Oracle Sql 胡乱记
/Oracle查询优化改写/
--1、coalesce 返回多个值中,第一个不为空的值
select coalesce('', '', 's') from dual;
--2、order by
-----dbms_random.value 生产随机数,利用随机数对查询结果进行随机排序
select * from emp order by dbms_random.value;
--指定查询结果中的一列进行排序
select * from emp order by 4;
-----order by 中认为null是最大所以null会排在第一或者最后一个
-----可以利用 nulls first 或者 nulls last 对null进行排序处理
select * from emp order by comm nulls first;
select * from emp order by comm nulls last;
----- 多列排序,job 降序排列,如果工作一样,按照工号升序排列
select * from emp order by job desc, empno asc;
------依次按照job,empno降序排序
select * from emp order by job, empno desc;
------将empno = 7934 的排在第一位,其余的按照empno将序排列
------ORDER BY DECODE 按照自定义的顺序排序,如果没有
------定义则按照原始值排序 case when then else end 也是同样的道理
select * from emp order by decode(empno, 7934, 2, 1) asc;
--先按照打的分组排序,然后在分组内按照字段排序
select empno, ename, sal
from emp
order by case
when sal <= 5000 and sal >= 3000 then
0
when sal < 3000 and sal > 1000 then
1
when sal < 1000 then
2
else
3
end asc,
3 asc;
--2
select empno,
ename,
case
when sal <= 5000 and sal >= 3000 then
0
when sal < 3000 and sal > 1000 then
1
when sal < 1000 then
2
else
3
end,
sal
from emp
order by 2 asc, 3 asc;
--3、_ 通配符,代替一个字符。
select T.*, T.ROWID from emp T where t.ename like '_EN%';
---可以通过,将_表示为一个普通的字符,俩种写法
select T.*, T.ROWID from emp T where t.ename like '_EN%' ESCAPE '';
--4、tanslate
-----对应字符一一替换,每一个字符的替换相当于执行一次REPLACE('C','1')
-----会将job字段中的C全部替换为1
select translate(job, 'CRK', '123') from emp t where t.job = 'CLERK';
---第二个字段为空的时候返回null
select translate(job, 'CRK', '') from emp t where t.job = 'CLERK';
---可以利用这个函数,删除字段的部分字符,对应位置字符为空
select translate(job, '1CRK', '1') from emp t where t.job = 'CLERK';
--5、内连接、左连接、右连接、外连接
--SQL-92标准写法,不建议用Oracle特有的= + 来表示连接
--inner join on left join on right join on outer join on
---左右连接的时候,只过滤左边或者右边的数据,用左连接作为例子
select a.empno, a.job, a.comm, b.empno, b.job, b.comm
from emp a
left join emp2 b
on (a.empno = b.empno and b.comm is not null);
select a.empno, a.job, a.comm, b.empno, b.job, b.comm
from emp a, emp2 b
where a.empno = b.empno(+)
and b.comm(+) is not null;
--6、in 多列写法
select *
from emp t
where (t.empno, t.ename) in (select t2.empno, t2.ename from emp t2);
---not in 注意事项:如果在子查询结果中包含null,not in 则返回null
select * from emp t where t.mgr not in (select mgr from emp2);
-- 7、insert into 如果表中有默认字段吗,那么不能显示的插入null,否则表中的字段值
---不会是默认值,依然是null
---8、形成数据结构
---level 代表总共有几层树形结构
select level from dual connect by level;
---9、正则表达式(没必要记住,了解规则和用途就可以了)
---regexp_count 统计匹配的
---regexp_replace 替换匹配的
---regexp_like 用正则表达式模糊查询
select regexp_count('abc,bcd,ddd,4434', ',') from dual;
select regexp_replace('abc,bcd,ddd,4434', ',') from dual;
---X 报表分析精华--Oracle分析函数
--listagg(x,',') within group (order by x)
--将某个字段的多列用逗号(,)连接起来
--同样的方法有wm_concat,但是
select job, listagg(ename, ',') within group(order by ename asc)
from emp
group by job;
---10、instr 字符串位置查找函数
--- 查找分割符的位置,然后截取
--- 从第一个字符开始,检索第二次出现的位置
select instr('zzz,xxx,tt', ',', '1', '2') from dual;
---11、count(*) 当表中没有数据时返回一条数据值为0,当有group by 的时候 没有数据返回
---12、 sum() over (order by x) 按顺序累加
---(如果需要计算累计差,可以将数字转换为负数,然后计算累积和)
select ENAME, SAL, SUM(SAL) OVER(ORDER BY EMPNO) from emp;
---13、分析函数
----按照分组排序获取第一个值或者最后一个值
---- max(ename) keep(dense_rank first order by sal desc) over()
select empno,
ename,
sal,
max(ename) keep(dense_rank first order by sal desc) over(),
max(sal) keep(dense_rank first order by sal desc) over(),
max(ename) keep(dense_rank last order by sal desc) over()
from emp;
---获取分组的最后一个值
select deptno,
max(ename) keep(dense_rank last order by sal desc),
max(sal) keep(dense_rank last order by sal desc),
max(ename) keep(dense_rank last order by sal desc)
from emp group by deptno;
---- lead 获取当前行下一行的数据, lag获取当前行上一行的数据
select ename,
sal,
lead(sal) over(order by sal),
lag(sal) over(order by sal)
from emp
order by sal;
----14、extract 函数返回值为数字,获取时间字段的某一个值
select extract(day from sysdate) from dual;
---- to_char(sysdate,'xxx') d day 1 ww iw ...
