python,爬取小说网站小说内容,同时每一章存在不同的txt文件中
思路,第一步小说介绍页获取章节地址,第二部访问具体章节,获取章节内容
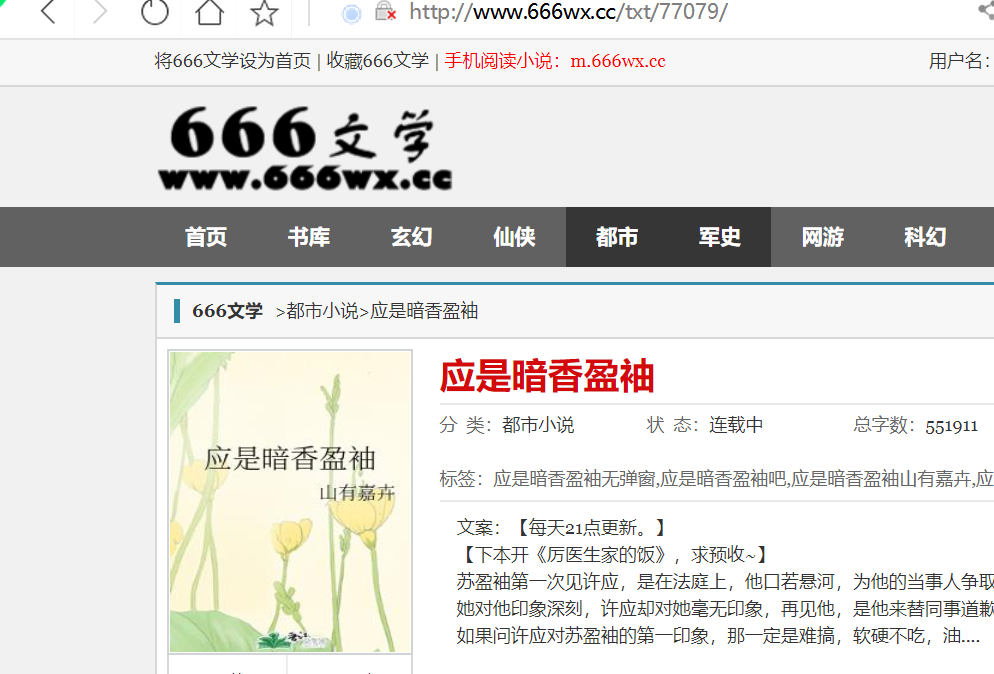
具体如下:先获取下图章节地址

def stepa(value,headers):
lit=[]
response = requests.get(value, headers=headers)
html = etree.HTML(response.text)
url = html.xpath('//*[@id="chapterlist"]//@href')#获取每章地址
lit.append(url)
return(lit)
add=stepa(value,headers)
allurl=add[0]#去掉括号
上方代码可获取到下图红色区域内内容,即每一章节地址的变量部分,且全部存在脚本输出的集合中
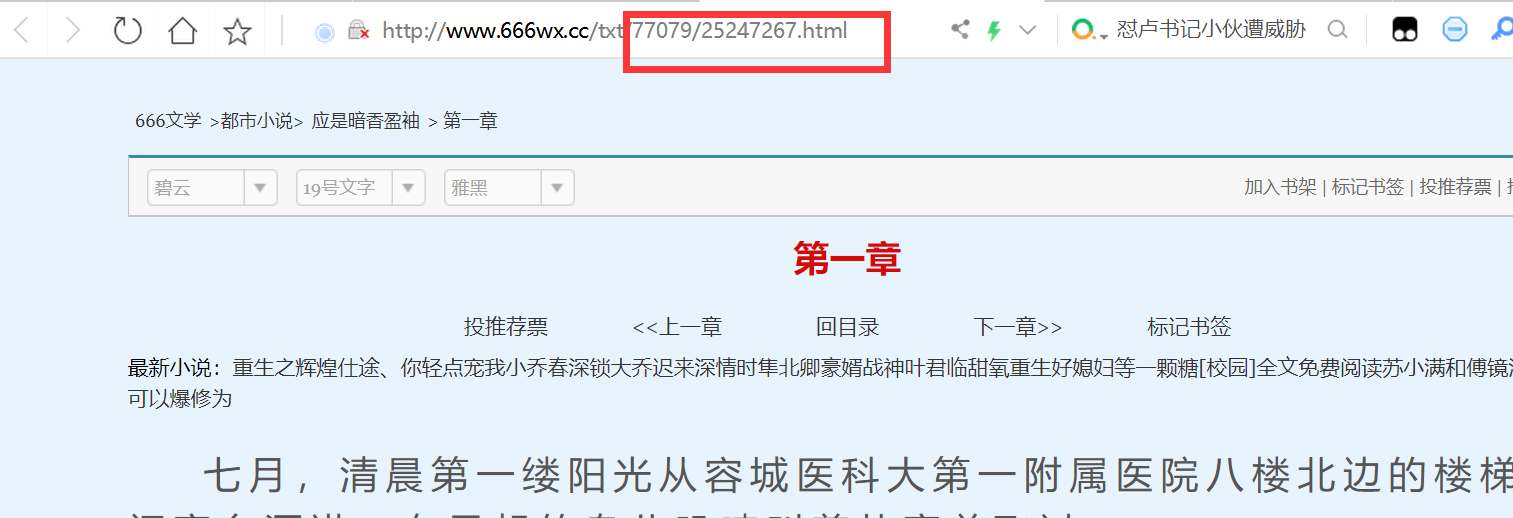
第二部,循环访问集合中的章节地址,获取章节内容,同时逐行存储在对应章节命名的txt文件中
for link in allurl:
link = 'http://www.666wx.cc'+link#拼接地址,可访问
response = requests.get(link, headers=headers)
html = etree.HTML(response.text)
name = html.xpath('//*[@id="center"]/div[1]/h1/text()')#章节
name =name[0]
content = html.xpath('//*[@id="content"]/text()')#章节内容
for 内容 in content:
内容 = 内容.strip()#去掉每行后的换行符
with open(path+'\\'+str(name)+'.txt', 'a',encoding='utf-8') as w:
w.write(str(内容))
w.close()
生成的文件一览
txt内容
全部脚本
# -*-coding:utf8-*-
# encoding:utf-8
#本脚本爬取http://www.666wx.cc站小说
import requests
from lxml import etree
import os
import sys
import re headers = {
'authority': 'cl.bc53.xyz',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__cfduid=d9b8dda581516351a1d9d388362ac222c1603542964',
