点滴积累【C#】---抓取页面中想要的数据
效果: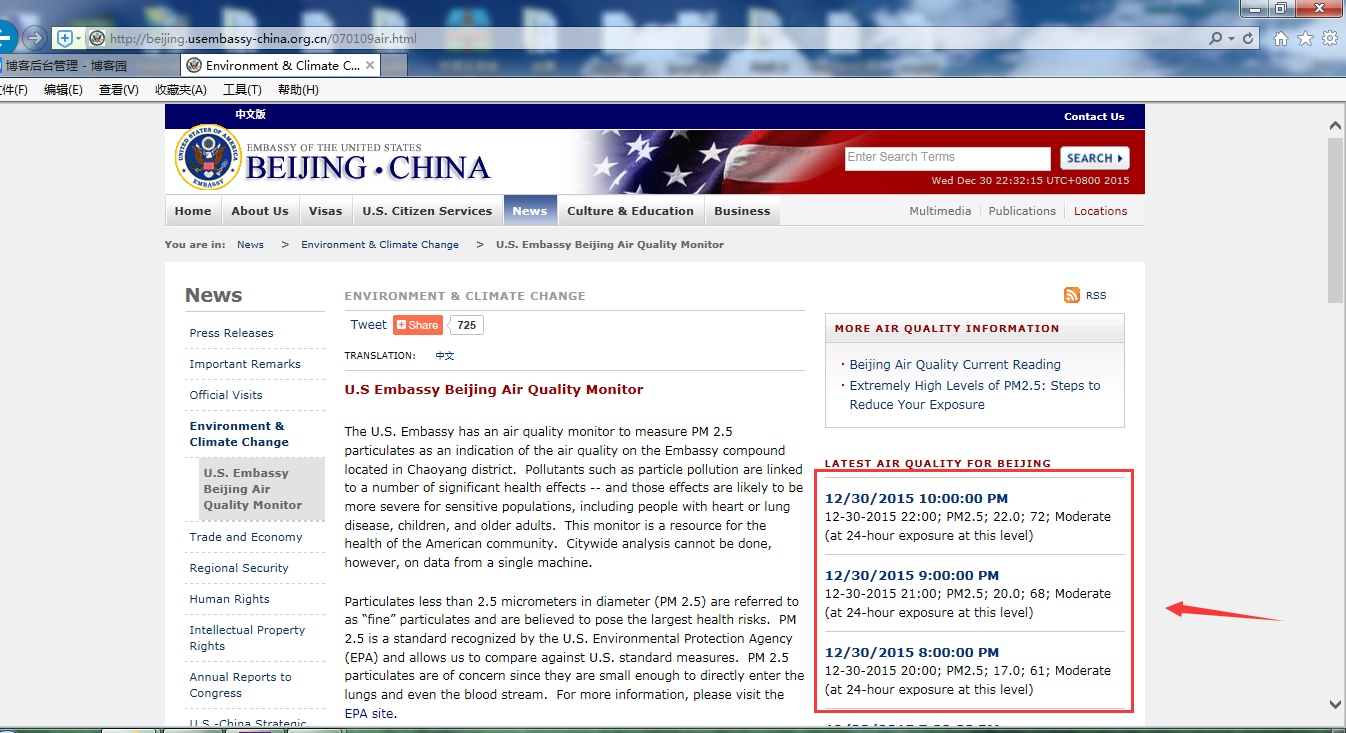
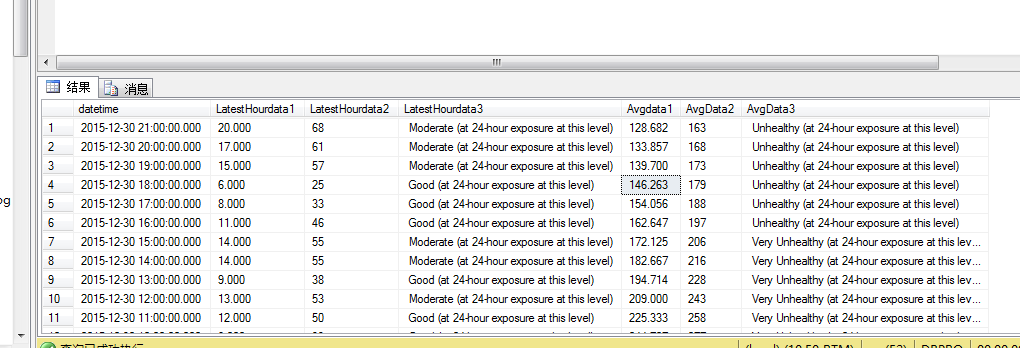
描述:此功能是抓取外国的一个检测PM2.5的网站。实时读取网站的数据,然后保存到数据库里面。每隔一小时刷新一次。
地址为:http://beijing.usembassy-china.org.cn/070109air.html
筛选后的地址为:http://utils.usembassy.gov/feed2js/feed2js.php?src=http%3A%2F%2Fwww.stateair.net%2Fweb%2Frss%2F1%2F1.xml&desc=1&num=7&targ=y&utf=y&pc=y&words=40&
思路:先抓取到页面的所有数据,保存到txt里面,再一行一行的读取txt,然后用split,substring截取到自己想要的数据,最后保存到数据库,在进行插入数据库的时候查看一下是否已经存在,如果不存在则插入。
代码:
using System;
using System.Collections.Generic;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
using System.IO;
//using System.Linq;
using System.Net;
using System.Text;
using System.Text.RegularExpressions;
//using System.Threading.Tasks; /********************************
* 创建人:青苹果
* 创建时间:2015-12-28
* 描述:获取美利坚合众国的 PM2.5
* ******************************/ namespace GetUSAData
{
class Program
{
//public static string GetURL = System.Configuration.ConfigurationSettings.AppSettings["GetURL"];//获取数据的地址
public static string GetURL = "http://utils.usembassy.gov/feed2js/feed2js.php?src=http%3A%2F%2Fwww.stateair.net%2Fweb%2Frss%2F1%2F1.xml&desc=1&num=7&targ=y&utf=y&pc=y&words=40&";
public static string txtURL = System.Configuration.ConfigurationSettings.AppSettings["txtURL"];//保存为txt文件的路径
