kettle学习笔记(九)——子转换、集群与变量
一、概述
kettle中3个重要的步骤:
子转换/映射
在转换里调用一个子转换,便于封装和重用。
集群
集群模式
变量和参数
变量和参数的用法
二、子转换
1.定义子转换
主要由映射输入与映射输出定义:

这里给出一个从kettle自带的samples中拿出来的示例,详情配置,参考kettle示例
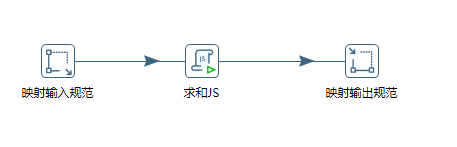
保存这个转换(可以是文件,也可以在资源库),这就是子转换了!
2.调用子转换

子转换的配置:

整个调用的示例如下:

// 详细,查看kettle示例
三、集群
Kettle 集群是一个分布式的运行环境,由一个主节点和多个子节点构成。
主节点调度在子节点上处理不同的数据行,子节点把处理后的结果再提交到主节点。
(本机模拟可以通过carte不同端口来模拟启动,然后在kettle的子服务器中配置,默认集群用户名cluster/cluster,然后在kettle集群中添加集群)
使用的方式在步骤右击,选择集群进行配置
四、参数和变量
1.参数
参数分为位置参数(arg)和命名参数(param),变量则和之前介绍的一样。
一个使用参数的示例如下:
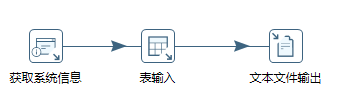
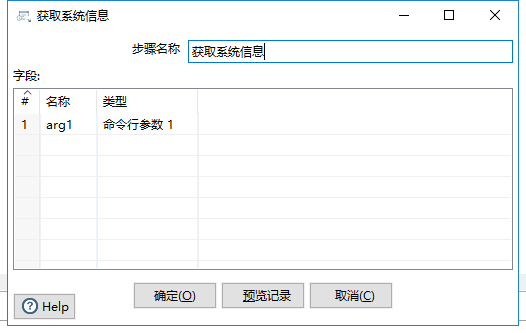
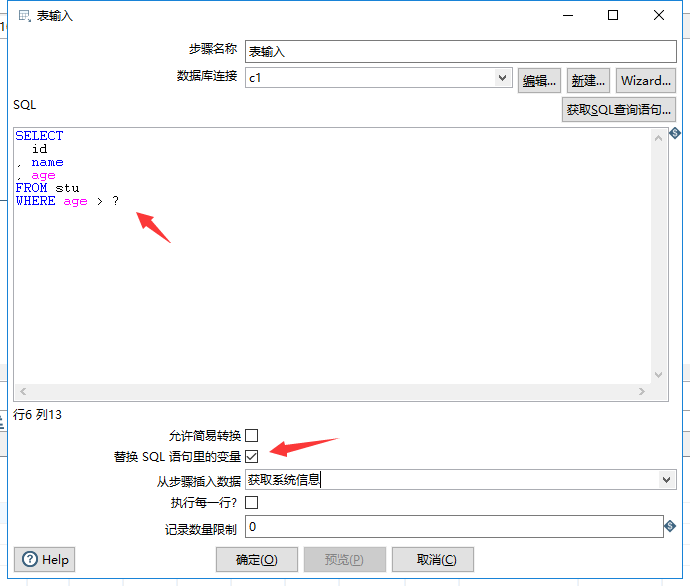
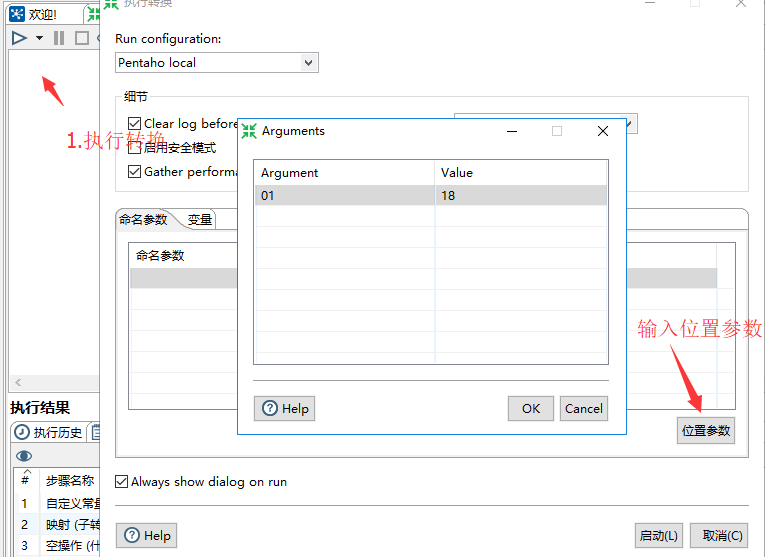
命名参数用法类似,之前也有介绍,使用age > ${arg1}
如果使用命令行方式,则:
pan test.ktr 18
// 如有空格,需要加双引号
2.变量
变量有作业下的设置变量和获取变量两种用法,分别对应将字段设置为字段和将变量设置为字段
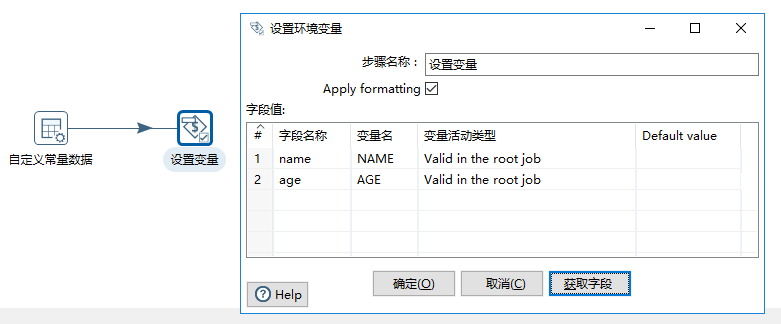
// 特别注意,设置的变量只能其它转换使用!!!

