Oracle表复杂查询
转自:https://www.cnblogs.com/w-gao/p/7288293.html
Oracle表复杂查询
聚合函数
max(字段值) -- 求最大值
min(字段值) -- 求最小值
sum(字段值) -- 求总和
avg(字段值) -- 求平均值
count(字段值) -- 求个数
group by 和 having 字句
group by : 用于对查询的结果分组统计
having 子句:用于过滤分组显示的结果
案例:
1.显示每个部门的平均工资和最高工资?
select avg(sal),max(sal) from emp group by deptno
2.显示每个部门的每种岗位的平均工资和最低工资?
select avg(sal),min(sal) from emp group by deptno,job
3.显示平均工资低于2000的部门号和它的平均工资?
select avg(sal) deptno from emp group by deptno having avg(sal) < 2000;
多表查询
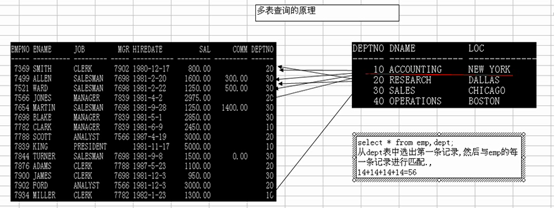
原理:
笛卡儿积: 在多表查询的时候,如果不带任何条件,则会出现笛卡儿积现象。
规定: 多表查询的条件至少不能少于表的个数-1;
案例:
1.显示雇员名,雇员工资及所在部门的名字?
select e.ename,e.sal, d.deptno
from emp e,dept d
where e.deptno = d.deptno
order by d.deptno;
2.显示部门号为10的部门名、员工名和工资?
select d.dname, e.ename, e.sa
l from emp e, dept d
where e.deptno = d.deptno and d.deptno = 10;
3.显示各个员工的姓名,工资,及其工资的级别?
select emp.ename ,emp.sal , salgrade.grade
from emp,salgrade
where emp.sal between salgrade.losal and salgrade.hisal;
自连接
案例:
1.显示“FORD”的上级?
select * from emp where emp.empno =
(select mgr from emp where ename = 'FORD');
2.显示各员工的姓名和他上级领导的姓名?
select worker.ename, boss.ename
from emp worker ,emp boss
where worker.mgr = boss.empno;
子查询
定义
嵌入到其他sql语句的select语句,也叫嵌套查询。
单行子查询
定义: 返回一行数据的子查询
案例:
如何显示SMITH同一部门的所有员工?
select * from emp where emp.deptno =
(select deptno from emp where ename = ‘SMITH’) and ename != 'SMITH';
多行子查询
定义:返回多行数据的子查询
案例:
显示10号部门的工作相同的员工姓名,工作?
select ename,job from emp where job in (
select job from emp where deptno = 10);
all( 大于最大的):
如何显示工资比30号部门高的员工的姓名、工资、部门号
select ename,sal,deptno from emp where sal > all(select sal from emp where emp.deptno = 30);
等效于
select ename,sal,deptno from emp where sal > (
select max(sal) from emp where deptno =30);
any( 大于最小的):
如何显示工资比30号部门任意员工高的员工的姓名、工资、部门号
select ename,sal,deptno from emp where sal > anyl(select sal from emp where emp.deptno = 30);
等效于
select ename,sal,deptno from emp where sal > (
select min(sal) from emp where deptno =30);
多列子查询
如何查询与smith的部门和岗位完全相同的所有雇员
select * from emp where (deptno,job) =
(select deptno,job from emp where ename = ‘SMITH’);
----------------------------------------------------
注: “(deptno,job) =(select deptno,job ”是有顺序的
from中的子查询
定义: 将select查询结果当作一个虚表处理
案例:
显示高于自己部门的平均工资的员工信息?
select t1.ename, t1.sal,t2.myavg from
emp t1,( select avg(sal) myavg ,deptno from emp group by deptno) t2
where t1.deptno = t2.deptno and t1.sal > t2.myavg;
显示每个部门的信息(编号,名称) 和人数?
