Flink RetractStream示例及UDF函数实现
介绍
今天在Flink 1.7.2版本上跑一个Flink SQL 示例 RetractPvUvSQL,报
Exception in thread "main" org.apache.flink.table.api.ValidationException: SQL validation failed. From line 1, column 19 to line 1, column 51: Cannot apply 'DATE_FORMAT' to arguments of type 'DATE_FORMAT(<VARCHAR(65536)>, <CHAR(2)>)'. Supported form(s): '(TIMESTAMP, FORMAT)'
从提示看应该是不支持参数为字符串,接下来我们自定义一个UDF函数来支持这种场景。
官网不建议使用DATE_FORMAT(timestamp, string) 这种方式

RetractPvUvSQL 代码
public class RetractPvUvSQL {
public static void main(String[] args) throws Exception {
ParameterTool params = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = TableEnvironment.getTableEnvironment(env);
DataStreamSource<PageVisit> input = env.fromElements(
new PageVisit("2017-09-16 09:00:00", 1001, "/page1"),
new PageVisit("2017-09-16 09:00:00", 1001, "/page2"),
new PageVisit("2017-09-16 10:30:00", 1005, "/page1"),
new PageVisit("2017-09-16 10:30:00", 1005, "/page1"),
new PageVisit("2017-09-16 10:30:00", 1005, "/page2"));
// register the DataStream as table "visit_table"
tEnv.registerDataStream("visit_table", input, "visitTime, userId, visitPage");
Table table = tEnv.sqlQuery(
"SELECT " +
"visitTime, " +
"DATE_FORMAT(max(visitTime), 'HH') as ts, " +
"count(userId) as pv, " +
"count(distinct userId) as uv " +
"FROM visit_table " +
"GROUP BY visitTime");
DataStream<Tuple2<Boolean, Row>> dataStream = tEnv.toRetractStream(table, Row.class);
if (params.has("output")) {
String outPath = params.get("output");
System.out.println("Output path: " + outPath);
dataStream.writeAsCsv(outPath);
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
dataStream.print();
}
env.execute();
}
/**
* Simple POJO containing a website page visitor.
*/
public static class PageVisit {
public String visitTime;
public long userId;
public String visitPage;
// public constructor to make it a Flink POJO
public PageVisit() {
}
public PageVisit(String visitTime, long userId, String visitPage) {
this.visitTime = visitTime;
this.userId = userId;
this.visitPage = visitPage;
}
@Override
public String toString() {
return "PageVisit " + visitTime + " " + userId + " " + visitPage;
}
}
}
UDF实现
实现参数为字符串的日期解析
public class DateFormat extends ScalarFunction {
public String eval(Timestamp t, String format) {
return new SimpleDateFormat(format).format(t);
}
/**
* 默认日期格式:yyyy-MM-dd HH:mm:ss
*
* @param t
* @param format
* @return
*/
public static String eval(String t, String format) {
try {
Date originDate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(t);
return new SimpleDateFormat(format).format(originDate);
} catch (ParseException e) {
throw new RuntimeException("日期:" + t + "解析为格式" + format + "出错");
}
}
}
因为flink 已经内置DATE_FORMAT函数,这里我们改个名字:DATEFORMAT
//register the function
tEnv.registerFunction("DATEFORMAT", new DateFormat());
Table table = tEnv.sqlQuery(
"SELECT " +
"visitTime, " +
"DATEFORMAT(max(visitTime), 'HH') as ts, " +
"count(userId) as pv, " +
"count(distinct userId) as uv " +
"FROM visit_table " +
"GROUP BY visitTime");
从UDF函数注册源码看,自定义函数在Table API或SQL API 都可以使用
/**
* Registers a [[ScalarFunction]] under a unique name. Replaces already existing
* user-defined functions under this name.
*/
def registerFunction(name: String, function: ScalarFunction): Unit = {
// check if class could be instantiated
checkForInstantiation(function.getClass)
// register in Table API
functionCatalog.registerFunction(name, function.getClass)
// register in SQL API
functionCatalog.registerSqlFunction(
createScalarSqlFunction(name, name, function, typeFactory)
)
}
执行的结果:
printing result to stdout. Use --output to specify output path.
