HBase之八--(3):Hbase 布隆过滤器BloomFilter介绍
布隆过滤器( Bloom filters)
数据块索引提供了一个有效的方法,在访问一个特定的行时用来查找应该读取的HFile的数据块。但是它的效用是有限的。HFile数据块的默认大小是64KB,这个大小不能调整太多。
如果你要查找一个短行,只在整个数据块的起始行键上建立索引无法给你细粒度的索引信息。例如,如果你的行占用100字节存储空间,一个64KB的数据块包含(64 * 1024)/100 = 655.53 = ~700行,而你只能把起始行放在索引位上。你要查找的行可能落在特定数据块上的行区间里,但也不是肯定存放在那个数据块上。这有多种情况的可能,或者该行在表里不存在,或者存放在另一个HFile里,甚至在MemStore里。这些情况下,从硬盘读取数据块会带来IO开销,也会滥用数据块缓存。这会影响性能,尤其是当你面对一个巨大的数据集并且有很多并发读用户时。
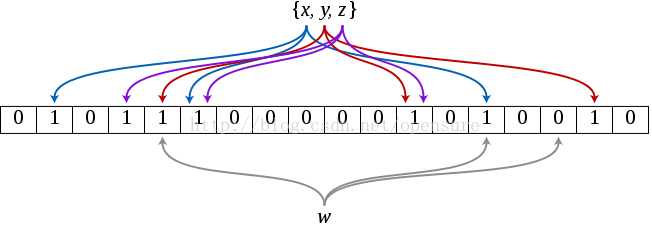
布隆过滤器允许你对存储在每个数据块的数据做一个反向测试。当某行被请求时,先检查布隆过滤器看看该行是否不在这个数据块。布隆过滤器要么确定回答该行不在,要么回答它不知道。这就是为什么我们称它是反向测试。布隆过滤器也可以应用到行里的单元上。当访问某列标识符时先使用同样的反向测试。
布隆过滤器也不是没有代价。存储这个额外的索引层次占用额外的空间。布隆过滤器随着它们的索引对象数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以帮助你榨干系统的性能潜力。
你可以在列族上打开布隆过滤器,如下所示:
hbase(main)> create 'mytable',{NAME=>'colfam1',BLOOMFILTER=>'ROWCOL'}
BLOOMFILTER参数的默认值是NONE。一个行级布隆过滤器用ROW打开,列标识符级布隆过滤器用ROWCOL打开。行级布隆过滤器在数据块里检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的开销高于ROW布隆过滤器。
- if (memOnly == false
- && ((StoreFileScanner) kvs).shouldSeek(scan, columns)) {
- scanners.add(kvs);
- }
- if (!scan.isGetScan()) {
- return true;
- }
- byte[] row = scan.getStartRow();
- switch (this.bloomFilterType) {
- case ROW:
- return passesBloomFilter(row, 0, row.length, null, 0, 0);
- case ROWCOL:
- if (columns != null && columns.size() == 1) {
- byte[] column = columns.first();
- return passesBloomFilter(row, 0, row.length, column, 0, column.length);
- }
- // For multi-column queries the Bloom filter is checked from the
- // seekExact operation.
- return true;
- default:
- return true;
- }
- // Seek all scanners to the start of the Row (or if the exact matching row
- // key does not exist, then to the start of the next matching Row).
- if (matcher.isExactColumnQuery()) {
- for (KeyValueScanner scanner : scanners)
- scanner.seekExactly(matcher.getStartKey(), false);
- } else {
- for (KeyValueScanner scanner : scanners)
- scanner.seek(matcher.getStartKey());
- }
- public boolean seekExactly(KeyValue kv, boolean forward)
- throws IOException {
- if (reader.getBloomFilterType() != StoreFile.BloomType.ROWCOL ||
- kv.getRowLength() == 0 || kv.getQualifierLength() == 0) {
- return forward ? reseek(kv) : seek(kv);
- }
- boolean isInBloom = reader.passesBloomFilter(kv.getBuffer(),
- kv.getRowOffset(), kv.getRowLength(), kv.getBuffer(),
- kv.getQualifierOffset(), kv.getQualifierLength());
- if (isInBloom) {
- // This row/column might be in this store file. Do a normal seek.
- return forward ? reseek(kv) : seek(kv);
- }
- // Create a fake key/value, so that this scanner only bubbles up to the top
- // of the KeyValueHeap in StoreScanner after we scanned this row/column in
- // all other store files. The query matcher will then just skip this fake
- // key/value and the store scanner will progress to the next column.