select t1.dname, t1.deptno,t2.num from dept t1 , (select count(*) num,deptno from emp group by deptno) t2
where t1.deptno = t2.deptno(+);
--------------------------------------------------------
(+) 在左表示右外连接,在右表示左外连接
分页查询
mysql:
select * from 表名 where 条件 limit 从第几条取,取几条
sql server:
select top 4 * from 表名 where id not in (select top 4 id from 表名 where 条件)
---------------------------
排除前4条,再取4条,实际上是5-8条
oracle:
格式:
select * from (select rownum rn,t1.* from (select * from 表名 [ where 条件]) where rownum <= 末尾) t2 where t2.rn >= 开始;
---------------------------
rownum:伪列,用于显示数据的行索引。
select * from emp where rownum > = 3
说明: 因为oracle的行索引(rownum)是从第1开始索引的,所以不能用>=(条件无法成立),可以用<=。
解决: 采取截取结果集的方式,将已经查询好的查询结果再进行过滤。
三层:
第一层: select * from 表名 [ where 条件] --放条件,比如排序等
第二层: select rownum rn,t1.* from (select * from 表名 [ where 条件]) where rownum <= 末尾 --决定末尾位置
第三层: select * from (select rownum rn,t1.* from (select * from 表名 [ where 条件]) where rownum <= 末尾) t2
where t2.rn >= 开始; --决定开始位置
拓展:
复制表: create table mytest as select empno,ename,sal,comm,deptno from emp;
插入表:insert into mytest(empno,ename,sal,comm,deptno) select empno,ename,sal,comm,deptno from mytest;
内连接与外连接
内连接: 笛卡儿积过滤后的连接
案例:
select * from emp inner join dept on emp.deptno = dept.deptno;
等效于
select * from emp,dept where emp.deptno = dept.deptno
外连接:
案例:
测试表
学生表:
create table stu (id number,name varchar2(32));
insert into stu values(1,’tom’);
insert into stu values(2,’jerry’);
insert into stu values(3,’jack’);
insert into stu values(4,’rose’);
成绩表
create table exam(id number,grade number(6,2));
insert into exam(1,56);
insert into exam(2,76);
insert into exam(11,86);
要求1:显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩为空
select stu.id,stu.name,exam.grade from stu inner join exam on stu.id = exam.id;
结果:
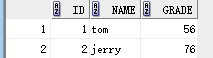
原因:在笛卡儿积连接之后,相同条件的才会匹配
左连接:select stu.id,stu.name,exam.grade from stu left join exam on stu.id = exam.id;
另一种写法: select stu.id,stu.name,exam.grade from stu , exam where stu.id = exam.id(+);
结果:
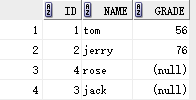
原因:连接后的数据以左边表为基准,即使对应的右边没有数据,也要显示为空。
要求2:显示所有成绩,如果没有名字匹配,显示空
右连接:select stu.id,stu.name,exam.grade from stu right join exam on stu.id = exam.id;
另一种写法: select stu.id,stu.name,exam.grade from stu , exam where stu.id(+) = exam.id;
结果:
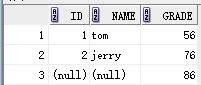
原因:连接后的数据以右边表为基准,即使对应的左边没有数据,也要显示为空。
小结: 左右外连接可以互为转换
比如:显示所有成绩,如果没有名字匹配,显示空
可以写出:select stu.id,stu.name,exam.grade from exam left join stu on stu.id = exam.id;
案例3:显示所有的成绩和所有人的名字,如果没有匹配值,就显示空
完全外连接:两个表查询,不管有么有匹配,都显示。
select stu.id,stu.name,exam.grade from exam full outer join stu on stu.id = exam.id;
结果:

Oracle表复杂查询的更多相关文章
- 08 Oracle表碎片查询以及整理(高水位线)
Oracle表碎片查询以及整理(高水位线) 1.表碎片的来源 当针对一个表的删除操作很多时,表会产生大量碎片.删除操作释放的空间不会被插入操作立即重用,甚至永远也不会被重用. 2.怎样确定是否有表碎片 ...
