hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战。Hadoop作为一个开源的分布式并行处理平台,以其高拓展、高效率、高可靠等优点越来越受到欢迎。这同时也带动了hadoop商业版的发行。这里就通过大快DKhadoop为大家详细介绍一下hadoop大数据平台架构内容。
目前国内的商业发行版hadoop除了大快DKhadoop以外还有像华为云等。虽然发行方不同,但在平台架构上相似,这里就以我比较熟悉的dkhadoop来介绍。
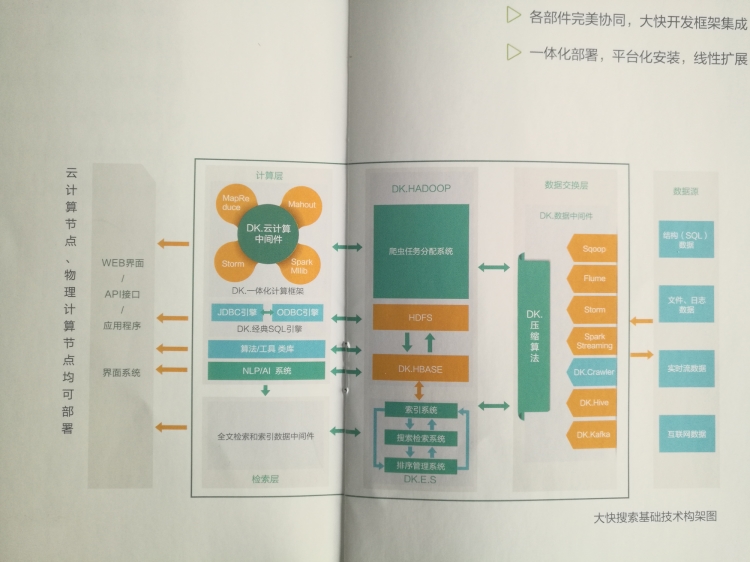
1、大快Dkhadoop,可以说是集成了整个HADOOP生态系统的全部组件,并对其进行了深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了非常高的提升。这一点也是个人觉得dkhadoop比我之前使用的另外一个商业发行版的要好的,国内的大部分商业发行版hadoop可以说都是二次包装,dkhadoop做的好的就是敢在原生态的基础上进行开发。
2、大快DKhadoop中间件技术把大数据集群配置简化成三种节点,这样不仅简化了集群的管理运维,还增强了集群的可用性和稳定性。Dkhadoop中间件集成了apache的很多组件包含了从文件、SQL、日志、消息到爬虫和流数据以及异构数据的支持;集成了大快的压缩算法,和数据同步分发技术,实现了数据的导入和减少调动的同时实现,对于有实时数据要求的项目具有不可替代的技术优势。
3、大快DKhadoop商业发行版还是保持了开源系统的优点的,可以与开源系统100%兼容。对于那些基于开源平台开发的大数据应用并不需要经过改动同样可以在dkhadoop上高效运行。
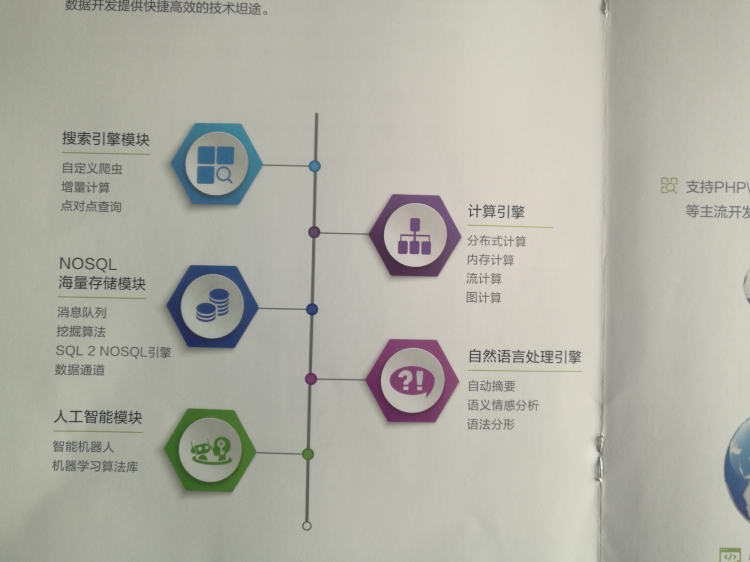
4、DKhadoop一体化开发框架提供了大数据、搜索、自然语言处理和人工智能开发中常用的二十多个类,总计一百余种方法,实现了开发效率的大幅提升。DK.HADOOP整合集成了NOSQL数据库,简化了文件系统与非关系数据库之间的编程;DK.HADOOP改进了集群同步系统,使得HADOOP的数据处理更加高效。
5、DKhadoop的SQL版本,还提供了分布式MySQL的集成,传统的信息系统,可无缝的实现面向大数据和分布式的跨越。
6、ES:快递DKhadoop的搜索系统是在开源ES系统上二次开发的,支持完成的全文搜索。整合了对中文搜索的有效支持以及对大快数据同步技术的支持后的高性能版本,DK.ES是DKH的核心组件之一,仅随DKH集成整合了对中文搜索的有效支持以及对大快数据同步技术的支持后的高性能版本,DK.ES是DKhadoop的核心组件之一。
7、汉语言处理组件:大快的汉语言处理是目前国内使用率最高的开源自然语言处理开发包。
简单的就介绍这些了吧,想要进一步了解的可以搜索查询下或者下载一下dkhadoop学习版本了解。以下是关于dkhadoop版本的问题:
DKH标准版 DKH-分布式SQL版 DK.HADOOP发行版
DKH标准版有三个不同的子版本:用于开发调试的单机版;支持三节点的学习版;支持5节点以上的标准服务器版
DKH-分布式SQL版有两个子版本:学习版、服务器版
hadoop大数据技术架构详解的更多相关文章
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- Google大数据技术架构探秘
原文地址:https://blog.csdn.net/bingdata123/article/details/79927507 Google是大数据时代的奠基者,其大数据技术架构一直是互联网公司争相学 ...
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- Java+大数据开发——HDFS详解
1. HDFS 介绍 • 什么是HDFS 首先,它是一个文件系统,用于存储文件,通过统一的命名空间--目录树来定位文件. 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角 ...