使用的方式,类似如下:(作业中设置变量环节)
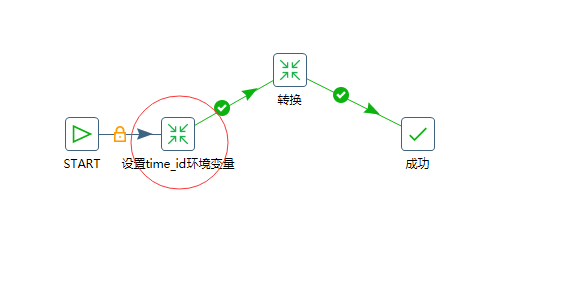
更多参数和变量的介绍,参考:https://blog.csdn.net/yimenglin/article/details/84520601
kettle.properties中同样支持设置变量(注意重启spoon)
并且,kettle.properties是支持密文的,这样就不用使用明文暴露密码了:
命令行下执行
encr -kettle 123
命令
得到 123 对应的密码是 2be98afc86aa7f2e4cb79ce10bec3fd89
直接在 kettle.properties 文件里设置
Password = Encrypted 2be98afc86aa7f2e4cb79ce10bec3fd89
kettle学习笔记(九)——子转换、集群与变量的更多相关文章
- DOCKER 学习笔记8 Docker Swarm 集群搭建
前言 在前面的文章中,已经介绍如何在本地通过Docker Machine 创建虚拟Docker 主机,以及也可以在本地Windows 创建虚拟主机,也是可以使用的.这一节,我们将继续学习 Docker ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- Redis学习笔记(十七) 集群(上)
Redis集群是Redis提供的分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移操作. 一个Redis集群通常由多个节点组成,在刚开始的时候每个节点都是相互独立的,他们处于一个只包含 ...
- Docker Swarm Mode 学习笔记(创建 Swarm 集群)
Swarm 集群由管理节点与工作节点组成. 初始化集群 使用命令:docker swarm init 如果你的 Docker 主机有多个网卡, 拥有多个 IP 地址, 必须使用 --advertise ...
- 【Redis学习之九】Redis集群:Twemproxy和HA
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 redis-3.0.4 主从模式对写压力没有分担,解决思路就 ...
- Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力.Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立 ...
- Redis学习笔记(二):Redis集群
集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能. 1.节点 一个节点就是一个运行在集群模式下的Redis服务器.启动Redis服务器时,通过判断cluster-enabl ...
- ELK学习笔记之ElasticSearch的集群(Cluster),节点(Node),分片(Shard),Indices(索引),replicas(备份)之间关系
[Cluster]集群,一个ES集群由一个或多个节点(Node)组成,每个集群都有一个cluster name作为标识----------------------------------------- ...
- 王雅超的学习笔记-大数据hadoop集群部署(十)
Spark集群安装部署
- 王雅超的学习笔记-大数据hadoop集群部署(七)
MySQL的安装部署
随机推荐
- 商业智能BI和报表的区别?
报表是数据展示工具,商业智能BI是数据分析工具. 报表工具是一类报表制作工具和数据展示工具,用于制作各类数据报表.图形报表.或者制作特定格式的电子发票联.流程单.收据等等. 商业智能的重点在于商业数据 ...
- Android Application中的Context和Activity中的Context的异同
一.Context是什么: 1.Context是维持Android程序中各组件能够正常工作的一个核心功能类,我们选中Context类 ,按下快捷键F4,右边就会出现一个Context类的继承结构图啦, ...
- CSS 小结笔记之em
1.为什么使用em em也是css中的一种单位,和px类似.很多人会疑惑为什么有了px之后还要使用em,而且em使用起来相对于px来讲比较麻烦. em主要是应用于弹性布局,下面给出一个小栗子说明em的 ...
- go语言练习:类型转换
package main import "fmt" func main() { var a int var b uint var c float32 var d float64 a ...
- beego快速入门
beego的官方网址:https://beego.me 参考文档:https://beego.me/quickstart 1:安装 您需要安装 Go 1.1+ 以确保所有功能的正常使用. 需要已经设置 ...
- 用例设计之API用例覆盖准则
基本原则 本文主要讨论API测试的用例/场景覆盖,基本原则如下: 用户场景闭环(从哪来到哪去) 遍历所有的实现逻辑路径 需求点覆盖 覆盖维度 API协议(参数&业务场景) 中间件检查 异常场景 ...
- ASP.NET Core 依赖注入最佳实践——提示与技巧
在这篇文章,我将分享一些在ASP.NET Core程序中使用依赖注入的个人经验和建议.这些原则背后的动机如下: 高效地设计服务和它们的依赖. 预防多线程问题. 预防内存泄漏. 预防潜在的BUG. 这篇 ...
- HDFS Lease Recovey 和 Block Recovery
这篇分析一下Lease Recovery 和 Block Recovery hdfs支持hflush后,需要保证hflush的数据被读到,datanode重启不能简单的丢弃文件的最后一个block,而 ...
- MySQL客户端连接方式
MySQL连接方式MySQL除了最常见的TCP连接方式外,还提供SOCKET(LINUX默认连接方式).PIPE和SHARED MEMORY连接方式.各连接方式的服务器.客户端启动选项,及连接默认值见 ...
- 将目录结构输出为json格式(zTree)
# -*- coding: UTF-8 -*- import json,os path = 'E:\\BACKUP' #返回空目录 def path_to_dict(path): d = {'name ...