- Oracle 表空间查询与操作方法
一.查询篇 1.查询oracle表空间的使用情况 select b.file_id 文件ID, b.tablespace_name 表空间, b.file_name 物理文件名, b.bytes ...
- ORACLE表空间查询和管理【转】
红色是自由指定的~~--查询表空间SELECT D.TABLESPACE_NAME, SPACE "SUM_SPACE(M)", SPACE - NVL(F ...
- oracle表空间表分区详解及oracle表分区查询使用方法(转+整理)
欢迎和大家交流技术相关问题: 邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://g ...
- Oracle 表复杂查询之多表合并查询
转自:https://www.cnblogs.com/GreenLeaves/p/6635887.html 本文使用到的是oracle数据库scott方案所带的表,scott是oracle数据库自带的 ...
- oracle表空间查询维护命令大全之中的一个(数据表空间)史上最全
表空间是数据库的逻辑划分,一个表空间仅仅能属于一个数据库. 全部的数据库对象都存放在建立指定的表空间中.但主要存放的是表, 所以称作表空间.在oracle 数据库中至少存在一个表空间.即S ...
- 常用oracle表空间查询语句
--查询数据库表空间使用情况 select a.tablespace_name,a.bytes/1024/1024 "Sum MB",(a.bytes-b.bytes)/1024/ ...
- 转: Oracle表空间查询
1.查询数据库中的表空间名称 1)查询所有表空间 select tablespace_name from dba_tablespaces; select tablespace_name from us ...
- oracle表空间查询维护命令大全之二(undo表空间)
--undo表空间汇总 --查看全部的表空间名字 select name from v$tablespace; --创建新的UNDO表空间,并设置自己主动扩展參数; create undo table ...
随机推荐
- 【java】之查看JVM参数的值
查看JVM参数的值 可以根据java自带的jinfo命令: jinfo -flags pid 使用jmap可以查看某个Java进程中每个对象有多少个实例,占用多少内存,命令格式:jmap -histo ...
- Eclipse安装Markdown插件
Markdown Editor 安装Markdown插件可以实现 .md 和 .txt 文件的 Markdown 语法高亮,并提供 HTML 预览. 因为之前没有安装过别的插件,eclipse上安装插 ...
- 峰Redis学习(4)Redis 数据结构(List的操作)
第四节:Redis 数据结构之List 类型 存储list: ArrayList使用数组方式 LinkedList使用双向链接方式 双向链接表中增加数据 双向链接表中删除数据 存储list常用 ...
- 用R语言实现对不平衡数据的四种处理方法
https://www.weixin765.com/doc/gmlxlfqf.html 在对不平衡的分类数据集进行建模时,机器学**算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带 ...
- Java-Runoob-高级教程-实例-方法:06. Java 实例 – 方法覆盖
ylbtech-Java-Runoob-高级教程-实例-方法:06. Java 实例 – 方法覆盖 1.返回顶部 1. Java 实例 - 方法覆盖 Java 实例 前面章节中我们已经学习了 Jav ...
- html标签SEO规范
原文地址:http://blog.sina.com.cn/s/blog_6c3898dd0100whr7.html 1.<!--页面注解--> 2.<html> 3.<h ...
- python的导包问题
有事会遇到在python代码中导入包错误问题,本文简单对python包的引入做简单介绍 简单说,我认为python导包一共有3种情况,分别是: 要导的包与当前文件在同一层要导的包在当前文件的底层(就是 ...
- 06-ICMP: Internet 控制报文协议
I C M P经常被认为是I P层的一个组成部分.它传递差错报文以及其他需要注意的信息. I C M P报文通常被I P层或更高层协议( T C P或U D P)使用.一些I C M P报文把差错报文 ...
- [UE4]Delay的使用技巧:改变引擎执行顺序
如果要游戏一开始就让机器人开火,但这是引擎还没有执行到武器的创建步骤,就可以使用“Delay”并设置函数的等待时间,让引擎先执行创建枪的步骤,然后机器人开火就没问题了.
- phpmyadmin在nginx环境下配置错误
location ~ \.css { add_header Content-Type text/css; } location ~ \.js { ...