机器学习基础——模型参数评估与选择
当看过一些简单的机器学习算法或者模型后,对于具体问题该如何评估不同模型对具体问题的效果选择最优模型呢。
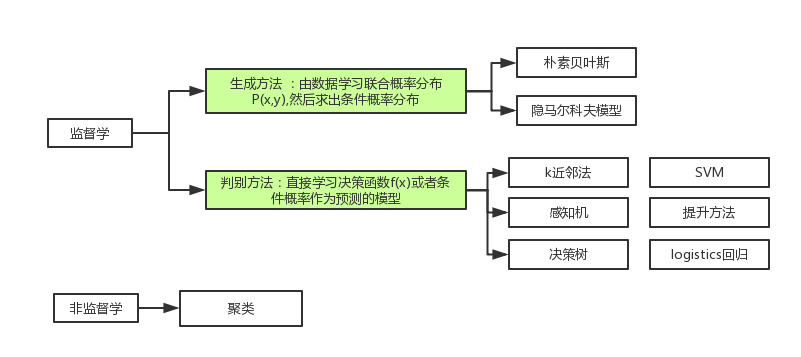
机器学习分类
1. 经验误差、泛化误差
假如m个样本中有a个样本分类错误
错误率:E = a / m;
精度: 1 - E
训练误差: 又叫经验误差,是指算法/模型在训练样本上的误差
泛化误差:算法/模型在新样本上的误差
显然我们希望得到泛化误差小的机器学习算法。
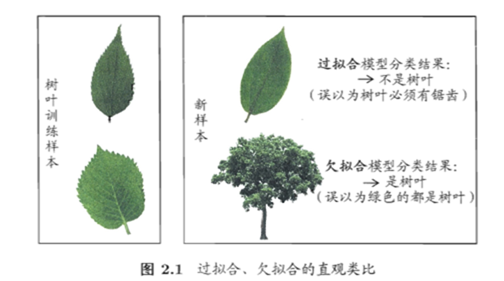
2.欠拟合、 过拟合
欠拟合:欠拟合是指讯息能力低下,本来一些有的特征没有学习到。
解决方法:欠拟合一般比较容易克服,例如在决策树学习中扩展分支在神经网络学习中增加学习轮数就可以。
过拟合:模型把训练样本学的“太好”,很可能把训练样本自身的一些特点当做了所有潜在样本都会具有的一般性质,这样就会导致泛化能力下降。
解决方法: 很难克服或者彻底避免。
下面这张图对欠拟合/过拟合解析的十分到位:
3. 样本采集
3. 1 留出法
直接将数据集D划分成两个互斥的集合,其中一个作为训练集S,另一个作为测试集T 即: D = S ∪ T , S ∩ T = ∅ . 在S上训练出模型后用T来评估其测试误差,作为泛化误差的评估。
需要注意的训练/测试集的划分要尽可能的保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。 如果从采样的角度看数据集划分过程,则保留类别比例的采样方式通常称为分层采样。
单层留出法得到的评估结果往往不够稳定可靠,在使用留出法时,一般采用若干次随机划分、重复进行试验评估后取平均值为留出法结果。
缺点: 若训练集S包含绝大多数样本则训练出的模型可能更接近与用D训练处的模型,但由于T比较小,评估结果可能不够稳定准确。 若令测试机包含多一些样本,则训练集S与D差别更大,被评估的模型与用D训练出的模型相比可能有较大差别,从而降低了评估结果的保真性。 常见的做法是将 2/3 ~ 4/5 的样本用于训练,剩余样本用于测试。
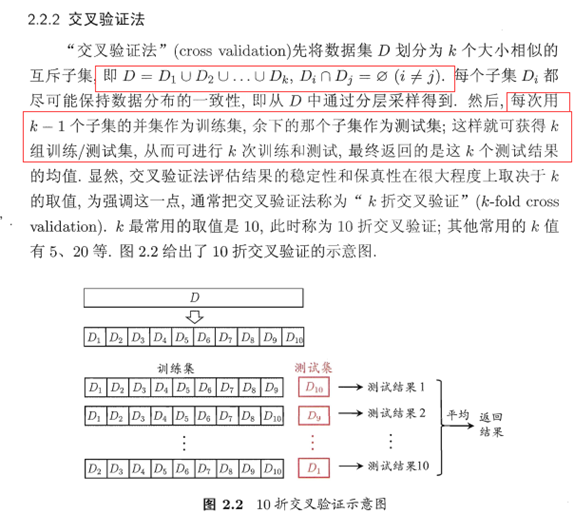
3.2 交叉验证法
3.3 自助法
留出法和交叉验证法都有一个缺点: 需要保留一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。
自助法: 给定包含m个样的数据集D,我们对它进行采样产生数据集D_:每次随机从D中挑选一个样本,将其拷贝到D_中,然后将该样本放回到D中,下次采样时同样可以被采到。
明显D中有一部分样本会多次出现,而另一部分样本不出现。于是估计样本在m次采样中始终不被采到的概率:
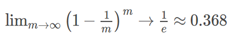
即通过自助采样,初始数据集D中约有0.368的样本没有出现在D_中。 我们可以将D\D_用作测试集,这样实际评估的模型与期望评估的模型都是用m个训练样本。
4 . 性能度量——查准率、查全率
对于二分类问题进行如下统计:
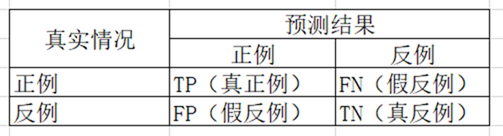
查准率:
P = TP / (TP + FP)
查全率:
R = TP / (TP + FN)
以预测癌症为例,正例为癌症,反例不是癌症。 查准率表示预测为癌症实际发生癌症的概率,而查全率是指预测为癌症的覆盖率(部分预测为反例但实际情况确实正例)。
其它机器学习算法:
监督学习——随机梯度下降算法(sgd)和批梯度下降算法(bgd)
参考:
周志华 《机器学习》
《推荐系统实战》
机器学习基础——模型参数评估与选择的更多相关文章
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- 数据分析之Matplotlib和机器学习基础
