mongodb oplog与数据同步
1. 复制集(Replica sets)模式时,其会使用下面的local数据库
local.system.replset 用于复制集配置对象存储 (通过shell下的rs.conf()或直接查询)
local.oplog.rs 一个capped collection集合.可在命令行下使用--oplogSize 选项设置该集合大小尺寸.
local.replset.minvalid 通常在复制集内使用,用于跟踪同步状态(sync status)
2. 主从复制模式(Master/Slave)
* Master
o local.oplog.$main 存储"oplog"信息
o local.slaves 存储在master结点上相应slave结点的同步情况(比如syncTo时间戳等)
* Slave
o local.sources 从结点所要链接的master结点信息(可通过--source配置参数指定)
* Other
o local.me 未知待查:)
o local.pair.* (replica pairs选项,目前已不推荐使用)
3. 还有oplog的数据结构(存储在local.oplog.$main)
{ ts : ..., op: ..., ns: ..., o: ... o2: ... }
上面就是一条oplog信息,复制机制就是通过这些信息来进行节点间的数据同步并维护数据一致性的,其中:
ts:8字节的时间戳,由4字节unix timestamp + 4字节自增计数表示。
这个值很重要,在选举(如master宕机时)新primary时,会选择ts最大的那个secondary作为新primary。
op:1字节的操作类型,例如i表示insert,d表示delete。
ns:操作所在的namespace。
o:操作所对应的document,即当前操作的内容(比如更新操作时要更新的的字段和值)
o2: 在执行更新操作时的where条件,仅限于update时才有该属性
其中op,可以是如下几种情形之一:
"i": insert
"u": update
"d": delete
"c": db cmd
"db":声明当前数据库 (其中ns 被设置成为=>数据库名称+ '.')
"n": no op,即空操作,其会定期执行以确保时效性
- ts: the time this operation occurred.
- h: a unique ID for this operation. Each operation will have a different value in this field.
- op: the write operation that should be applied to the slave. n indicates a no-op, this is just an informational message.
- ns: the database and collection affected by this operation. Since this is a no-op, this field is left blank.
- o: the actual document representing the op. Since this is a no-op, this field is pretty useless.
- for the update, there are two o fields (o and o2). o2 give the update criteria and o gives the modifications (equivalent to update()‘s second argument).
4. 同步系统设计
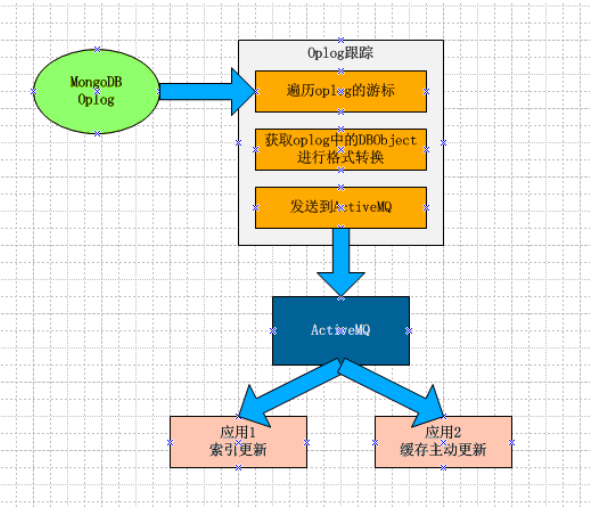
mongoDB oplog的说明:
如果需要及时获取mongoDB的增量信息,就可以应用oplog了!
常用的场景模式:索引更新,主动更新缓存等。
通常一个服务监控oplog,将“增量信息”经过一定的处理后塞到ActiveMQ中,相关的应用程序再从ActiveMQ中获取消息进行消费。
注意点:
1)如果当前服务断掉了,要有个断点机制,下次可以接着来。这个主要是对ts字段进行控制。
因此需要实时记录读到了什么位置。
2)如果应用端是异构的,采用一种跨语言的协议,例如json。
3)消息中间件(ActiveMQ)起到解耦、缓冲的作用。
mongodb oplog与数据同步的更多相关文章
- Mongodb 副本集 数据同步简单测试
副本集的搭建,请见 CENTOS6.5 虚拟机MONGODB创建副本集 接下来将简单说明下副本集之间的数据同步. 1.首先,进入primary节点 MOGO_PATH/bin/mongo -por ...
