当 CloudQuery 遇到大数据
「世界上有着无法想象的巨量数字信息,并以极快的速度增长。从经济界到科学界,从政府部门到艺术领域,很多方面都 已经感受到了这种巨量信息的影响。科学家和计算机工程师已经为这个现象创造了一个新词汇:‘大数据’。」
——肯尼斯·库克尔《数据,无所不在的数据》
「人类正在从 IT 时代走向 DT 时代」。在 DT 时代,人们比以往时候更能收集到更丰富的数据。数据正在变革我们的生活,催生大数据行业的发展,而迅猛增长的数据也带来了严峻的数据处理问题。
在大数据时代,传统的软件已经无法处理和挖掘大量数据中的信息。最重要的变革就是谷歌的“三架马车”。谷歌在 2004 年左右相继发布谷歌分布式文件系统 GFS、大数据分布式计算框架 Mapreduce、大数据 Nosql 数据库 BigTable ,这三篇论文奠定了大数据技术的基石。
接下来,大数据相关技术不断发展,开源的做法让大数据生态逐渐形成。由于MapReduce 编程繁琐,Facebook 贡献 HiveQL 语法为数据分析、数据挖掘提供巨大帮助。Elasticsearch、Splunk等面向搜索数据内容的搜索引擎也登上舞台,主要用于对海量数据进行实时处理和分析。
CloudQuery 作为数据管控平台,在其成长规划中计划支持全类型数据源。在1.4 迭代过程中,将加入用户呼声最高的 Hive 和 Elasticsearch。
Hive
说到 Hive,我们不得不提 Hadoop。Hadoop 几乎是现有数据库系统的一种补充,它给用户提供了数据存储的无限空间,擅长存储任意的、半结构化的数据,甚至是非结构化的数据,支持用户在恰当的时候存储和获取数据,并且针对大文件的存储、批量访问和流式访问做了分类优化。
这使得用户对数据分析变得简单快捷,但是用户同样需要访问分析后的最终数据,这种需求需要的不是批量模式而是随机访问模式,这种模式对于数据库系统来说,相当于一种全表扫描和使用索引。
而 Hive 是一个构建在 Hadoop 上的数据仓库框架,是应 Facebook 每天生产的海量新兴社会网络数据进行管理和(机器)学习的需求而产生和发展的。Hive 的设计目的是让精通 SQL 技能但 Java 编程技能相对较弱的分析师能够对 Facebook 存放在 HDFS 中的大规模数据集执行查询。今天,Hive 已经是一个成功的 Apache 项目,很多组织把它用作一个通用的、可伸缩的数据处理平台。
作为 Hadoop 的主流搜索引擎之一,Hive 支持使用SQL来读、写和管理大规模数据集合。CloudQuery 在进行 Hive 数据源对接时首先考虑在大数据量情况下的查询性能问题,控制每次返回的数据为当前 viewpoint 展示用量。其次在大数据或数仓中为了便于数据分析通常为宽表存储,所以在渲染时也会增加多种展现方式切换,包含列表格式和单条格式,列表格式可以提供批量数据预览,单条格式则以列的形式进行宽表详情展示。
Hive 旧版本只支持数据查询和加载,但后续版本增加支持了插入,更新和删除以及流式 api。所以 CloudQuery 在进行数据操作与权限管控覆盖的同时兼顾数据库原生操作特性,增加多种 api 支持。同步支持分区以及分桶特性,分区表针对数据存储路径,设置不同存储路径产生多个数据文件。分桶表针对数据文件,对一个数据文件分为更容易管理的若干部分。
