微信团队分享:微信后端海量数据查询从1000ms降到100ms的技术实践
本文由微信技术团队仇弈彬分享,原题“微信海量数据查询如何从1000ms降到100ms?”,本文进行了内容修订和排版优化。
1、引言
微信的多维指标监控平台,具备自定义维度、指标的监控能力,主要服务于用户自定义监控。作为框架级监控的补充,它承载着聚合前 45亿/min、4万亿/天的数据量。
当前,针对数据层的查询请求也达到了峰值 40万/min,3亿/天。较大的查询请求使得数据查询遇到了性能瓶颈:查询平均耗时 > 1000ms,失败率居高不下。
针对大数据量带来的查询性能问题,微信团队对数据层查询接口进行了针对性的优化,将平均查询速度从1000ms+优化到了100ms级别。本文为各位分享优化过程,希望对你有用!

技术交流:
- 移动端IM开发入门文章:《新手入门一篇就够:从零开发移动端IM》
- 开源IM框架源码:https://github.com/JackJiang2011/MobileIMSDK(备用地址点此)
(本文已同步发布于:http://www.52im.net/thread-4629-1-1.html)
2、技术背景
微信多维指标监控平台(以下简称多维监控),是具备灵活的数据上报方式、提供维度交叉分析的实时监控平台。
在这里,最核心的概念是“协议”、“维度”与“指标”。
例如:如果想要对某个【省份】、【城市】、【运营商】的接口【错误码】进行监控,监控目标是统计接口的【平均耗时】和【上报量】。在这里,省份、城市、运营商、错误码,这些描述监控目标属性的可枚举字段称之为“维度”,而【上报量】、【平均耗时】等依赖“聚合计算”结果的数据值,称之为“指标”。而承载这些指标和维度的数据表,叫做“协议”。
多维监控对外提供 2 种 API:
1)维度枚举查询:用于查询某一段时间内,一个或多个维度的排列组合以及其对应的指标值。它反映的是各维度分布“总量”的概念,可以“聚合”,也可以“展开”,或者固定维度对其它维度进行“下钻”。数据可以直接生成柱状图、饼图等。
2)时间序列查询:用于查询某些维度条件在某个时间范围的指标值序列。可以展示为一个时序曲线图,横坐标为时间,纵坐标为指标值。
然而,不管是用户还是团队自己使用多维监控平台的时候,都能感受到明显的卡顿。主要表现在看监控图像或者是查看监控曲线,都会经过长时间的数据加载。
团队意识到:这是数据量上升必然带来的瓶颈。
目前:多维监控平台已经接入了数千张协议表,每张表的特点都不同。维度组合、指标量、上报量也不同。针对大量数据的实时聚合以及 OLAP 分析,数据层的性能瓶颈越发明显,严重影响了用户体验。
于是这让团队人员不由得开始思考:难道要一直放任它慢下去吗?答案当然是否定的。因此,微信团队针对数据层的查询进行了优化。
3、优化分析1:用户查询行为分析
要优化,首先需要了解用户的查询习惯,这里的用户包含了页面用户和异常检测服务。
于是微信团队尽可能多地上报用户使用多维监控平台的习惯,包括但不限于:常用的查询类型、每个协议表的查询维度和查询指标、查询量、失败量、耗时数据等。
在分析了用户的查询习惯后,有了以下发现:
1)时间序列查询占比 99% 以上:
出现如此悬殊的比例可能是因为:调用一次维度枚举,即可获取所关心的各个维度。
但是针对每个维度组合值,无论是页面还是异常检测都会在查询维度对应的多条时间序列曲线中,从而出现「时间序列查询」比例远远高于「维度枚举查询」。
