Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析
backward函数
官方定义:
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
Computes the sum of gradients of given tensors w.r.t. graph leaves.The graph is differentiated using the chain rule. If any of tensors are non-scalar (i.e. their data has more than one element) and require gradient, the function additionally requires specifying grad_tensors. It should be a sequence of matching length, that contains gradient of the differentiated function w.r.t. corresponding tensors (None is an acceptable value for all tensors that don’t need gradient tensors). This function accumulates gradients in the leaves - you might need to zero them before calling it.
翻译和解释:参数tensors如果是标量,函数backward计算参数tensors对于给定图叶子节点的梯度( graph leaves,即为设置requires_grad=True的变量)。
参数tensors如果不是标量,需要另外指定参数grad_tensors,参数grad_tensors必须和参数tensors的长度相同。在这一种情况下,backward实际上实现的是代价函数(loss = torch.sum(tensors*grad_tensors); 注:torch中向量*向量实际上是点积,因此tensors和grad_tensors的维度必须一致 )关于叶子节点的梯度计算,而不是参数tensors对于给定图叶子节点的梯度。如果指定参数grad_tensors=torch.ones((size(tensors))),显而易见,代价函数关于叶子节点的梯度,也就等于参数tensors对于给定图叶子节点的梯度。
每次backward之前,需要注意叶子梯度节点是否清零,如果没有清零,第二次backward会累计上一次的梯度。
下面给出具体的例子:
import torch
x=torch.randn((3),dtype=torch.float32,requires_grad=True)
y = torch.randn((3),dtype=torch.float32,requires_grad=True)
z = torch.randn((3),dtype=torch.float32,requires_grad=True)
t = x + y
loss = t.dot(z) #求向量的内积
在调用 backward 之前,可以先手动求一下导数,应该是:
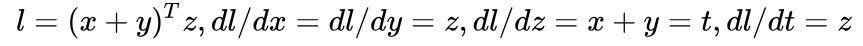
用代码实现求导:
loss.backward(retain_graph=True)
print(z,x.grad,y.grad) #预期打印出的结果都一样
print(t,z.grad) #预期打印出的结果都一样
print(t.grad) #在这个例子中,x,y,z就是叶子节点,而t不是,t的导数在backward的过程中求出来回传之后就会被释放,因而预期结果是None
结果和预期一致:
tensor([-2.6752, 0.2306, -0.8356], requires_grad=True) tensor([-2.6752, 0.2306, -0.8356]) tensor([-2.6752, 0.2306, -0.8356])
tensor([-1.1916, -0.0156, 0.8952], grad_fn=<AddBackward0>) tensor([-1.1916, -0.0156, 0.8952])
None
敲重点:注意到前面函数的解释中,在参数tensors不是标量的情况下,tensor.backward(grad_tensors)实现的是代价函数(torch.sum(tensors*grad_tensors))关于叶子节点的导数。在上面例子中,loss = t.dot(z),因此用t.backward(z),实现的就是loss对于所有叶子结点的求导,实际运算结果和预期吻合。
t.backward(z,retain_graph=True)
print(z,x.grad,y.grad)
print(t,z.grad)
运行结果如下:
tensor([-0.7830, 1.4468, 1.2440], requires_grad=True) tensor([-0.7830, 1.4468, 1.2440]) tensor([-0.7830, 1.4468, 1.2440])
tensor([-0.7145, -0.7598, 2.0756], grad_fn=<AddBackward0>) None
上面的结果中,出现了一个问题,虽然loss关于x和y的导数正确,但是z不再是叶子节点了。
问题1:当使用t.backward(z,retain_graph=True)的时候, print(z.grad)结果是None,这意味着z不再是叶子节点,这是为什么呢?
