token根本用不完,我300多篇文章近60万字,加上前期的调试调用,全部文章重新生成一遍SEO友好的描述信息,也就用了大概180万Token,用不完,根本用不完
过程
大概的实现流程是,调用AI的API,把文章内容喂它,同时让它输出Json格式的结果,我们拿到结果之后,把相应的TDK描述信息例如Keywords和Description写入数据库,然后再调用生成程序把文章连带这些描述生成HTML文件,最后上传到github自动发布,整个流程就算完成了。这其中基本的流程我的博客后台程序都已经是实现好的,需要修改的主要就是根据文章内容,调用AI来生成SEO友好的描述信息,然后把这些信息写入数据库。具体的实现过程很简单,主要就两步,以我用的硅基流动平台为例
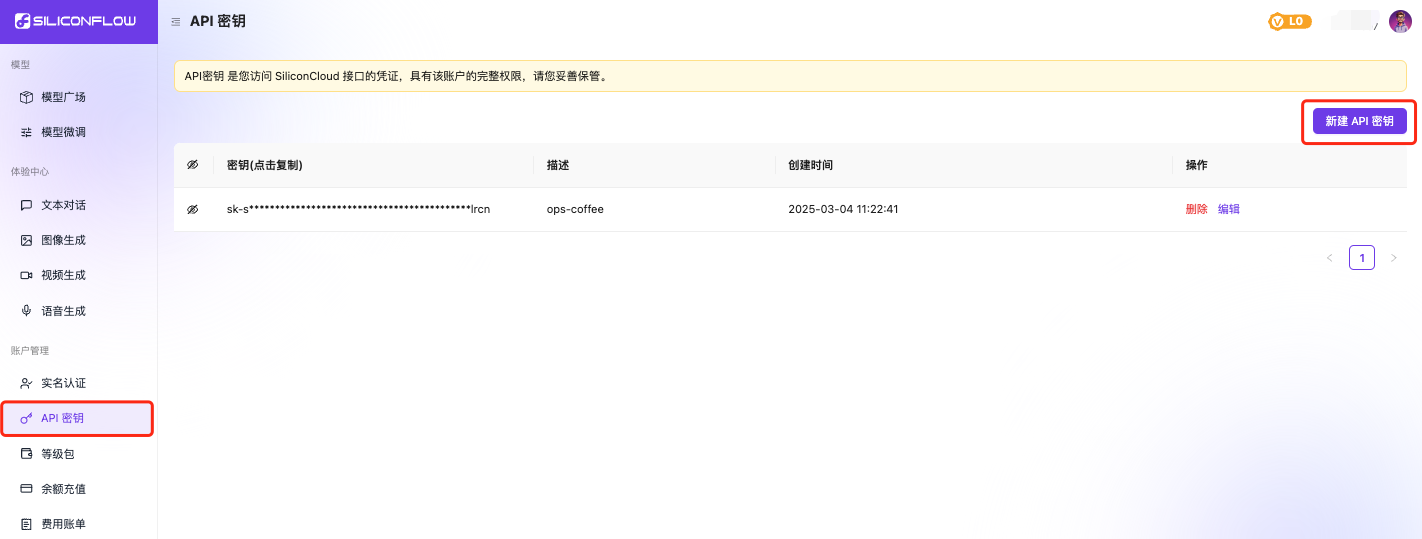
首先去注册平台账号并登录,登录之后点击页面左侧的API密钥-新建API密钥,填写描述信息了之后就创建了一个API密钥
然后就可以调用API传入文章内容+需求让他生成数据,硅基流动它不是具体的某个模型,而是提供了一个模型市场,这个模型市场里的模型都可以调用,部分模型支持openai库进行调用,这样就比较方便,我们通过python调用,需要Python版本高于3.7.1,在调用之前先安装openai库,执行如下命令:
pip install --upgrade openai
安装完成后,就可以调用,一个简单的调用示例如下:
import json
from openai import OpenAI
def generate_seo_data(content):
client = OpenAI(
api_key="sk-xxxxxxxx", # 替换成自己的密钥
base_url="https://api.siliconflow.cn/v1"
)
try:
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": f"? 以下是一篇markdown格式的文章,请根据文章内容从SEO友好的角度提取出slug、title、keywoards和description,至少10个keywords,要列表格式:{content}"
"Please respond in the format {\"slug\": ..., \"title\": ..., \"keywords\": ..., \"description\": ...}"}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
except Exception as e:
print("Error generating SEO data:", str(e))
return {"slug": "", "title": "", "keywords": [], "description": ""}
把代码里的api_key替换成第一步里生成的key,稍微调整下content的内容就可以为你所用。输出的结果就是这样的
>>> blog = Blog.objects.get(title='运维自动化系统各模块介绍')
>>> seo_data = generate_seo_data(blog.content)
>>>
>>> seo_data.get('slug')