2)针对1天前的查询占比约 90%:
出现这个现象可能是因为每个页面数据都会带上几天前的数据对比来展示。异常检测模块每次会对比大约 7 天数据的曲线,造成了对大量的非实时数据进行查询。
4、优化分析2:数据层架构
分析完用户习惯,再看下目前的数据层架构。
多维监控底层的数据存储/查询引擎选择了 Apache-Druid 作为数据聚合、存储的引擎,Druid 是一个非常优秀的分布式 OLAP 数据存储引擎,它的特点主要在于出色的预聚合能力和高效的并发查询能力。
它的大致架构如图:

具体解释就是:

5、优化分析3:为什么查询会慢
查询慢的核心原因,经微信团队分析如下:
1)协议数据分片存储的数据片段为 2-4h 的数据,每个 Peon 节点消费回来的数据会存储在一个独立分片。
2)假设异常检测获取 7 * 24h 的数据,协议一共有 3 个 Peon 节点负责消费,数据分片量级为 12*3*7 = 252,意味着将会产生 252次 数据分片 I/O。
3)在时间跨度较大时、MiddleManager、Historical 处理查询容易超时,Broker 内存消耗较高。
4)部分协议维度字段非常复杂,维度排列组合极大(>100w),在处理此类协议的查询时,性能就会很差。
6、优化实践1:拆分子查询请求
根据上面的分析,团队确定了初步的优化方向:
- 1)减少单 Broker 的大跨度时间查询;
- 2)减少 Druid 的 Segments I/O 次数;
- 3)减少 Segments 的大小。
在这个方案中,每个查询都会被拆解为更细粒度的“子查询”请求。例如连续查询 7 天的时间序列,会被自动拆解为 7 个 1天的时间序列查询,分发到多个 Broker,此时可以利用多个 Broker 来进行并发查询,减少单个 Broker 的查询负载,提升整体性能。
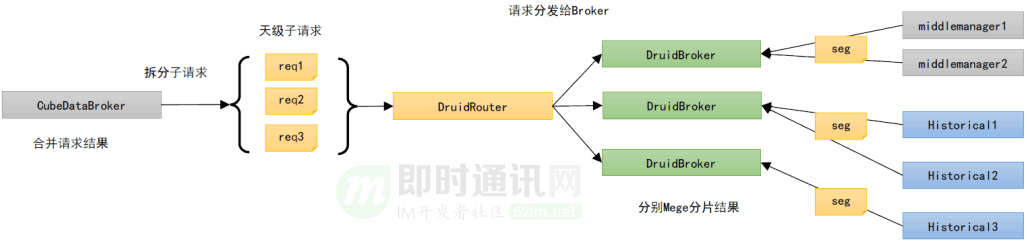
但是这个方案并没有解决 Segments I/O 过多的问题,所以需要在这里引入一层缓存。
7、优化实践2:拆分子查询请求+Redis Cache
7.1概述
这个方案相较于 v1,增加了为每个子查询请求维护了一个结果缓存,存储在 Redis 中(如下图所示)。
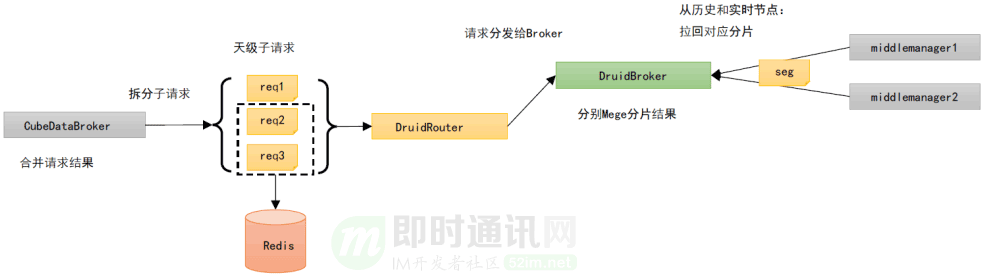
假设获取 7*24h 的数据,Peon 节点个数为 3,如果命中缓存,只会产生 3 次 Druid 的 Segments I/O (最近的 30min)数据,相较几百次 Segments I/O 会大幅减少。
接下来看下具体方法。
7.2时间序列子查询设计
针对时间序列的子查询,子查询按照「天」来分解,整个子查询的缓存也是按照天来聚合的。
以一个查询为例:
{
"biz_id": 1, // 查询协议表ID:1
"formula": "avg_cost_time", // 查询公式:求平均
"keys": [
// 查询条件:维度xxx_id=3
{"field": "xxx_id", "relation": "eq", "value": "3"}
],
"start_time": "2020-04-15 13:23", // 查询起始时间
"end_time": "2020-04-17 12:00"// 查询结束时间
}