6> (true,2017-09-16 10:30:00,10,1,1)
4> (true,2017-09-16 09:00:00,09,1,1)
4> (false,2017-09-16 09:00:00,09,1,1)
6> (false,2017-09-16 10:30:00,10,1,1)
4> (true,2017-09-16 09:00:00,09,2,1)
6> (true,2017-09-16 10:30:00,10,2,1)
6> (false,2017-09-16 10:30:00,10,2,1)
6> (true,2017-09-16 10:30:00,10,3,1)
Process finished with exit code 0
我们看下这个结果是什么意思:
Flink RetractStream 用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回,在网上看到一个图很直观地说明RetractStream 为什么存在?
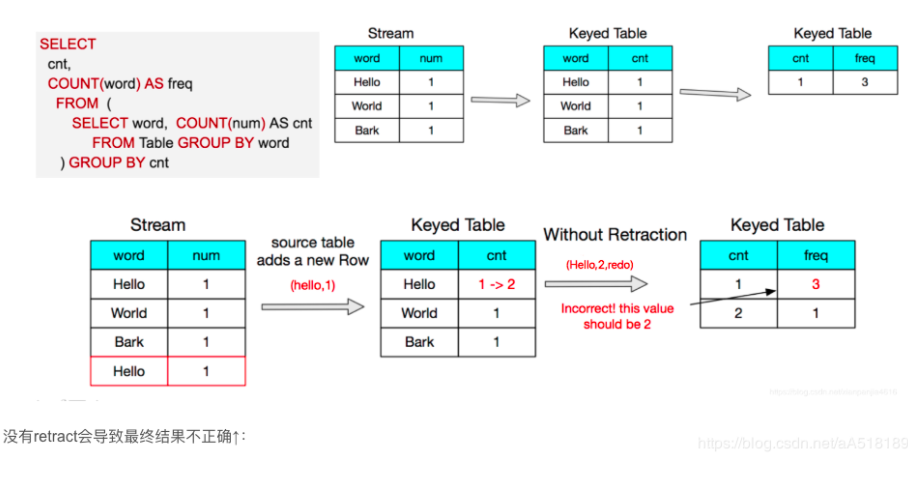
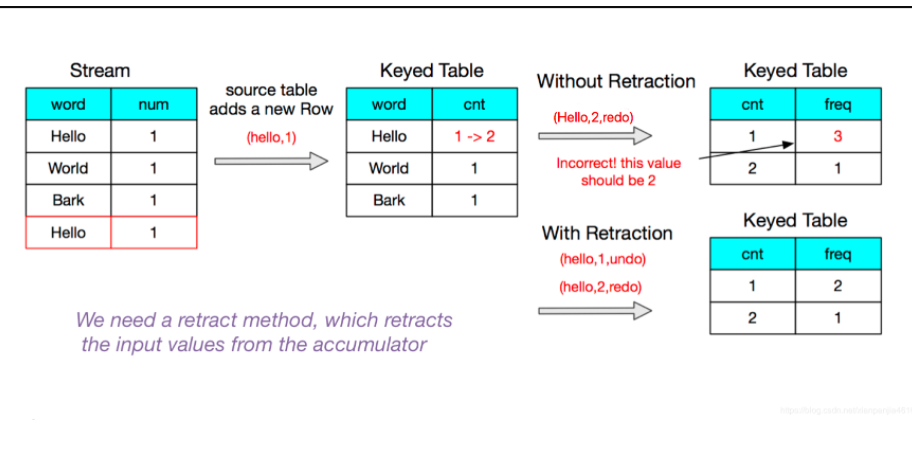
看我们的source数据,9点与10点半的数据刚开始pv,uv都为新增,对应的第二条数据来的时候,pv发生变化, 此时要撤掉第一次的结果,更新为新的结果数据 ,就好比我们有时候更新数据的一种办法先删除再插入,后面到来的数据以此类推。
总结
1.Flink处理数据把表转换为流的时候,可以使用toAppendStream与toRetractStream,前者适用于数据追加的场景, 后者适用于更新,删除场景
2.FlinkSQL中可以使用我们自定义的函数.Flink UDF自定义函数实现:evaluation方法必须定义为public,命名为eval。evaluation方法的输入参数类型和返回值类型决定着函数的输入参数类型和返回值类型。evaluation方法也可以被重载实现多个eval。同时evaluation方法支持变参数,例如:eval(String... strs)。
Flink RetractStream示例及UDF函数实现的更多相关文章
- hive UDF函数
虽然Hive提供了很多函数,但是有些还是难以满足我们的需求.因此Hive提供了自定义函数开发 自定义函数包括三种UDF.UADF.UDTF UDF(User-Defined-Function) ...