'devops-automation-platform-overview'
>>>
>>> seo_data.get('title')
'运维自动化平台功能模块全面解析'
>>>
>>> seo_data.get('keywords')
['运维自动化', '资产管理', '容器管理', '监控告警', '作业系统', '任务系统', '域名管理', '备份系统', '数据库服务', '费用中心', '审计中心', '用户管理']
>>>
>>> seo_data.get('description')
'本文从整体视角介绍了一个较为完善的运维自动化系统包含的主要功能模块,包括工作台、资产管理、容器管理、监控告警、作业系统、任务系统、域名管理、备份系统、数据库服务、费用中心、审计中心和用户管理,详细解析每个模块如何解决实际运维中的问题。
然后我只需要把这些输出的数据保存到数据库,会自动触发页面生成方法并上传,整个流程就完成了
后记
当初找了好久的工具尝试了很多的方法来实现SEO友好型TDK信息的自动生成,始终没有很好的方案,现在终于找到了完美的方式来解决这个问题,但如今已经进入AI的时代,传统网站加速走向没落变成了一个不争的事实,那即便是生成再完美的TDK,做再好的SEO,意义还大吗
AI用的越多,越是感叹其强大,同时带来的打击也越大
AI 实践|零成本生成SEO友好的TDK落地方案的更多相关文章
- Google Colab——零成本玩转深度学习
前言 最近在学深度学习HyperLPR项目时,由于一直没有比较合适的设备训练深度学习的模型,所以在网上想找到提供模型训练,经过一段时间的搜索,最终发现了一个谷歌的产品--Google Colabora ...
- ASP.NET的SEO: 服务器控件背后——SEO友好的Html和JavaScript
本系列目录 假设你需要从一个页面转向其他页面,下面有很多种方式,你是如何选择的呢?你能清晰的说明理由么? <%--链接的表现形式--%> <asp:Hy ...
- 如何利用开源思想开发一个SEO友好型网
如果你有一个网站需要去做SEO优化的时候,不要期望你的努力能立即得到回报.耐心等待并更正内容营销策略,最终会发现你的网站很受用户欢迎.下面就教你如何利用开源思维开发一个SEO友好型网站! 首先,你应该 ...
- 零成本搭建个人博客之图床和cdn加速
本文属于零成本搭建个人博客指南系列 为什么要使用图床 博客文章中的图片资源文件一般采用本地相对/绝对路径引用,或者使用图床通过外链进行引用展示.本地引用的弊端我认为在于: 图片和博客放在同一个代码托管 ...
- ajax 如何做到 SEO 友好
我猜你是在网络上搜索“ajax如何被搜索引擎收录”.“ajax SEO”.“ajax SEO友好”等关键词来到这里的.你可能已经很疲惫了,因为前段时间我也这样搜索,但是我发现搜索到的内容质量不高,有的 ...
- Oracle EBS-SQL (CST-3):检查零成本交易.sql
SELECT '零成本交易' 交易异常类型 ,msi.segment1 ...
- 零成本实现Android/iOS自动化测试:基于Appium和Test Perfect
https://item.taobao.com/item.htm?spm=a230r.1.14.14.42KJ3L&id=527677900735&ns=1&abbucket= ...