} value = "http://www.666wx.cc/txt/77079/"#小说地址 path = os.path.abspath(os.path.dirname(sys.argv[0])) def stepa(value,headers):
lit=[]
response = requests.get(value, headers=headers)
html = etree.HTML(response.text)
url = html.xpath('//*[@id="chapterlist"]//@href')#获取每章地址
lit.append(url)
return(lit)
add=stepa(value,headers)
allurl=add[0]#去掉括号
for link in allurl:
link = 'http://www.666wx.cc'+link#拼接地址,可访问
response = requests.get(link, headers=headers)
html = etree.HTML(response.text)
name = html.xpath('//*[@id="center"]/div[1]/h1/text()')#章节
name =name[0]
content = html.xpath('//*[@id="content"]/text()')#章节内容
for 内容 in content:
内容 = 内容.strip()#去掉每行后的换行符
with open(path+'\\'+str(name)+'.txt', 'a',encoding='utf-8') as w:
w.write(str(内容))
w.close()
print("ok")
python,爬取小说网站小说内容,同时每一章存在不同的txt文件中的更多相关文章
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- 用Python爬取斗鱼网站的一个小案例
思路解析: 1.我们需要明确爬取数据的目的:为了按热度查看主播的在线观看人数 2.浏览网页源代码,查看我们需要的数据的定位标签 3.在代码中发送一个http请求,获取到网页返回的html(需要注意的是 ...
- Python爬取某网站文档数据完整教程(附源码)
基本开发环境 (https://jq.qq.com/?_wv=1027&k=NofUEYzs) Python 3.6 Pycharm 相关模块的使用 (https://jq.qq.com/?_ ...