另外一个尝试,loss = t.dot(z)=z.dot(t),但是如果用z.backward(t)替换t.backward(z,retain_graph=True),结果却不同。
z.backward(t)
print(z,x.grad,y.grad)
print(t,z.grad)
运行结果:
tensor([-1.0716, -1.3643, -0.0016], requires_grad=True) None None
tensor([-0.7324, 0.9763, -0.4036], grad_fn=<AddBackward0>) tensor([-0.7324, 0.9763, -0.4036])
问题2:上面的结果中可以看到,使用z.backward(t),x和y都不再是叶子节点了,z仍然是叶子节点,且得到的loss相对于z的导数正确。
上述仿真出现的两个问题,我还不能解释,希望和大家交流,我的邮箱yangyuwen_yang@126.com,欢迎来信讨论。
问题1:当使用t.backward(z,retain_graph=True)的时候, print(z.grad)结果是None,这意味着z不再是叶子节点,这是为什么呢?
问题2:上面的结果中可以看到,使用z.backward(t),x和y都不再是叶子节点了,z仍然是叶子节点,且得到的loss相对于z的导数正确。
另外强调一下,每次backward之前,需要注意叶子梯度节点是否清零,如果没有清零,第二次backward会累计上一次的梯度。
简单的代码可以看出:
#测试1,:对比上两次单独执行backward,此处连续执行两次backward
t.backward(z,retain_graph=True)
print(z,x.grad,y.grad)
print(t,z.grad)
z.backward(t)
print(z,x.grad,y.grad)
print(t,z.grad)
# 结果x.grad,y.grad本应该是None,因为保留了第一次backward的结果而打印出上一次梯度的结果
tensor([-0.5590, -1.4094, -1.5367], requires_grad=True) tensor([-0.5590, -1.4094, -1.5367]) tensor([-0.5590, -1.4094, -1.5367])
tensor([-1.7914, 0.8761, -0.3462], grad_fn=<AddBackward0>) None
tensor([-0.5590, -1.4094, -1.5367], requires_grad=True) tensor([-0.5590, -1.4094, -1.5367]) tensor([-0.5590, -1.4094, -1.5367])
tensor([-1.7914, 0.8761, -0.3462], grad_fn=<AddBackward0>) tensor([-1.7914, 0.8761, -0.3462])
#测试2,:连续执行两次backward,并且清零,可以验证第二次backward没有计算x和y的梯度
t.backward(z,retain_graph=True)
print(z,x.grad,y.grad)
print(t,z.grad)
x.grad.data.zero_()
y.grad.data.zero_()
z.backward(t)
print(z,x.grad,y.grad)
print(t,z.grad)
tensor([ 0.8671, 0.6503, -1.6643], requires_grad=True) tensor([ 0.8671, 0.6503, -1.6643]) tensor([ 0.8671, 0.6503, -1.6643])
tensor([1.6231e+00, 1.3842e+00, 4.6492e-06], grad_fn=<AddBackward0>) None
tensor([ 0.8671, 0.6503, -1.6643], requires_grad=True) tensor([0., 0., 0.]) tensor([0., 0., 0.])
tensor([1.6231e+00, 1.3842e+00, 4.6492e-06], grad_fn=<AddBackward0>) tensor([1.6231e+00, 1.3842e+00, 4.6492e-06])
附参考学习的链接如下,并对作者表示感谢:
PyTorch 的 backward 为什么有一个 grad_variables 参数?该话题在我的知乎专栏里同时转载,欢迎更多讨论交流,参见链接。
Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析的更多相关文章
- PyTorch 中 torch.matmul() 函数的文档详解
官方文档 torch.matmul() 函数几乎可以用于所有矩阵/向量相乘的情况,其乘法规则视参与乘法的两个张量的维度而定. 关于 PyTorch 中的其他乘法函数可以看这篇博文,有助于下面各种乘法的 ...
- Pytorch中randn和rand函数的用法
Pytorch中randn和rand函数的用法 randn torch.randn(*sizes, out=None) → Tensor 返回一个包含了从标准正态分布中抽取的一组随机数的张量 size ...