- cur = kv.createLastOnRowCol();
- return true;
- }
HBase之八--(3):Hbase 布隆过滤器BloomFilter介绍的更多相关文章
- Hbase 布隆过滤器BloomFilter介绍
转载自:http://blog.csdn.net/opensure/article/details/46453681 1.主要功能 提高随机读的性能 2.存储开销 bloom filter的数据存在S ...
- Spark布隆过滤器(bloomFilter)
数据过滤在很多场景都会应用到,特别是在大数据环境下.在数据量很大的场景实现过滤或者全局去重,需要存储的数据量和计算代价是非常庞大的.很多小伙伴第一念头肯定会想到布隆过滤器,有一定的精度损失,但是存储性 ...
- 布隆过滤器(BloomFilter)持久化
摘要 Bloomfilter运行在一台机器的内存上,不方便持久化(机器down掉就什么都没啦),也不方便分布式程序的统一去重.我们可以将数据进行持久化,这样就克服了down机的问题,常见的持久化方法包 ...
- 白话布隆过滤器BloomFilter
通过本文将了解到以下内容: 查找问题的一般思路 布隆过滤器的基本原理 布隆过滤器的典型应用 布隆过滤器的工程实现 场景说明: 本文阐述的场景均为普通单机服务器.并非分布式大数据平台,因为在大数据平台下 ...
- 【浅析】|白话布隆过滤器BloomFilter
通过本文将了解到以下内容: 查找问题的一般思路 布隆过滤器的基本原理 布隆过滤器的典型应用 布隆过滤器的工程实现 场景说明: 本文阐述的场景均为普通单机服务器.并非分布式大数据平台,因为在大数据平台下 ...
- 海量数据处理之布隆过滤器BloomFilter算法
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合.使用场景:数据量为100亿 ...
- 一道腾讯面试题:如何快速判断某 URL 是否在 20 亿的网址 URL 集合中?布隆过滤器
何为布隆过滤器 还是以上面的例子为例: 判断逻辑: 多次哈希: Guava的BloomFilter 创建BloomFilter 最终还是调用: 使用: 算法特点 使用场景 假设遇到这样一个问题:一个网 ...
- python实现布隆过滤器及原理解析
python实现布隆过滤器及原理解析 布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地 ...
- Redis实现布隆过滤器解析
布隆过滤器原理介绍 [1]概念说明 1)布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合 ...
随机推荐
- 2017-2018-2 20165202 实验四《Android程序设计》实验报告
一.实验报告封面 二.实验内容 1.基于Android Studio开发简单的Android应用并部署测试; 2.了解Android.组件.布局管理器的使用: 3.掌握Android中事件处理机制. ...
- etl工具-Bireme
前段时间做数据仓库项目,自己实现了一部分etl功能,后面一直没有时间去深入挖掘.这个工具貌似不错,写个帖子做下记录: https://hashdatainc.github.io/bireme/READ ...
- Java基础拾遗(二)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76358523冷血之心的博客) 马上就要秋招了,新的一轮笔试面试马上 ...
- 有关项目依赖包发生 Manifest Merge 冲突的详细解决方案
安卓开发使用 Gradle 插件管理依赖包确实非常方便,尤其是在解决一些依赖冲突的问题上.比如,重复依赖的问题,具体内容请我之前写的一篇文章: 有关 Android Studio 重复引入包的问题和解 ...
- 学习三部曲:WHAT、HOW、WHY
一个人学习的过程要经历以下三步,才可以说得上"学会"两字: 第一步:WHAT 所谓的"WHAT",就是搞清楚某个东东是什么?有什么用?有什么语法?有什么功能特性 ...
- OkHttp之ConnectInterceptor简单分析
在< Okhttp之CacheInterceptor简单分析 >这篇博客中简单的分析了下缓存拦截器的工作原理,通过此博客我们知道在执行完CacheInterceptor之后会执行下一个浏览 ...
- python kd树 搜索 代码
kd树就是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,可以运用在k近邻法中,实现快速k近邻搜索.构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,依次选择坐标轴对空间 ...
- 【剑指offer】不用加减乘除做加法,C++实现
原创博文,转载请注明出处! # 题目 # 思路 第一步:不考虑进位对每一位相加(异或操作) 第二步:考虑进位(位与运算+左移) 第三步:第一步和第二步相加(重复执行前两步) # 代码 #include ...
- MySQL存储引擎(engine:处理表的处理器)
1.基本的操作命令: 1.查看所有存储引擎 show engines: 2.查看已有表的存储引擎: show create table 表名: 3.创建表指定的存储引擎 create table 表名 ...
- SpringMvc和servlet简单对比介绍
原文链接:http://www.cnblogs.com/haolnu/p/7294533.html 一.servlet实现登录. 咱们先来看一下servlet实现注册登录. <servlet&g ...