其中 biz_id、 formula,、keys 了每个查询的基本条件。但每个查询各不相同,不是这次讨论的重点。
本次优化的重点是基于查询时间范围的子查询分解,而对于时间序列子查询分解的方案则是按照「天」来分解,每个查询都会得到当天的全部数据,由业务逻辑层来进行合并。
举个例子:04-15 13:23 ~ 04-17 08:20 的查询,会被分解为 04-15、04-16、04-17 三个子查询,每个查询都会得到当天的全部数据,在业务逻辑层找到基于用户查询时间的偏移量,处理结果并返回给用户。
每个子查询都会先尝试获取缓存中的数据,此时有两种结果:

经过上述分析不难看出:对于距离现在超过一天的查询,只需要查询一次,之后就无需访问 DruidBroker 了,可以直接从缓存中获取。
而对于一些实时热数据,其实只是查询了cache_update_time-threshold_time 到 end_time 这一小段的时间。在实际应用里,这段查询时间的跨度基本上在 20min 内,而 15min 内的数据由 Druid 实时节点提供。
7.3维度组合子查询设计
维度枚举查询和时间序列查询不一样的是:每一分钟,每个维度的量都不一样。
而维度枚举拿到的是各个维度组合在任意时间的总量,因此基于上述时间序列的缓存方法无法使用。在这里,核心思路依然是打散查询和缓存。
对此,微信团队使用了如下方案。
缓存的设计采用了多级冗余模式,即每天的数据会根据不同时间粒度:天级、4小时级、1 小时级存多份,从而适应各种粒度的查询,也同时尽量减少和 Redis 的 IO 次数。
每个查询都会被分解为 N 个子查询,跨度不同时间,这个过程的粗略示意图如下:
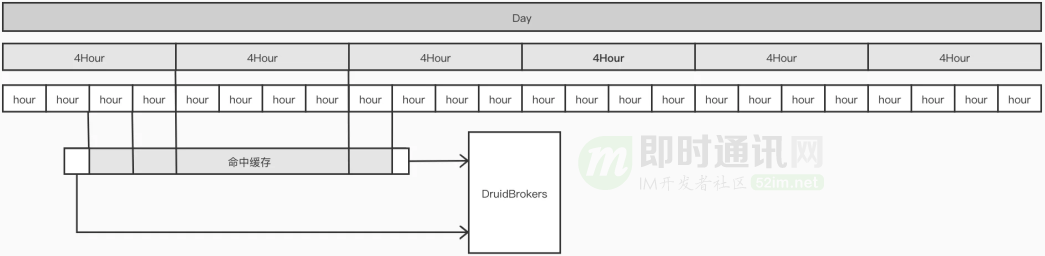
举个例子:例如 04-15 13:23 ~ 04-17 08:20 的查询,会被分解为以下 10 个子查询:
04-15 13:23 ~ 04-15 14:00
04-15 14:00 ~ 04-15 15:00
04-15 15:00 ~ 04-15 16:00
04-15 16:00 ~ 04-15 20:00
04-15 20:00 ~ 04-16 00:00
04-16 00:00 ~ 04-17 00:00
04-17 00:00 ~ 04-17 04:00
04-17 00:00 ~ 04-17 04:00
04-17 04:00 ~ 04-17 08:00
04-17 08:00 ~ 04-17 08:20
这里可以发现:查询 1 和查询 10,绝对不可能出现在缓存中。因此这两个查询一定会被转发到 Druid 去进行。2~9 查询,则是先尝试访问缓存。如果缓存中不存在,才会访问 DruidBroker,在完成一次访问后将数据异步回写到 Redis 中。
维度枚举查询和时间序列一样,同时也用了 update_time 作为数据可信度的保障。因为最细粒度为小时,在理想状况下一个时间跨越很长的请求,实际上访问 Druid 的最多只有跨越 2h 内的两个首尾部查询而已。
8、优化实践3:更进一步(子维度表)
通过子查询缓存方案,我们已经限制了 I/O 次数,并且保障 90% 的请求都来自于缓存。但是维度组合复杂的协议,即 Segments 过大的协议,仍然会消耗大量时间用于检索数据。
所以核心问题在于:能否进一步降低 Segments 大小?