- 模式识别 - libsvm该函数的调用方法 详细说明
libsvm该函数的调用方法 详细说明 本文地址: http://blog.csdn.net/caroline_wendy/article/details/26261173 须要载入(load)SVM ...
- Pytorch中torch.load()中出现AttributeError: Can't get attribute
原因:保存下来的模型和参数不能在没有类定义时直接使用. Pytorch使用Pickle来处理保存/加载模型,这个问题实际上是Pickle的问题,而不是Pytorch. 解决方法也非常简单,只需显式地导 ...
- 【学习笔记】pytorch中squeeze()和unsqueeze()函数介绍
squeeze用来减少维度, unsqueeze用来增加维度 具体可见下方博客. pytorch中squeeze和unsqueeze
- pytorch 中的Variable一般常用的使用方法
Variable一般的初始化方法,默认是不求梯度的 import torch from torch.autograd import Variable x_tensor = torch.randn(2, ...
- javascript中的闭包、函数的toString方法
闭包: 闭包可以理解为定义在一个函数内部的函数, 函数A内部定义了函数B, 函数B有访问函数A内部变量的权力: 闭包是函数和子函数之间的桥梁: 举个例子: let func = function() ...
- pytorch autograd backward函数中 retain_graph参数的作用,简单例子分析,以及create_graph参数的作用
retain_graph参数的作用 官方定义: retain_graph (bool, optional) – If False, the graph used to compute the grad ...
- pytorch中torch.narrow()函数
torch.narrow(input, dim, start, length) → Tensor Returns a new tensor that is a narrowed version of ...
随机推荐
- app后端设计(14)--LBS的偏移问题
刚开始做LBS的时候,有一个问题,通过手机获取的坐标,放到百度地图或高德地图上,总是会出现偏移,例如,当时是在微信的前总部"南方通讯大厦"附近获取的坐标,那是把坐标放到百度地图上却 ...
- nodejs中处理回调函数的异常
如果是使用nodejs+express3这个经典的组合,那么有一种很方面的处理回调函数异常的方法: 1. 安装模块:express-domain-middleware 2. 加入如下的代码: app. ...
- itchat库初探--微信好友全头像的拼接
代码: import itchat import math import PIL.Image as Image import os itchat.auto_login() friends = ...
- Spider与OpenPyXL的结合
OpenPyXL的API文档 1.OpenPyXL基础操作 引入Workbook这个类,然后调用 from openpyxl import Workbook wb = Workbook() 通过ope ...
- python selenium-webdriver 元素操作之键盘操作
selenium 提供了比较完整的键盘操作,在使用的模拟键盘操作之前需要我们导入from selenium.webdriver.common.keys import Keys即可,然后就可以来模拟键盘 ...
- Log4j2中的同步日志与异步日志
1.背景 Log4j 2中记录日志的方式有同步日志和异步日志两种方式,其中异步日志又可分为使用AsyncAppender和使用AsyncLogger两种方式. 2.Log4j2中的同步日志 所谓同步日 ...
- forwardport--源码笔记--注释
failed:", err.Error()) } }() } // log.Println("forwardPort ...
- java equals和tostring
Object类概述 是所有类中的父类,最大的超类,所有的类都继承他. equals方法 比较2个对象是否相同,其实他是在比较两个对象的地址是否相同,在equals方法中我们用==来判断 但是比较2个地 ...
- FTP连接池
我们项目使用的是 Apache的(commons-net-3.2.jar) FTPClient,但是系统偶尔会有异常,趁着刚解决完,总结一下. 日志中提示是类似 java.lang.Exception ...
- bzoj 2653 middle 二分答案 主席树判定
判断中位数是否可行需要将当前的解作为分界,大于其的置为1,小于为-1,然后b-c必选,ab,cd可不选,这个用线段树判定就好 但不能每次跑,所以套主席树,按权值排序,构建主席树,更新时将上一个节点改为 ...