---- next_day 1234567 下一个 1 代表周天 2代表周一。。。>
select to_char(sysdate, 'day') from dual;
select next_day(sysdate, 1) from dual;
--月历
select max((case dd
when 2 then
d
end)) d1
from (select to_char(dt, 'iw') weak,
to_char(dt, 'dd') d,
to_number(to_char(dt, 'd')) dd
from (select (trunc(sysdate, 'mm') + level - 1) dt
from dual
connect by level <= 30))
group by weak
order by weak
--rows between 分析函数开窗 (按行)
--range between 按照范围开窗(针对数字和日期列)
select sum(sal) over(order by empno rows between unbounded preceding and 1 preceding)
from emp;
-----15 求余数函数
select mod(34, 4) from dual;
-----16 分页常用伪列 rownum
----- 16.1 先排序,在获取rownum取值
----- 16.2 获取rownum的值后才能按照分页过滤
-----17 SQL动态分割字符串
----- 知道分隔符,但每一个都可能包含多个分割符
---- 针对的是一行数据的结果,
---- level 树形结构查询结构
select regexp_substr(l, '[^,]+', 1, level)
from test6
where id = 1
connect by level <= regexp_count(l, ',');
----18、行转列 pivot 等价与 case when
----带有聚合函数的时候,不要使用俩次或俩次以上的pivot
select *
from (select job, ename, deptno from emp) pivot(count(ename) as c for deptno in(10 as d10,
20 as d20,
30 as d30));
select *
from (select deptno, ename, job from emp) pivot(count(ename) as c for job in('CLERK' as
job_clark,
'SALESMAN' as
job_SALESMAN,
'MANAGER' as
job_MANAGER,
'ANALYST' as
job_ANALYST,
'PRESIDENT' as
job_PRESIDENT));
----19、列转行 unpivot (同样的需求可以用 union all 处理),要保证转换的列有同样的
----数据类型
-----unpivot include unlls 包含空值
select
from (select
from (select job, ename, deptno from emp) pivot(count(ename) as c for deptno in(10 as d10,
20 as d20,
30 as d30))) unpivot(sal for deptno in(d10_c,
d20_c,
--包含null值 d30_c));
select * from emp unpivot INCLUDE NULLS(salZE for lie in(SAL, COMM));
----20、ceil(rn/5) 返回大于或等于表达式的最小整数
---- ceil 按照5个一组编号,然后在组内排序加序号
---- 然后用序号进行行转列
select *
from (select gp,
ename,
row_number() over(partition by gp order by ename) xh
from (select ceil(rn / 5) gp, ename
from (select rownum rn, ename
from (select ename from emp order by ename)))) pivot(max(ename) as x for xh in(1 as e1,
2 as e2,
----21 ntile(3) over 多数据进行分组,3为分组约定
select ntile(3) over(order by empno),empno,ename from emp where job in ('CLERK', 'MANAGER')
----22 rollup 求统计列的合计值
---- grouping(deptno) 该列被汇总的时候 返回值为1 ,否则返回0
---- 处理分组字段存在空的情况下,与合计行无法区分
select deptno,sum(sal) from emp group by rollup (deptno)
-- emp 按照 deptno, job, empno 分组,同时计算出 deptno, job, empno 的合计、deptno, job的合计
-- deptno 的合计
--grouping 用来区分合计列
select deptno, job, empno, sum(sal), grouping(deptno), grouping(job),grouping(empno)
from emp
group by rollup(deptno, job, empno);
--cube 按照 deptno, job, empno 各种可能组合计算合计,最后加一行总计
--grouping_id deptno,job,empno 三种可能组合合计的分类ID
select deptno, job, empno, sum(sal), grouping_id(deptno,job,empno)
from emp
group by cube(deptno, job, empno);
select deptno,