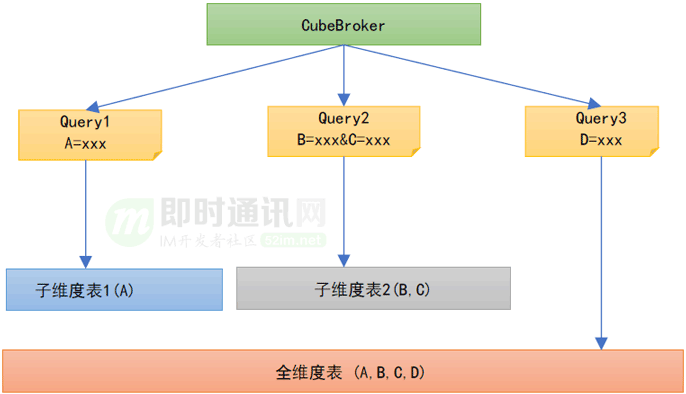
维度爆炸问题在业界都没有很好的解决方案,大家要做的也只能是尽可能规避它,因此这里,团队在查询层实现了子维度表的拆分以尽可能解决这个问题,用空间换时间。
具体做法为:
- 1) 对于维度复杂的协议,抽离命中率高的低基数维度,建立子维度表,实时消费并入库数据;
- 2) 查询层支持按照用户请求中的查询维度,匹配最小的子维度表。
9、优化成果
9.1缓存命中率>85%
在做完所有改造后,最重要的一点便是缓存命中率。因为大部分的请求来自于1天前的历史数据,这为缓存命中率提供了保障。
具体是:
- 1)子查询缓存完全命中率(无需查询Druid):86%;
- 2)子查询缓存部分命中率(秩序查询增量数据):98.8%。
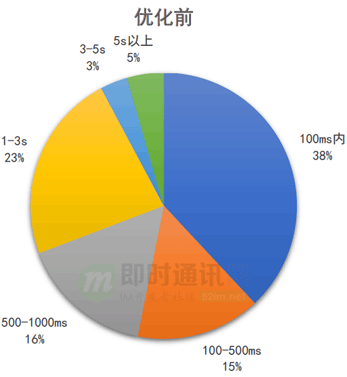
9.2查询耗时优化至 100ms
在整体优化过后,查询性能指标有了很大的提升:
平均耗时 1000+ms -> 140ms;P95:5000+ms -> 220ms。

10、相关文章
[2] IM开发基础知识补课(三):快速理解服务端数据库读写分离原理及实践建议
[3] 社交软件红包技术解密(六):微信红包系统的存储层架构演进实践
[4] 微信后台基于时间序的新一代海量数据存储架构的设计实践
[5] 陌陌技术分享:陌陌IM在后端KV缓存架构上的技术实践
[7] 微信海量用户背后的后台系统存储架构(视频+PPT) [附件下载]
[8] 腾讯TEG团队原创:基于MySQL的分布式数据库TDSQL十年锻造经验分享
[9] IM全文检索技术专题(四):微信iOS端的最新全文检索技术优化实践
[10] 微信Windows端IM消息数据库的优化实践:查询慢、体积大、文件损坏等
[11] 微信技术分享:揭秘微信后台安全特征数据仓库的架构设计
11、微信团队的其它文章
《微信技术分享:微信的海量IM聊天消息序列号生成实践(算法原理篇)》
《微信团队分享:Kotlin渐被认可,Android版微信的技术尝鲜之旅》
《社交软件红包技术解密(二):解密微信摇一摇红包从0到1的技术演进》
《社交软件红包技术解密(十一):解密微信红包随机算法(含代码实现)》
《QQ设计团队分享:新版 QQ 8.0 语音消息改版背后的功能设计思路》
《微信团队分享:极致优化,iOS版微信编译速度3倍提升的实践总结》
《IM“扫一扫”功能很好做?看看微信“扫一扫识物”的完整技术实现》
《微信团队分享:微信支付代码重构带来的移动端软件架构上的思考》
《IM开发宝典:史上最全,微信各种功能参数和逻辑规则资料汇总》