- MongoDB Oplog
Capped Collections MongoDB有一种特殊的Collection叫Capped collections,它的插入速度非常快,基本和磁盘的写入速度差不多,并且支持按照插入顺序高效的查 ...
- MongoDB副本集配置系列十一:MongoDB 数据同步原理和自动故障转移的原理
1:数据同步的原理: 当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步: 1:检查自己local库的oplog.rs集合找出最近的时间戳. 2:检查Primary ...
- MongoDB副本集配置系列十:MongoDB local库详解和数据同步原理
1:local库是MongoDB的系统库,记录着时间戳和索引和复制集等信息 gechongrepl:PRIMARY> use local switched to db local gechong ...
- MongoDB 复制集 (三) 内部数据同步
一 数据同步 一个健康的secondary在运行时,会选择一个离自己最近的,数据比自己新的节点进行数据同步.选定节点后,它会从这个节点拉取oplog同步日志,具体流程是这样的: ...
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- MongoDB 初始化数据同步
MongoDB初始化数据同步: 副本集中的成员启动之后,就会检查自身的状态,确定是否可以从某个成员那里进行同步.如果不行的话,尝试从其他成员那里进行完整的数据复制. 这个过程就是初始化同步(initi ...
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
随机推荐
- SQL SERVER的锁机制(三)——概述(锁与事务隔离级别)
五.锁与事务隔离级别 事务隔离级别简单的说,就是当激活事务时,控制事务内因SQL语句产生的锁定需要保留多入,影响范围多大,以防止多人访问时,在事务内发生数据查询的错误.设置事务隔离级别将影响整条连接. ...
- [WC2005]双面棋盘(线段树+并查集)
线段树+并查集维护连通性. 好像 \(700ms\) 的时限把我的常数超级大的做法卡掉了, 必须要开 \(O_2\) 才行. 对于线段树的每一个结点都开左边的并查集,右边的并查集,然后合并. \(Co ...
- postgresql-shared_buffers调整
shared_buffers大小调整: http://www.rummandba.com/2011/02/sizing-sharedbuffer-of-postgresql.html SELECT ...
- maven封装jar包遇到的问题
使用eclipse编译后可以生成jar包,使用mvn clean package指令打包报错,错误如下:No compiler is provided in this environment. Per ...
- [原创]Chorme密码读取工具\Firefox密码读取工具
工具: getBrowserPWD编译: VC作者: K8哥哥博客: http://qqhack8.blog.163.com发布: 2017/11/24 16:16:17 简介: 有时为了方便我们会让 ...
- sql 游标 跳出循环 和进入下一个循环
1 使用break 结束整个循环. 2 使用continue 结束当前循环,进入下已循环. 注意:使用continue造成死循环,是因为continue后又执行与上次相同的fetch了. 解决办法 ...
- dubbo源码阅读之SPI
dubbo SPI SPI,全程Service Provider interface, java中的一种借口扩展机制,将借口的实现类注明在配置文件中,程序在运行时通过扫描这些配置文件从而获取全部的实现 ...
- [Umbraco] xslt语言介绍及与umbraco的关系
XSLT是扩展样式表转换语言(Extensible Stylesheet Language Transformations)的简称,这是一种对XML文档进行转化的语言,XSLT中的T代表英语中的“转换 ...
- 【原创】手动导入SQLServer数据到SQLCE方法
我找到一个工具,可以很容易把SQLServer里的数据导入到SQLCE: 工具名:Export2SqlCe.exe, 下载路径: http://exportsqlce.codeplex.com/rel ...
- 剑指offer五之用两个栈实现队列
一.题目 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 二.思路 1.Push操作:将数据直接压入stack1即可 2.Pop操作:将stack1中的数据全部弹 ...