job,
sum(sal),
grouping_id(deptno, job),
case grouping_id(deptno, job)
when 0 then
'按照部门和工作分组'
when 1 then
'按照部分分组'
when 2 then
'按照工作分组'
when 3 then
'总合计'
end fl
from emp
where emp.deptno is not null
and emp.job is not null
group by cube(deptno, job);
----23 lpad rpad 左右补齐位数
----第二个参数代表字符串
----第二个参数代表期望的长度,不足补齐,超过截取
----第三个参数代表如果字符串长度不够则用这个补齐
select rpad(1,2,',') from dual;
select lpad(1,2,',') from dual;
----24 九九乘法表
with x as(
select level lv from dual connect by level <=9)
, xx as(
select x1.lv lv_a,x2.lv lv_b, to_char(x1.lv) || ' * ' ||
to_char(x2.lv) || ' = ' || to_char(x1.lv * x2.lv) c from x x1,x x2 where x1.lv <= x2.lv)
select lv_b,listagg(c,' ') within group(order by lv_b) from xx group by lv_b; 3 as e3,
4 as e4,
-----25 递归查询
----(PRIOR ename) 获取上一级的信息,可以获取所有列的信息
---- PRIOR 指定按照哪一个字段进行递归
---- connect by PRIOR emp.empno = emp.mgr 找出与本级empno 相等的mgr数据,向下递归
---- connect by emp.empno = PRIOR emp.mgr 找出与本级mgr 相等的empno数据,向上递归
select empno, ename,mgr,(PRIOR ename)
from emp
start with empno = '7902'
connect by PRIOR emp.empno = emp.mgr;
--伪列
--level 层级编码
--connect_by_isleaf 叶子节点标识
select empno, ename,mgr,(PRIOR job),level,connect_by_isleaf
from emp
start with empno = '7902'
connect by PRIOR emp.empno = emp.mgr;
---sys_connect_by_path 可以将层级中的部分字段连接起来(按照层级连接)
--- 3、2、1 连接;2、1连接;1连接
select empno,
ename,
mgr,
(PRIOR job),
level,
connect_by_isleaf,
sys_connect_by_path(ename, ',')
from emp
start with empno = '7902'
connect by emp.empno = PRIOR emp.mgr;
--- order siblings by 树形分支,分别排序,不按照整体结构排序
---无法看清层级结构
select empno, ename,mgr,(PRIOR job),level,connect_by_isleaf
from emp
start with empno = '7566'
connect by PRIOR emp.empno = emp.mgr
order siblings by empno;
--- 树形查询中 where 字段过滤的是查询结果,
--- 所以如果需要树形查询部分数据,必须先过滤,然后作为子查询结构
--- 进行树形查询
select
from (select from emp where deptno = '20')
start with mgr is null
connect by prior empno = mgr;
--如果要过滤一个完整的分支
--需要在connect by prior 后加入过滤语句
--不能在where中加入
select *
from emp
start with mgr is null
connect by prior empno = mgr
and empno !='7566';
----26、取各个分组的 最大最小 第一行 最后一行
select job,
first_value(ename) over(partition by job order by sal desc),
max(ename) keep(dense_rank first order by sal desc) over(partition by job),
last_value(ename) over(partition by job order by sal desc),
max(ename) keep(dense_rank last order by sal desc) over(partition by job)
from emp;
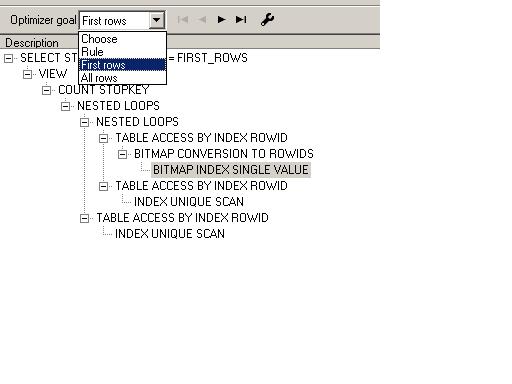
Oracle 在执行SQL语句时,有两种优化方法:即基于规则的RBO和基于代价的CBO。 在SQL执教的时候,到底采用何种优化方法,就由Oracle参数 optimizer_mode 来决定。
SQL> show parameter optimizer_mode
PL/SQL F5 根据不同的选择应用不同的优化方法
Oracle Sql 胡乱记的更多相关文章
- Oracle SQL 语言分类
Oracle SQL语句分类 2008-06-17 11:15:25 分类: Linux * 2008/06/17 星期二*蒙昭良*环境:WindowsXP + Oracle10gR2*Oracl ...
