07_python_集合深浅拷贝
一、join
li = ["李嘉诚", "麻花藤", "林海峰", "刘嘉玲"]
s = "_".join(li) # 循环遍历列表,把列表中的每一项用''_''拼接
print(s)
结果:
李嘉诚_麻花藤_林海峰_刘嘉玲
li = "花闺"
s = "_".join(li)
print(s)
结果:
花_闺
li = [11, 22, 33, 44]
for e in li: # for 循环内部存在一个变量来记录当前被访问循环的位置索引,每次删除都会涉及元素移动
li.remove(e)
print(li)
结果:
[22, 44]
由于删除元素会导致元素的索引改变, 所以容易出现问题. 尽量不要再循环中直接去删 除元素. 可以把要删除的元素添加到另⼀个集合中然后再批量删除.
li = [11, 22, 33, 44]
li_new = []
for el in li:
li_new.append(el)
for i in li_new:
li.remove(i)
print(li)
字典删除元素
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦⽼板'}
dic_del_list = []
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k)
for el in dic_del_list:
del dic[el]
print(dic)
二、fromkeys()
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"])
print(dic)
结果:
{'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']}
fromkeys()不是改变字典,它是一个类方法,作用是创建新字典前⾯列表中的每⼀项都会作为key, 后⾯列表中的内容作为value. ⽣成新dict,fromkeys正常来说应该是类名访问的
d = dict.fromkeys(['a','b'],[])
d['a'].append('alex')
结果:
{‘a’:['alex'], 'b':['alex']}
# 所有key用的是同一个列表,改变其中一个,另一个也跟着改变
三、集合 set()
li = [1,2,3,1,1,1,1,2,2,2,4,4,4,5,5,5,5]
se = set(li)
li_new = list(se)
print(li_new)
四、深浅拷贝
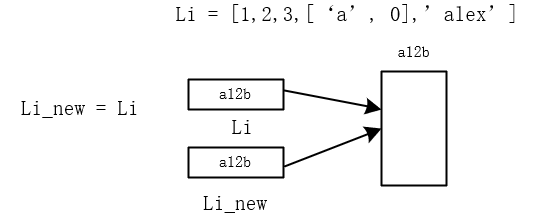

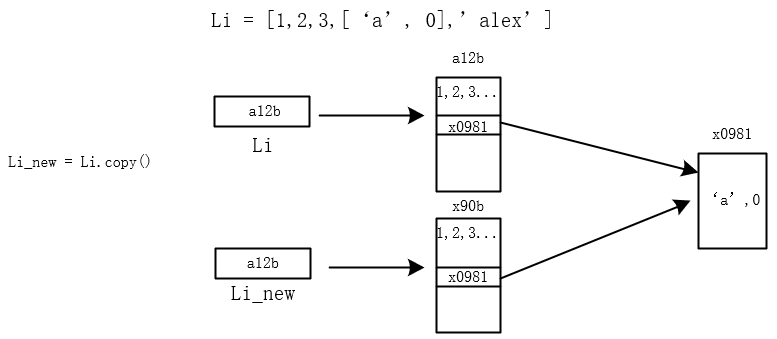
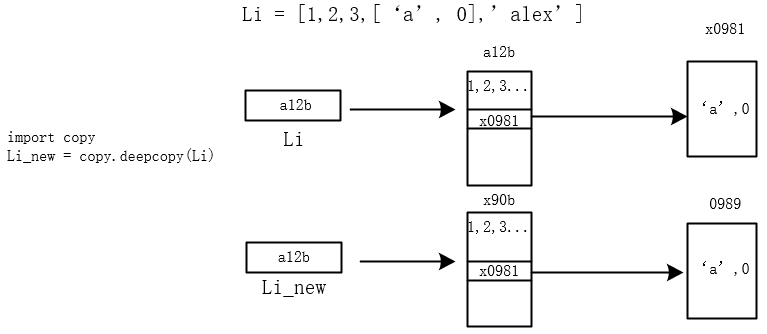
07_python_集合深浅拷贝的更多相关文章
- python学习打卡 day07 set集合,深浅拷贝以及部分知识点补充
本节的主要内容: 基础数据类型补充 set集合 深浅拷贝 主要内容: 一.基础数据类型补充 字符串: li = ["李嘉诚", "麻花藤", "⻩海峰 ...