Elasticsearch
与 Hive 不同,Elasticsearch 是面向数据内容搜索的搜索引擎。Elasticsearch 作为一个独立的搜索服务器,提供了非常方便的搜索功能。用户完全不用关心底层 Lucene 的细节,只需要通过标准的 Http + RESTful 风格的 API,就可以进行索引数据的增删改查。数据的输入输出采用 JSON 格式,以文档和面向对象的方式,非常方便理解和表达领域数据。
同时,Elasticsearch 基于分片和副本的方式实现了一个分布式的 Lucene Directory,再结合Map-reduce 的理念,实现了一个简单的搜索请求分发合并的策略,能轻松化解海量索引和分布式高可用的问题。
如今,Elasticsearch 基本上已经是搜索引擎市场排名第一的产品,从 DB-Engines 网站的排名可以看到,Elasitcsearch 基本上是一骑绝尘,拉开第二名远远一大截。
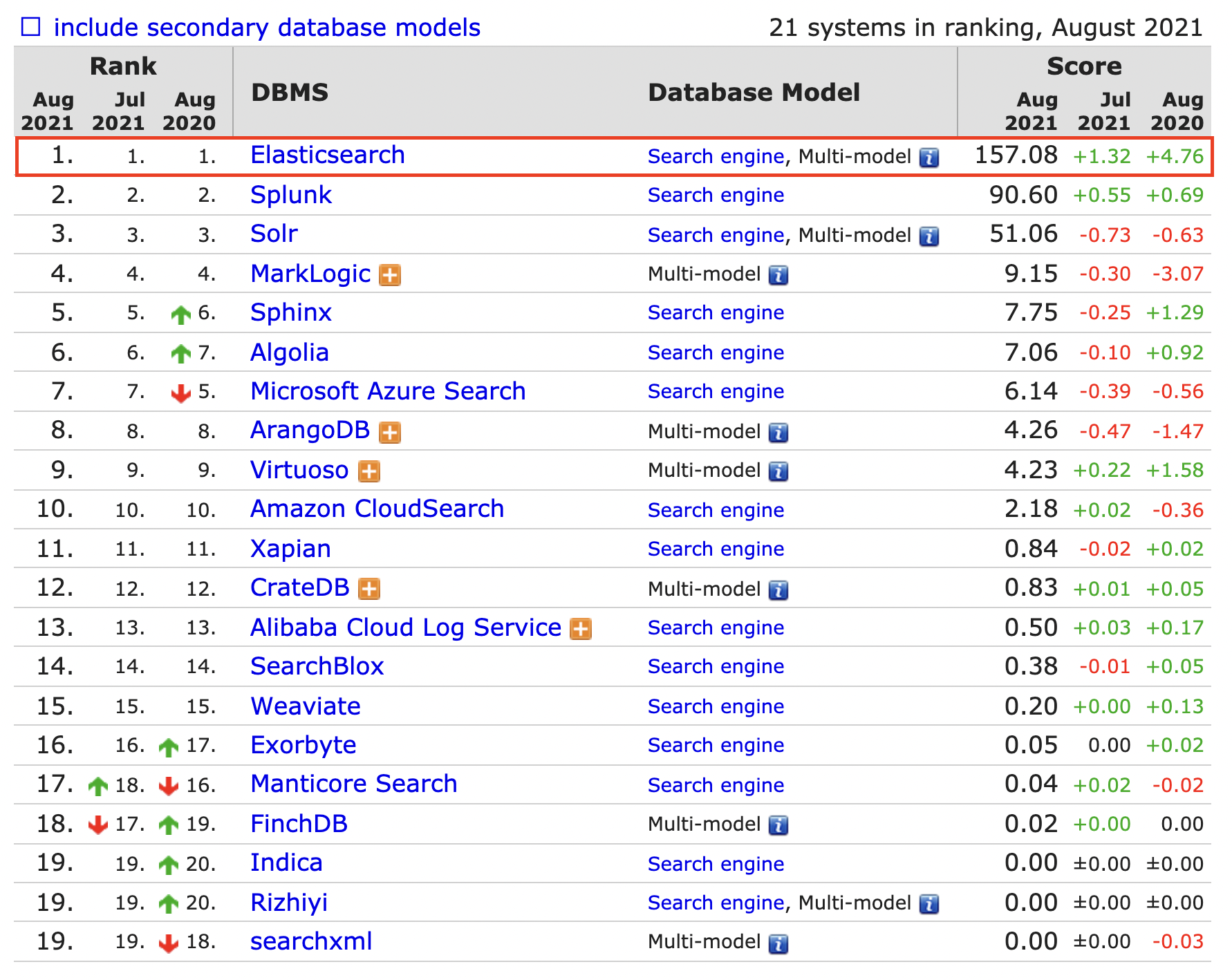
上文中也提到了,ES 与目前市面上主流的数据库之前的区别主要在于最开始它甚至并不算是数据库而是作为搜索引擎出现在大众视野中,后续随着各种技术的成熟以及广度覆盖将全文检索、数据分析以及分布式技术,合并在了一起,才形成了现在我们视野中的 ES。所以它可以同时拥有分布式、查询快速等优点。
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。CloudQuery 在进行对接支持时考虑到 ES 中存储数据类型的特殊性,将其分为文档和索引,可以对文档进行索引、搜索、排序、过滤。这种理解数据的方式与传统的二维表形式完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
在展现形式上我们选择了最通用化的「JSON」格式,因为数据间的差异性导致应用中的对象很少只是简单的键值列表,更多时候它拥有复杂的数据结构,比如包含日期、地理位置、子对象甚至数组。尽管几乎所有的语言都有相应的模块用于将任意数据结构转换为 JSON 格式,但每种语言处理细节不同,所以 CloudQuery 在处理语言和对象兼容性上也进行了水平覆盖,优先保证主流语言以及对象的序列化以及反序列化。
“新基建”的加速为数字经济创造了有利的条件和巨大的发展契机,市场将进一步拥抱云、大数据和商业智能,通过云数智的加速融合,必将加速实现企业数据价值最大化,并高效完成产业智能化的转型和落地。

当 CloudQuery 遇到大数据的更多相关文章
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- CRL快速开发框架系列教程十一(大数据分库分表解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- PayPal高级工程总监:读完这100篇论文 就能成大数据高手(附论文下载)
100 open source Big Data architecture papers for data professionals. 读完这100篇论文 就能成大数据高手 作者 白宁超 2016年 ...