《微信团队分享:微信直播聊天室单房间1500万在线的消息架构演进之路》
《企业微信的IM架构设计揭秘:消息模型、万人群、已读回执、消息撤回等》
《微信团队分享:微信后台在海量并发请求下是如何做到不崩溃的》
《IM跨平台技术学习(九):全面解密新QQ桌面版的Electron内存优化实践》
《揭秘企业微信是如何支持超大规模IM组织架构的——技术解读四维关系链》
《微信团队分享:详解iOS版微信视频号直播中因帧率异常导致的功耗问题》
(本文已同步发布于:http://www.52im.net/thread-4629-1-1.html)
微信团队分享:微信后端海量数据查询从1000ms降到100ms的技术实践的更多相关文章
- 微信团队分享:Kotlin渐被认可,Android版微信的技术尝鲜之旅
本文由微信开发团队工程是由“oneliang”原创发表于WeMobileDev公众号,内容稍有改动. 1.引言 Kotlin 是一个用于现代多平台应用的静态编程语言,由 JetBrains 开发( ...
- 微信团队分享:iOS版微信的高性能通用key-value组件技术实践
本文来自微信开发团队guoling的技术分享. 1.前言 本文要分享的是iOS版微信内部正在推广和使用的一个高性能通用key-value 组件的技术实践过程,该组件在微信内部被命名为MMKV(以下简称 ...
- 微信团队分享:iOS版微信是如何防止特殊字符导致的炸群、APP崩溃的?
本文来自微信开发团队yanyang的技术分享. 1.引言 相信大家都遇到过一段特殊文本可以让iOS设备所有app闪退的经历.前段时间大年初一,又出现某个印度语字符引起iOS11系统奔溃,所幸iOS版微 ...
- JSSDK实现微信自定义分享---java 后端获取签名信息
一.首先说下关于微信Access_token的问题,微信Access_token分为2中: 1.授权token获取方式: 这种token需要code值(如何获取code值查看官方文档) "h ...
- 微信团队分享:极致优化,iOS版微信编译速度3倍提升的实践总结
1.引言 岁月真是个养猪场,这几年,人胖了,微信代码也翻了. 记得 14 年转岗来微信时,用自己笔记本编译微信工程才十来分钟.如今用公司配的 17 年款 27-inch iMac 编译要接近半小时:偶 ...
- 微信团队原创分享:iOS版微信的内存监控系统技术实践
本文来自微信开发团队yangyang的技术分享. 一.前言 FOOM(Foreground Out Of Memory),是指App在前台因消耗内存过多引起系统强杀.对用户而言,表现跟crash一样. ...