- 6.Python初窥门径(小数据池,集合,深浅拷贝)
Python(小数据池,集合,深浅拷贝) 一.小数据池 什么是小数据池 小数据池就是python中一种提高效率的方式,固定数据类型,使用同一个内存地址 小数据池 is和==的区别 == 判断等号俩边的 ...
- Python基础知识(六)------小数据池,集合,深浅拷贝
Python基础知识(六)------小数据池,集合,深浅拷贝 一丶小数据池 什么是小数据池: 小数据池就是python中一种提高效率的方式,固定数据类型使用同一个内存地址 代码块 : 一个文 ...
- Day7--Python--基础数据类型补充,集合,深浅拷贝
一.基础数据类型补充 1.join() 把列表中的每一项(必须是字符串)用字符串拼接 与split()相反 lst = ["汪峰", "吴君如", " ...
- python摸爬滚打之day07----基本数据类型补充, 集合, 深浅拷贝
1.补充 1.1 join()字符串拼接. strs = "阿妹哦你是我的丫个哩个啷" nw_strs = "_".join(strs) print(nw_s ...
- Python学习基础(二)——集合 深浅拷贝 函数
集合 # 集合 ''' 集合是无序不重复的 ''' # 创建列表 l = list((1, 1, 1)) l1 = [1, 1, 1] print(l) print(l1) print("* ...
- set集合深浅拷贝以及知识补充
一. 对之前的知识点进行补充. 1. str中的join方法. 把列表转换成字符串 li = ["李嘉诚", "麻花藤", "黄海峰", & ...
- 基本数据类型补充 set集合 深浅拷贝
一.基本数据类型补充 1,关于int和str在之前的学习中已经介绍了80%以上了,现在再补充一个字符串的基本操作: li = ['李嘉诚','何炅','海峰','刘嘉玲'] s = "_&q ...
- Python学习---列表/元组/字典/字符串/set集合/深浅拷贝1207【all】
1.列表 2.元组 3.字典 4.字符串 5.set集合 6.深浅拷贝
随机推荐
- Python内置的subprocess.Popen对象
具体内容参见:https://docs.python.org/3/library/subprocess.html 大概来说,就是可以对应输入的命令产生一个进程,该进程实例内置如下方法. | comm ...
- 【Linux】CentOS 7.4 安装 MySQL 8.0.12 解压版
安装环境/工具 1.Linux(CentOS 7.4版) 2.mysql-8.0.12-el7-x86_64.tar.gz 安装步骤 参考:https://dev.mysql.com/doc/refm ...
- 2018.10.26 NOIP训练 数数树(换根dp)
传送门 换根dpdpdp傻逼题好像不好码啊. 考虑直接把每一个二进制位拆开处理. 先dfsdfsdfs出每个点到1的异或距离. 然后分类讨论一波: 如果一个点如果当前二进制位到根节点异或距离为1,那么 ...
- C语言三种方法调用数组
#include <stdio.h> /********************************* * 方法1: 第一维的长度可以不指定 * * 但必须指定第二维的长度 * *** ...
- hadoop 组件 hdfs架构及读写流程
一 . Namenode Namenode 是整个系统的管理节点 就像一本书的目录,储存文件信息,地址,接受用户请求,等 二 . Datanode 提供真实的文件数据,存储服务 文件块(block)是 ...
- CPU load高而使用率低的问题分析
最近服务器上出现了一个很诡异的问题,症状如下图所示: 查看进程发现: 如上图所示,非常多的df -h进程没有退出.于是手工kill掉这些 df -h进程.cpu load恢复正常. 至于为什么会有这么 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 20155326 2016-2017-2《Java程序设计》课程总结
20155326 2016-2017-2<Java程序设计>课程总结 (按顺序)每周作业链接汇总 20155326刘美岑的第一次作业:第一次写博客,写下了对java的期待 20155326 ...
- noip第27课作业
1. 繁忙的都市 [问题描述] 城市C是一个非常繁忙的大都市,城市中的道路十分的拥挤,于是市长决定对其中的道路进行改造.城市C的道路是这样分布的:城市中有n个交叉路口,有些交叉路口之间有道路相连,两个 ...
- SurfaceView+MediaPlayer播放视频
SurfaceView拥有独立的绘图表面,因此SurfaceView的UI就可以在一个独立的线程中进行行绘制.又由于不占用主线程资源,SurfaceView一方面可以实现复杂而高效的UI,另一方面又不 ...