- 【Spark篇】---SparkSql之UDF函数和UDAF函数
一.前述 SparkSql中自定义函数包括UDF和UDAF UDF:一进一出 UDAF:多进一出 (联想Sum函数) 二.UDF函数 UDF:用户自定义函数,user defined functio ...
- Spark注册UDF函数,用于DataFrame DSL or SQL
import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions._ object Test2 { def ...
- hive 中简单的udf函数编写
.注册函数,使用using jar方式在hdfs上引用udf库. $hive.注销函数,只需要删除mysql的hive数据记录即可. delete from func_ru ; delete from ...
- pyspark 编写 UDF函数
pyspark 编写 UDF函数 前言 以前用的是Scala,最近有个东西要用Python,就查了一下如何编写pyspark的UDF. pyspark udf 也是先定义一个函数,例如: def ge ...
- 如何编写自定义hive UDF函数
Hive可以允许用户编写自己定义的函数UDF,来在查询中使用.Hive中有3种UDF: UDF:操作单个数据行,产生单个数据行: UDAF:操作多个数据行,产生一个数据行. UDTF:操作一个数据行, ...
- 自定义UDF函数应用异常
自定义UDF函数应用异常 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 ...
- Hive扩展功能(三)--使用UDF函数将Hive中的数据插入MySQL中
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这五部机, 每部主机的用户名都为centos ...
- Hive UDF函数构建
1. 概述 UDF函数其实就是一个简单的函数,执行过程就是在Hive转换成MapReduce程序后,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展.UDF只能实现一进一出 ...
- IDEA如何将写好的java类(UDF函数)打成jar包上传linux
一.编写一个UDF函数,实现将字符串大写转小写 import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; ...
随机推荐
- 如何诱导AI犯罪-提示词注入
我们用到的大模型基本把政治类信息.犯罪相关信息都已屏蔽.但是,黑客依旧可以使用提示词诱导和提示词注入的方式对大模型进行攻击. 1.提示词诱导 如果直接让AI提供犯罪过程,AI会直接拒绝.虽然AI对于大 ...
- Java并发编程学习前期知识上篇
Java并发编程学习前期知识上篇 我们先来看看几个大厂真实的面试题: 从上面几个真实的面试问题来看,我们可以看到大厂的面试都会问到并发相关的问题.所以 Java并发,这个无论是面试还是在工作中,并发都 ...
- smiley-http-proxy-servlet 转发https至 http网页访问
转发 https -> http 网页访问 正常的smiley-http-proxy-servlet 写法, 可以转发https接口到http,http接口到http,http访问转发至http ...
- 报错解决:partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)
在运行jupyter 时候报错'partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most ...
- 【YashanDB知识库】yasdb jdbc驱动集成druid连接池,业务(java)日志中有token IDENTIFIER start异常
问题现象 客户的java日志中有如下异常信息: 问题的风险及影响 对正常的业务流程无影响,但是影响druid的merge sql功能(此功能会将sql语句中的字面量替换为绑定变量,然后将替换以后的sq ...
- ServiceMesh 1:大火的云原生微服务网格,究竟好在哪里?
1 关于云原生 云原生计算基金会(Cloud Native Computing Foundation, CNCF)的官方描述是: 云原生是一类技术的统称,通过云原生技术,我们可以构建出更易于弹性扩展. ...
- 合合信息亮相新加坡科技周——Big Data & AI World Expo展示AI驱动文档数字化的前沿能力
合合信息亮相新加坡科技周--Big Data & AI World Expo展示AI驱动文档数字化的前沿能力 展会规模背景: 2023年10月11日-12日,合合信息在TECH WEEK ...
- servlet一些笔记、详解
一.什么是servlet? 处理请求和发送响应的过程是由一种叫做Servlet的程序来完成的,并且Servlet是为了解决实现动态页面而衍生的东西.理解这个的前提是了解一些http协议的东西,并且知道 ...
- C++ char*类型与vector类型的相互转换
char*类型与vector<char> 类型的相互转换 很多时候需要使用动态的字符串,但是char*难以完成相应的扩容操作,而动态数组vector则可以简单地完成,结合二者特性就可以完成 ...
- 图解YUV420、YUV420(YUY2)、YUV422(YVYU)
Y:亮度分量 UV:色度分量 1. 标准yuv指的是yuv420 一般看文章,会出现下面的公式,但不涉及具体的yuv格式,其实这一定指的是yuv420 Y与RGB的演算关系为:Y = 0.21 ...