- 利用Python爬取电影网站
#!/usr/bin/env python #coding = utf-8 ''' 本爬虫是用来爬取6V电影网站上的电影资源的一个小脚本程序,爬取到的电影链接会通过网页的形式显示出来 ''' impo ...
- python爬取电影网站信息
一.爬取前提1)本地安装了mysql数据库 5.6版本2)安装了Python 2.7 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的html内 ...
- python爬取招聘网站数据
# -*- coding: utf-8 -*- # 爬虫分析 from bs4 import BeautifulSoup from lxml import etree from selenium im ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- Python爬取mn52网站美女图片以及图片防盗链的解决方法
防盗链原理 http标准协议中有专门的字段记录referer 一来可以追溯上一个入站地址是什么 二来对于资源文件,可以跟踪到包含显示他的网页地址是什么 因此所有防盗链方法都是基于这个Referer字段 ...
- python爬取凤凰网站的新闻,及其链接地址,来源,时间和内容,用selenium自动化和requests处理数据
有写规则需要自己定义判断. import requests from selenium import webdriver import time def grasp(urlT): driver = w ...
- python爬取视频网站m3u8视频,下载.ts后缀文件,合并成整视频
最近发现一些网站,可以解析各大视频网站的vip.仔细想了想,这也算是爬虫呀,爬的是视频数据. 首先选取一个视频网站,我选的是 影视大全 ,然后选择上映不久的电影 “一出好戏” . 分析页面 我用的是c ...
随机推荐
- SSL和HTTPS
转载: 链接 随着互联网的发展,给我们的生活带来便利的同时,也伴随着很多网络钓鱼.信息泄露.网络诈骗等事件的频繁发生,企业网站被钓鱼网站仿冒,遭受经济损失,影响品牌形象. 如果网站不使用SSL证书,数 ...
- Linux 服务器防火墙开放端口命令(iptables、firewalld和ufw)
本文主要介绍Linux中,Centos.Ubuntu和Debian开放防火墙端口的命令(iptables.firewalld和ufw)方法. 1.Centos中开放端口 1.systemctl sta ...
- Jenkins插件:Git
Jenkins插件:Git Jenkins,作为一款备受欢迎的持续集成和持续交付工具,在软件开发领域发挥着举足轻重的作用.它不仅能够与Git无缝集成,还能实现代码的自动化拉取.构建与部署,极大地提升了 ...
- mac安装python包
一.常用包安装记录1.分析exl用的pandas pip install xlrd==1.2.0 pip3 install pandas
- 我的世界服务端插件安装 Vault经济前置插件安装(商店,圈地等需要该前置插件)
Minecraft服务端插件安装-Vault用户登录插件安装 需要准备Vault插件 Vault.jar经济前置插件 Minecraft Vault插件是一款用于Minecraft服务器的多功能经济. ...
- 前端视角看 HTTPS
最近用Docusaurus搭了一个个人网站,部署后看到浏览器地址栏上"不安全"三个字感觉特别辣眼,便不由自主的想起了HTTPS.回忆起自己在日常开发中遇到的一些与HTTPS相关的知 ...
- C# OpenMP
在C#中实现代码优化,并行的方式来提升速度. 参考链接:https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/ho ...
- 2024.11.12随笔&联考总结
前言 心情不好,因为考试时 T2T3 全看错题了,导致 T2 没做出来,T3 一份没得.然后下午打球眼镜架子坏了,回机房才发现被高二的盒了. 但还是稍微写一下总结吧. 总结 感觉我今天做题状态还行,思 ...
- CF2029C New Rating
思路(二分 + 数据结构优化DP) 大致题意为:一个值 \(x\) 初始为 \(0\),然后有一个数组 \(a\),遍历一次数组. 如果 \(a_i > x\),则 \(x + 1\). 如果 ...
- 使用cy7c68013调试mt9v011 ov7670 摄像头测试 icamera视频采集调试
使用cy7c68013调试mt9v011 ov7670 摄像头测试 icamera视频采集调试 采集底板选用cp601d,原理图参考icamera设计,使用cy7c68013a芯片设计,固件刷ic ...