- 用AI思维给成本降温,腾讯WeTest兼容性测试直击底价!
WeTest 导读 当AI成为各行业提高产业效率的动能,很多人开始疑惑,这架智能化的“无人机”何时在移动应用测试中真正落地?在今年的国际数码互动娱乐博览会(ChinaJoy)上,腾讯WeTest给出了 ...
- 使用syncthing和蒲公英异地组网零成本实现多设备实时同步
设想一个场景,如果两台电脑之间可以共享一个文件夹,其中一个增删更改其中的内容时,另一个也能同步更新,而且速度不能太慢,最好是免费的.那么syncthing就可以满足这个要求.syncthing可以实现 ...
- Web前端开发最佳实践(7):使用合理的技术方案来构建小图标
大家都对网站上使用的小图标肯定都不陌生,这些小图标作为网站内容的点缀,增加了网站的美观度,提高了用户体验,可是你有没有看过在这些网站中使用的图标都是用什么技术实现的?虽然大部分网站还是使用普通的图片实 ...
随机推荐
- drf知识点
目录 drf知识点 1.web应用模式.API接口.接口测试工具postman.restful规范 2.序列化与反序列化的概念.基于django原生编写5个接口.drf介绍和快速使用.cbv源码分析 ...
- 2024年1月Java项目开发指南3:创建Springboot项目
本文档编写于贰零贰肆年一月八日@萌狼蓝天 如果你不知道什么是springboot,那么你只需要知道,这是一个让我们减少配置工作量,方便开发的开发框架,能让我们更专心于业务开发,省的被各种各样的配置浪费 ...
- SpringBoot项目请求路径中有正反斜杠的处理办法
在Application中添加静态代码块: //默认情况下Tomcat等服务器是拒绝url中带%2F或者%5C的URL,因为它们经浏览器解析之后就变成了/和\, // 服务器默认是拒绝访问的,所以需要 ...
- 开源即时通讯IM框架 MobileIMSDK v6.2 发布
一.更新内容简介 本次更新为次要版本更新,进行了若干优化(更新历史详见:码云 Release Nodes).可能是市面上唯一同时支持 UDP+TCP+WebSocket 三种协议的同类开源IM框架. ...
- ArrayList源码解析-JDK18
引言 ArrayList在JDK1.7和1.8中的差距并不大,主要差距以下几个方面: JDK1.7 在JDK1.7中,使用ArrayList list = new ArrayList()创建List集 ...
- Solution -「GLR-R4」大暑
\(\mathscr{Description}\) Link. 这里有兔以前写的另一个题意,大家可以参考着看看. 你有两个坐标集合 \(X,Y\),\(X=\{(0,y)\mid y\in ...
- Spring Boot 如何使用拦截器、过滤器、监听器
过滤器的使用 首先需要实现 Filter接口然后重写它的三个方法 init 方法:在容器中创建当前过滤器的时候自动调用 destory 方法:在容器中销毁当前过滤器的时候自动调用 doFilter 方 ...
- linux:正则表达式
介绍 一种模式匹配语言,可以使永远筛选数据以查找特定的内容,可以应用在vim.grep.less.perl.python中 基础 .(点) 匹配除 \n 之外的任何单个字符,若要匹配包括 \n ,则应 ...
- Go语言【Gin框架】:JSON、AsciiJSON、PureJSON和SecureJSON的区别
在Go语言中,JSON.AsciiJSON.PureJSON 和 SecureJSON 是Gin框架用于发送JSON响应的方法. 1. c.JSON 功能:将提供的数据序列化为标准的JSON格式,并将 ...
- 云电脑:DPU简介及分析
本文分享自天翼云开发者社区<云电脑:DPU简介及分析>,作者:大利 随着云计算技术的快速发展,云电脑作为一种基于云计算技术的虚拟化电脑,正在逐渐受到广泛关注.然而,云电脑在实现过程中面临着 ...