- oracle sql 高级编程 历史笔记整理
20130909 周一 oracle sql 开发指南 第7章 高级查询 1.层次化查询select level,ttt.*,sys_connect_by_path(ttt.col1,',') fro ...
- Oracle SQL Developer 连接 MySQL
1. 在ORACLE官网下载Oracle SQL Developer第三方数据库驱动 下载页面:http://www.oracle.com/technetwork/developer-tools/sq ...
- Oracle sql连接
inner-join left-outer-join right-outer-join full- ...
- 解决Oracle SQL Developer无法连接远程服务器的问题
在使用Oracle SQL Developer连接远程服务器的时候,出现如下的错误 在服务器本地是可以正常连接的.这个让人想起来,跟SQL Server的一些设计有些类似,服务器估计默认只在本地监听, ...
- Oracle sql语句执行顺序
sql语法的分析是从右到左 一.sql语句的执行步骤: 1)词法分析,词法分析阶段是编译过程的第一个阶段.这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构 ...
- Oracle SQL explain/execution Plan
From http://blog.csdn.net/wujiandao/article/details/6621073 1. Four ways to get execution plan(anyti ...
- 处理 Oracle SQL in 超过1000 的解决方案
处理oracle sql 语句in子句中(where id in (1, 2, ..., 1000, 1001)),如果子句中超过1000项就会报错.这主要是oracle考虑性能问题做的限制.如果要解 ...
- Oracle sql develpoer
Oracle SQL Developer是针对Oracle数据库的交互式开发环境(IDE) Oracle SQL Developer简化了Oracle数据库的开发和管理. SQL Develo ...
随机推荐
- 8天入门docker系列 —— 第三天 使用aspnetcore小案例熟悉对镜像的操控
上一篇我们聊到了容器,现在大家应该也知道了,没有镜像就没有容器,所以镜像对docker来说是非常重要的,关于镜像的特性和原理作为入门系列就不阐 述了,我还是通过aspnetcore的小sample去熟 ...
- 如何在MySQL中查询每个分组的前几名【转】
问题 在工作中常会遇到将数据分组排序的问题,如在考试成绩中,找出每个班级的前五名等. 在orcale等数据库中可以使用partition语句来解决,但在mysql中就比较麻烦了.这次翻译的文章就是专门 ...
- Flutter 异常处理之图片篇
背景 说到异常处理,你可能直接会认为不就是 try-catch 的事情,至于写一篇文章单独来说明吗? 如果你是这么想的,那么本篇说不定会给你惊喜哦~ 而且本篇聚焦在图片的异常处理. 场景 学以致用,有 ...
- SQL Server 数据库基于备份文件的【一键还原】
1. 备份与还原的基础说明 我们知道在DBA的日常工作中,SQL Server 数据库的恢复请求偶有发生,可能是用作数据的追踪,可也可能能是数据库的灾难恢复. 数据库常用的备份命令如下: ----完整 ...
- 【Teradata TTU】Windows TTU安装工具列表
Version Display Name-------------------------------------------------------------------------------- ...
- 常见hash算法
hash算法的意义在于提供了一种快速存取数据的方法,它用一种算法建立键值与真实值之间的对应关系,(每一个真实值只能有一个键值,但是一个键值可以对应多个真实值),这样可以快速在数组等条件中里面存取数据. ...
- PHP——isset和empty
前言 对于这两个PHP函数大家肯定都很熟悉,但是其二者的区别又有那些呢? 对比 isset | 检测变量是否被设置过 1. 变量不存在,返回FALSE 2. 变量存在且其值为NULL,返回FALSE ...
- spark 机器学习基础 数据类型
spark的机器学习库,包含常见的学习算法和工具如分类.回归.聚类.协同过滤.降维等使用算法时都需要指定相应的数据集,下面为大家介绍常用的spark ml 数据类型.1.本地向量(Local Vect ...
- 为什么从前那些.NET开发者都不写单元测试呢?
楔子 四年前我虽然也写了很多年代码,由于公司虽然规模不小,却并非一家规范化的软件公司,因此在项目中严格意义上来说并没有架构设计.也不写单元测试,后来有幸加入了一家公司,这家公司虽然也是一家小公司,但是 ...
- python接口自动化(十)--post请求四种传送正文方式(详解)
简介 post请求我在python接口自动化(八)--发送post请求的接口(详解)已经讲过一部分了,主要是发送一些较长的数据,还有就是数据比较安全等.我们要知道post请求四种传送正文方式首先需要先 ...