一.Matplotlib基础知识 Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形. 通过 Matplotlib,开发者可以仅需 ...
- 机器学习:模型泛化(LASSO 回归)
一.基础理解 LASSO 回归(Least Absolute Shrinkage and Selection Operator Regression)是模型正则化的一定方式: 功能:与岭回归一样,解决 ...
- Python机器学习基础教程-第2章-监督学习之决策树集成
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之决策树
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之K近邻
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- TensorFlow系列专题(二):机器学习基础
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/ ,学习更多的机器学习.深度学习的知识! 目录: 数据预处理 归一化 标准化 离散化 二值化 哑编码 特征 ...
随机推荐
- s5-1 网络层引言
网络层要做什么? 源和目的之间的网络有哪些类? 数据报网络 提供无连接的服务 虚电路网络 提供面向连接的服务 网络层的目标:把数据分组一路送到接收机. 网络层利用下层--数据链路层提供的服 ...
- Linux查看登录到服务的用户,查看用户的操作已经剔掉干坏事的用户的命令
在工作中,我们有时候会经常的切换用户,有时候会忘记切换到哪个用户了,我们就需要知道当前登录的用户时谁,可以使用: whoami 查看当前登录到系统中的用户有哪些: who 列表中显示,第一列是用户名, ...
- JMeter压力测试及服务器状态监控教程
转载自:https://blog.csdn.net/cbzcbzcbzcbz/article/details/78023327 前段时间公司需要对服务器进行压力测试,包括登录前的页面和登录后的页面,主 ...
- AtCoder Beginner Contest-060
A - Shiritori Problem Statement You are given three strings A, B and C. Check whether they form a wo ...
- 2.2.9静态同步synchronized方法与synchronized(class)代码块
关键字synchronized还可以应用在static静态方法上,这样写那是对当前的*.java文件对应的class类进行持锁, 测试如下 package com.cky.bean; /** * Cr ...
- Beta阶段第一篇 Scrum 冲刺博客
介绍小组新加入的成员,Ta担任的角色 新成员 担任角色 张晨晨 测试 理由:晨晨代码能力有待提高,但心思细腻有耐心,适合测试工作. 讨论是否需要更换团队的PM 通过团队讨论决定不更换团队PM,理由是在 ...
- noip第2课作业
1. 大象喝水 [问题描述] 一只大象口渴了,要喝20升水才能解渴,但现在只有一个深h厘米,底面半径为r厘米的小圆桶(h和r都是整数).问大象至少要喝多少桶水才会解渴. 输入:输入有一行,包行两 ...
- UT源码105032014098
(2)NextDate函数问题 NextDate函数说明一种复杂的关系,即输入变量之间逻辑关系的复杂性 NextDate函数包含三个变量month.day和year,函数的输出为输入日期后一天的日期. ...
- FastReport自动换行及行高自适应
- Android-AndroidStudio加载工程方式-gradle文件夹
例如:在其他地方,其他工作人员哪里的OpenGateDemo工程是OK的, 然后Copy到李四的电脑上运行是报错,其实所有的错误都和gradle有关: 第一步,李四电脑运行OpenGateDemo工程 ...