- 分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节
1:MSSQL SQL语法篇: BULK INSERT [ database_name . [ schema_name ] . | schema_name . ] [ table_name | vie ...
- 【NLP】大数据之行,始于足下:谈谈语料库知多少
大数据之行,始于足下:谈谈语料库知多少 作者:白宁超 2016年7月20日13:47:51 摘要:大数据发展的基石就是数据量的指数增加,无论是数据挖掘.文本处理.自然语言处理还是机器模型的构建,大多都 ...
- JAVA大数据数组排序
对于数据排序大家肯定见过不少,选择排序或者冒泡排序等等,今天我们要做的是快速排序 + 直接插入排序来对大数据(1000万以上)进行排序,下面我们分别来看看这两种排序规则 1, 直接插入排序 (1)基本 ...
- 深度剖析 | 基于大数据架构的BI应用
说起互联网.电商的数据分析,更多的是谈应用案例,如何去实践数据化管理运营.而这里,我们要从技术角度分享关于数据的技术架构干货,如何应用BI. 原文是云猴网BI总经理王卫东在帆软大数据上的演讲,以下是整 ...
- 大数据下BI产品如何发挥最大价值
看到这个题目,你是否总感觉云里雾里?你是否真正懂什么叫“大数据”?商业智能BI和大数据又有着什么千丝万缕的联系?为什么说商业智能BI能在大数据中发挥价值? 大数据,指的是所涉及的数据资料量规模巨大到无 ...
- 大数据慎行,数据管理要落实到KPI
近年来,"大数据"一词被IT和互联网行业广泛提及,但真正落到实处的案例没有多少,大数据量支撑.数据挖掘技术.非结构化数据是阻碍的主要原因.大多数企业的信息化并没有达到到成熟水平,关 ...
- mysq大数据分页
mysql limit大数据量分页优化方法 Mysql的优化是非常重要的.其他最常用也最需要优化的就是limit.Mysql的limit给分页带来了极大的方便,但数据量一大的时候,limit的性能就急 ...
随机推荐
- vue3 基础-CompositionAPI - setup
之前介绍的是一些关于代码复用的问题, 如 mixin, plugin 等. 从本篇开始呢, 就将来学习一波 vue3 的新特性, 即 Composition API 咱之前的写法, 即把各种逻辑, 方 ...
- pyqt点击右上角关闭界面但子线程仍在运行
现象: 通过右上角的叉关闭图形界面后,程序运行的子线程却不会被自动关闭,依然留存在系统中 原因: 子线程没有正确关闭 解决方法: 1.将子线程设置成守护线程 self.your_thread = th ...
- 第2讲、Tensor高级操作与自动求导详解
1. 前言 在深度学习模型中,Tensor是最基本的运算单元.本文将深入探讨PyTorch中两个核心概念: Tensor的广播机制(Broadcasting) 自动求导(Autograd)机制 这些知 ...
- 企业级MediaWiki知识库系统搭建部署指南(CentOS 8)
## 一.高级环境准备 ### 1. 系统优化与安全加固 ```bash # 系统更新与内核优化 sudo dnf update -y --security sudo dnf install kern ...
- 邮件收件、读取邮件API-批量导入-支持代理-开放HTTP接口
简介 大恩邮箱收件平台,支持读取收件箱.垃圾箱的邮件.支持批量导入各大邮箱平台的账号(例如微软.谷歌.网易.QQ等),采用pop3.imap协议收件,支持配置代理IP.验证码截取规则等,同时提供了HT ...
- C# Task 取消执行的简单封装
我让DeepSeek帮我写了一段使用 CancellationTokenSource 取消任务的简单示例如下: 取消任务的简单示例 using System.Threading.Tasks; usin ...
- 编程记录:TypeScript中never类型的技巧
技巧1 当我们在一个项目中,可能会去改动一个在整个项目中应用很广泛的函数的参数类型,但是可能由于代码量比较庞大,我们不好排查改了之后哪些地方会出现问题,此时我们可以使用never类型来辅助我们的函数, ...
- Free Mybatis Tool插件
Free Mybatis plugin Free Mybatis Tool 老规矩先吹一波......这个idea里面的插件真的十分nice,上个图让你们知道他的优秀.直接在idea插件搜索就可以安装 ...
- DBA 必知必会 —— OB 4.x 版本如何查询磁盘空间占用情况?
首先为大家推荐这个 OceanBase 开源负责人老纪的公众号 "老纪的技术唠嗑局",会持续更新和 #数据库.#AI.#技术架构 相关的各种技术内容.欢迎感兴趣的朋友们关注! 这是 ...
- Elastic学习之旅 (5) 倒排索引和Analyzer分词
大家好,我是Edison. 上一篇:ES文档的CRUD操作 重要概念1:倒排索引 在学习ES时,倒排索引是一个非常重要的概念.要了解倒排索引,就得先知道什么是正排索引.举个简单的例子,书籍的目录页(从 ...