大数据计算引擎 EasyMR:拥抱开源,引领技术创新
身处数字经济时代,随着大数据应用越来越广泛,越来越多的企业和组织开始关注大数据基础平台的建设和运营。在认识到其的重要性之后,如何具体着手搭建或采购大数据基础平台成为下一步需要解决的问题。
在大数据基础平台中,大数据组件是非常重要的一部分,包括数据存储、数据处理、数据分析、数据可视化等。在选择大数据组件时,我们常常在闭源组件和开源组件选择中反复纠结。
本文将从优势、劣势两个维度分析开源组件、闭源组件对大数据基础平台建设的影响,并结合袋鼠云自研的大数据计算引擎 EasyMR 的实践经历进行分享。
开源组件
在大数据领域,开源组件已经成为了构建大数据平台的重要基石。例如 Hadoop、Spark、Hive、HBase、Kafka、Storm、Flink 等开源软件已经成为了大数据处理和分析的主要工具。
这些开源组件不仅提供了高效、可扩展、可靠的大数据处理和存储能力,而且还促进了生态系统的发展,形成了庞大的开发社区和丰富的第三方工具及应用程序。
优势
● 免费
开源组件一般都是免费的,其源代码是公开的,任何人都可以下载、使用、修改和分发,这将极大降低企业的开发和建设成本。
● 灵活性
由于源代码是公开的,企业可以对其进行自定义修改,以适应自身业务需求,增强了灵活性。
● 可扩展性
开源组件通常具有良好的扩展性,可以很容易地集成和升级到其他开源组件。
● 社区支持
开源组件一般拥有庞大的社区,社区成员均可以贡献代码,提供解决方案和支持。这意味着在使用过程中遇到问题,可以得到快速的帮助和解决方案。
开源软件的开发和维护通常由广泛的社区贡献提供,从而形成共同的技术标准和最佳实践,这有助于提高软件质量和安全性,并为企业提供更好的互操作性和可移植性。
劣势
● 依赖社区
开源组件的发展取决于社区的贡献,如果社区贡献较少或者停滞不前,开源组件可能会面临更新缓慢或停止维护的问题。
● 安全性
开源组件的源代码是公开的,这使得黑客和恶意用户可以更轻松地发现和利用其中的漏洞,企业在使用开源组件时,需要进行必要的安全检查和漏洞修复。
商业闭源组件
例如 MapR 公司的 MapR-DB、MapR-ES,IBM 公司的 IBM Streams,Cloudera 公司的 Cloudera Manager、Cloudera Navigator、Cloudera Data Science Workbench 等都是比较主流的大数据闭源组件。
优势
● 技术支持
闭源组件通常由厂商提供技术支持,可以为企业提供更为专业、快速的支持,保障企业的业务稳定性。
● 安全性
商业闭源组件的源代码不公开,使得黑客和恶意用户难以发现和利用其中的漏洞,企业在使用闭源组件时,可以减少安全方面的担忧。
● 定制性
商业闭源组件可以提供定制化的服务,以满足企业的个性化需求。
劣势
● 依赖厂商
商业闭源组件的维护和发展需要依赖厂商的支持,其更新迭代速度比较依赖企业的研发投入,如果厂商出现问题或者停止支持,企业可能需要更换整个组件。
● 价格高昂
商业闭源组件通常需要购买许可证或者按使用量收费,这会极大增加企业的成本。
● 数据生产效率低
商业闭源组件通常会对使用者的自由度和可控性产生限制,如禁止对源代码进行修改等要求。
开源 or 闭源?
开源组件 or 闭源组件,企业究竟应该如何选择?