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 入门大数据---Hbase协处理器详解
一.简述 Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立"二级索引",难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hbase 中,统计数 ...
- 入门大数据---Kafka生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- 入门大数据---Kafka消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- 入门大数据---Hbase 过滤器详解
一.HBase过滤器简介 Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predic ...
随机推荐
- centos6.5下 hdp-2.4.2安装
(1)准备工作 /usr/sbin/sestatus -v getenforce1./usr/sbin/sestatus -v ##如果SELinux status参数为enabled即为开启状态SE ...
- Maven错误信息:Missing artifact jdk.tools:jdk.tools:jar:1.6
在pom.xml中添加依赖: <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.too ...
- Spring整合Shiro并扩展使用EL表达式
Shiro是一个轻量级的权限控制框架,应用非常广泛.本文的重点是介绍Spring整合Shiro,并通过扩展使用Spring的EL表达式,使@RequiresRoles等支持动态的参数.对Shiro的介 ...
- SpringMVC【参数绑定、数据回显、文件上传】
前言 本文主要讲解的知识点如下: 参数绑定 数据回显 文件上传 参数绑定 我们在Controller使用方法参数接收值,就是把web端的值给接收到Controller中处理,这个过程就叫做参数绑定.. ...
- 用Canvas生成随机验证码(后端前端都可以)
一 .使用前端生成验证码 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> ...
- APNS IOS 消息推送
一.Apns简介: Apns是苹果推送通知服务. 二.原理: APNs会对用户进行物理连接认证,和设备令牌认证(简言之就是苹果的服务器检查设备里的证书以确定其为苹果设备):然后,将服务器的信息接收并且 ...
- grub4dos和winsetupfromusb1.4
其实grub4dos也是一个多系统启动盘制作软件,GRUB4DOS 最大的成功之处就是既学习了windows的方便易用,又引入linux的强大功能.http://baike.baidu.com/lin ...
- 微信小程序之swiper组件高度自适应
微信小程序之swiper组件高度自适应 要求: (顶部广告栏 ) 改变swiper组件的固定高度,使之随内部每张图片的高度做自适应 原理: 图片加载完之后,获取图片的原始宽高,根据宽高比,计算出适应后 ...
- 快速失败机制--fail-fast
fail-fast 机制是Java集合(Collection)中的一种错误机制.当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast(快速失败)事件.例如:当某一个线程A通过iter ...
- 【Linux】 linux的进程系统一点补充
linux进程系统 ■ 程序 vs. 进程 程序静态地存放在磁盘中.用户可以触发执行程序,被触发后的程序就存进内存中成为一个个体,即为进程. 有些进程(比如crond需要每分钟都扫描.守护进程等等)是 ...