- 腾讯技术分享:GIF动图技术详解及手机QQ动态表情压缩技术实践
本文来自腾讯前端开发工程师“ wendygogogo”的技术分享,作者自评:“在Web前端摸爬滚打的码农一枚,对技术充满热情的菜鸟,致力为手Q的建设添砖加瓦.” 1.GIF格式的历史 GIF ( Gr ...
- 让互联网更快:新一代QUIC协议在腾讯的技术实践分享
本文来自腾讯资深研发工程师罗成在InfoQ的技术分享. 1.前言 如果:你的 App,在不需要任何修改的情况下就能提升 15% 以上的访问速度,特别是弱网络的时候能够提升 20% 以上的访问速度. 如 ...
- 如何开发一款堪比APP的微信小程序(腾讯内部团队分享)
一夜之间,微信小程序刷爆了行业网站和朋友圈,小程序真的能如张小龙所说让用户"即用即走"吗? 其功能能和动辄几十兆安装文件的APP相比吗? 开发小程序,是不是意味着移动应用开发的一次 ...
- 【原创分享·微信支付】 C# MVC 微信支付教程系列之公众号支付
微信支付教程系列之公众号支付 今天,我们接着讲微信支付的系列教程,前面,我们讲了这个微信红包和扫码支付.现在,我们讲讲这个公众号支付.公众号支付的应用环境常见的用户通过公众号,然后再通 ...
随机推荐
- 7 个非常实用的 Shell 拿来就用脚本实例!
前天,在群里看到有一位读者分享了几道 Shell 脚本实例题目,索性看到了,不如来写写巩固下基础知识,如下: 1. 并发从数台机器中获取 hostname,并记录返回信息花费的时长,重定向到一个文件 ...
- 做PPT知识积累
很多技术人员鄙视PPT,他们觉得做PPT的人不干具体工作,只会把别人的劳动成果用PPT的形式变成自己的成果.这种想法有些酸,根源在于没有真正理解PPT的价值.工作中PPT的作用及其重要,也可以理解为梳 ...
- 使用switch语句的注意事项
目录 case后需要手动break switch内的变量定义 变量没有定义在语句块内 变量定义在语句块内 表述多情况时不能用逗号 case后需要手动break switch(i){ case 1: 语 ...
- Python安装技术类库模块
方法1: 方法2: 用如下命令安装即可(注意都得是英文字符): # 简单粗暴,但是可能安装到了不同的环境 pip install some-package # 复杂但是精准还快速 C:\Python3 ...
- You Shi Zai Wo
Xuzhou is a place where there have been more than 50 large-scale battles from ancient times to the p ...
- SpringBoot进阶教程(八十三)Kaptcha
Kaptcha是谷歌开源的一个可高度配置的比较老旧的实用验证码生成工具.它可以实现:(1)验证码的字体/大小颜色:(2)验证码内容的范围(数字,字母,中文汉字):(3)验证码图片的大小,边框,边框粗细 ...
- 做AI运动小程序有哪些解决方案,如何进行选型?
引言:随着深度学习技术的发展进步,已经不再依赖强大的GPU算力,便可实现AI推理了,让AI技术渗透到了电脑.手机.智能设备等各类设备.体育.健身行业也不例外,阿里体育等IT大厂,推出的乐动力.天天跳绳 ...
- 深入JVM的Class文件结构
Class文件由顺序的8位字节为基础单位构成的二进制流.各个项目严格按照顺序紧凑排列,无分隔符. 需要用8位字节以上空间数据项时按照高位在前分割成若干个8位字节存储. 只包含2种数据类型: 无符号数 ...
- golang之常用开发工具
汇总平常开发中较为常用的工具 [sql2struct] 将MySQL快速生成struct github: https://github.com/idoubi/sql2struct
- gitlab之配置文件.gitlab-ci.yml
自动化部署給我们带来的好处 自动化部署的好处体现在几个方面 1.提高前端的开发效率和开发测试之间的协调效率 Before 如果按照传统的流程,在项目上线前的测试阶段,前端同学修复bug之后,要手动把代 ...