对比来看,对于需要灵活性和可定制性较高的企业来说,开源组件更为适合;而对于更为注重技术支持和安全性的企业来说,商业闭源组件则更具有优势。
开源组件和商业闭源组件各有优缺点,注定了它们拥有各自的市场需求。但基于 DB-Engines 全球数据管理系统排名来看,开源流行度正在逐年上升,2021年1月开源产品首次超过商业数据库。
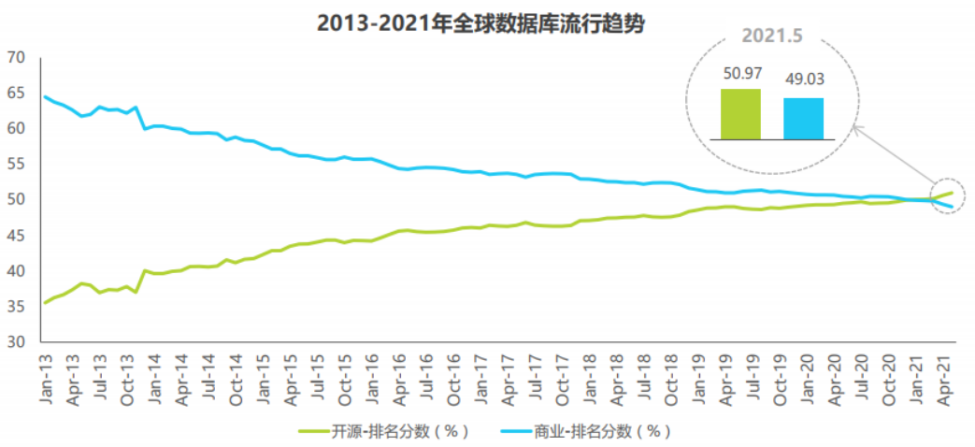
开源软件可以降低企业的成本,提高软件产品的通用性,同时促进技术创新和生态系统的发展。
开源软件相比闭源软件的优势主要有两点,一是众人拾材火焰高,通过开源社区的沟通交流,能够更快提高代码质量;二是开源大大提高了软件的推广效率。
可以说,大数据基础平台组件开源,是当前和未来发展的趋势。
EasyMR 的实践之路
袋鼠云大数据计算引擎 EasyMR,作为袋鼠云自研的大数据基础平台,其大数据组件100%基于开源 Hadoop,完全兼容Apache开源生态,与开源社区同步迭代,时刻保持技术的领先性。
在 CDH、HDP 社区版不再更新,国产化信创政策大背景下,袋鼠云支持 CDH/HDP 平滑迁移 EasyMR,助力企业快速实现国产化大数据基础平台的搭建与迁移,真正实现对业务侧不造成任何影响。
袋鼠云作为国内领先的数字化基础软件与应用服务商,十分重视强化产品的基础能力和技术能力,在开源技术的基础上,EasyMR 对 Spark、Flink、Trino、Iceberg 等多个大数据核心组件进行了功能及性能增强。具体优化见下图:

仅在2022年袋鼠云技术同学就完成了上百次的 commit,为 Hadoop 生态的技术发展贡献了属于袋鼠云的力量。
赠人玫瑰手有余香,回馈社区的同时袋鼠云实现了对整个 Hadoop 体系核心代码的完全自主掌握,对于 EasyMR 大数据平台迁移、大数据组件维保、客户培训做到了100%自主可控。
国际环境严峻复杂,袋鼠云深知只有实现关键技术的自主化、国产化,才能真正实现技术创新,攻克“卡脖子”难题。
拥抱开源不止于此
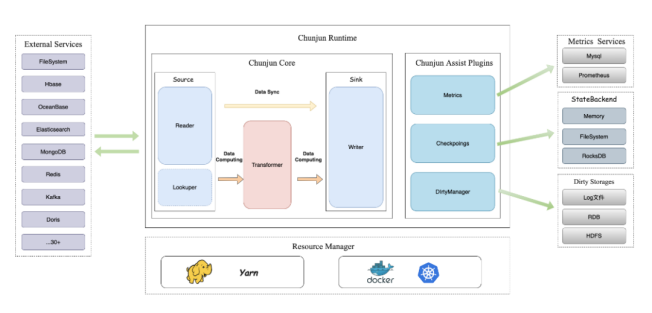
ChunJun 作为袋鼠云重磅打造的批流一体的数据集成大数据开源项目,在袋鼠云及众多开源技术爱好者的协作努力下,目前已进行了5200+commit,拥有3600+star,逐步成为主流的数据集成框架。
今年,EasyMR 将集成 ChunJun 项目,为用户带来更加稳定、高效、易用的批流一体的数据集成解决方案。
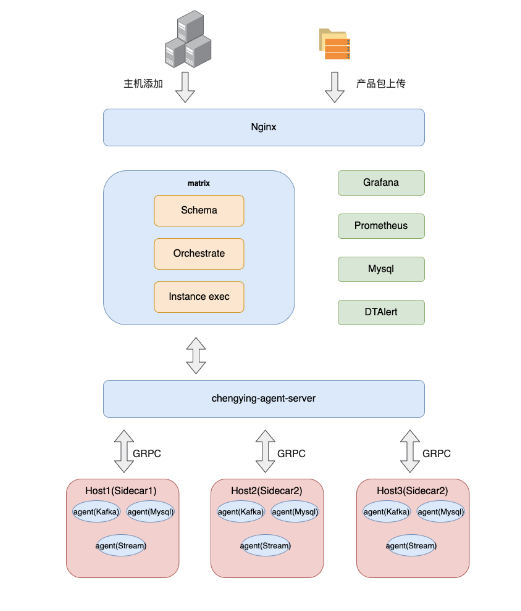
基于 EasyMR 的运维管理平台 EasyManager,袋鼠云成功开源一站式全自动化全生命周期运维管家 ChengYing。从开放式统一监控,到定义标准化部署能力,而后引入 Prometheus/Grafana/ 自研 dt-alert 组件,完成统一监控2.0的功能优化,再到多集群管理,帮助企业快速搭建自己的运维管理平台。
EasyMR 的最新版运维管理平台 EasyManager 中的前端组件及样式是基于袋鼠云开源项目 ant-design 的 React UI 组件库、样式库进行打造。袋鼠云 dt- React 组件为使用者提供更丰富的组件库,可以更好的管理组件,减少代码冗余提高前端开发。具体内容将在之后的文章中进行详解。
袋鼠云秉承着开源共享的理念,受益开源的同时积极拥抱世界、拥抱开源,期待与更多开源爱好者一起共建优秀开源产品。
同时,袋鼠云始终坚持自主研发和国产化路线,在技术创新上不遗余力,为企业IT高效、平稳运行保驾护航。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
大数据计算引擎 EasyMR:拥抱开源,引领技术创新的更多相关文章
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 大数据计算引擎之Flink Flink CEP复杂事件编程
原文地址: 大数据计算引擎之Flink Flink CEP复杂事件编程 复杂事件编程(CEP)是一种基于流处理的技术,将系统数据看作不同类型的事件,通过分析事件之间的关系,建立不同的时事件系序列库,并 ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- Hadoop和大数据:60款顶级开源工具(山东数漫江湖)
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 大数据计算:如何仅用1.5KB内存为十亿对象计数
大数据计算:如何仅用1.5KB内存为十亿对象计数 Big Data Counting: How To Count A Billion Distinct Objects Using Only 1.5K ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
随机推荐
- 【Git】基本操作
一.Git 基础 1.Git 介绍 Git 是目前世界上最先进的分布式版本控制系统. 版本控制系统: 设计师在设计的时候做了很多版本 经过了数天去问设计师每个版本都改了些啥,设计师此时可能就说不上来了 ...
- harmonyOS基础- 快速弄懂HarmonyOS ArkTs基础组件、布局容器(前端视角篇)
大家好!我是黑臂麒麟,一位6年的前端: if you're change the world, you're workingon important things. you're excited to ...
- AbstractAutoProxyCreator#postProcessBeforeInstantiation
一.定义 postProcessBeforeInstantiation 是 Spring AOP 动态代理的核心扩展点,通过提前创建代理对象优化性能,并支持丰富的自定义逻辑(如事务.安全) 二.代码分 ...
- Eclipse 中 JAVA AWT相关包不提示问题(解决)
原因: 由于在2021年7月15日 OpenJDK管理委员会全票通过批准成立由Phil Race担任初始负责人的 Client Libraries Group(客户端类库工作组). 新的工作组将继续赞 ...
- Linux四剑客grep、find、sed、awk使用
介绍 Linux四剑客是指在Linux系统中非常常用的四个命令工具,它们分别是grep.find.sed和awk.这四个工具在Linux系统中具有非常强大的功能,可以方便快捷地对文本进行搜索.处理 ...
- GitLab——重置(reset)和还原(revert)
Git 命令 reset 和 revert 的区别 - 知乎 (zhihu.com) 总结: git reset --hard 9201d9b19dbf5b4ceaf90f92fd4e4019b685 ...
- [护网必备]2018年-2024年HVV 6000+个漏洞 POC 合集分享
此份poc 集成了Zabbix.用友.通达.Wordpress.Thinkcmf.Weblogic.Tomcat等 下载链接: 链接: 6000+Poc下载
- 【HUST】网安|操作系统实验|实验二 进程管理与死锁
目的 1)理解进程/线程的概念和应用编程过程: 2)理解进程/线程的同步机制和应用编程: 任务 1)在Linux下创建一对父子进程. 2)在Linux下创建2个线程A和B,循环输出数据或字符串. 3) ...
- Windows-exporter(node-exporter)+ Prometheus + Grafana资源监控搭建
在性能测试过程中,资源监控可以时刻掌握被测软件运行环境的各类数据,从而更加直观地反馈测试过程中潜在的问题,下面是基于Windows-exporter(node-exporter)+ Prometheu ...
- 操作系统 -- SLAB如何分配内存
在Linux系统中比页更小的内存对象要怎么分配呢? -- SLAB,学习下SLAB分配器的原理和实现 SLAB 与Cosmos物理页面管理器一样,Linux中的伙伴系统是以页面为最小单位分配到,现实更 ...