public static string conn = ConfigurationManager.ConnectionStrings["ConnectionString"].ToString(); static void Main(string[] args)
{ LoadGO();
} public static void LoadGO()
{
GetUSA();
List<string[]> getlist = Read(txtURL);
//删除txt
if (File.Exists(txtURL))
{
//如果存在则删除
File.Delete(txtURL);
}
if (getlist.Count > )
{
for (int i = getlist.Count-; i >-; i--)
{
DateTime dtime = DateTime.Parse(getlist[i][].ToString());
string getTime = dtime.ToString("yyyy-MM-dd HH:mm");
string controlTime = dtime.ToString("yyyy-MM-dd");
float LatestHourdata1 = float.Parse(getlist[i][]);
int LatestHourdata2 = Convert.ToInt32(getlist[i][]);
float Avgdata1 = ;
int Avgdata2 = ;
string Avgdata3 = getlist[i][].ToString(); List<SqlParameter> listWhere = new List<SqlParameter>();
listWhere.Add(new SqlParameter("@strDatetime", controlTime));
string sqlSelect = @"SELECT count(*) as allcount,sum(LatestHourdata1) as LatestHourdata1_avg, sum(LatestHourdata2) as LatestHourdata2_avg
FROM T_twitter where ([LatestHourdata1] is not null
or [LatestHourdata2] is not null or [Avgdata1] is not null
or [AvgData2] is not null) and CONVERT(varchar(100), [datetime], 23)=@strDatetime"; DataTable sumDT = ControlDB(sqlSelect, listWhere, "select"); //查询总和用于计算日均值
if (sumDT.Rows.Count > )
{
foreach (DataRow itemDR in sumDT.Rows)
{
int allcount = Convert.ToInt32(itemDR["allcount"].ToString()); //数据库中当前日期数量总和
if (allcount > )
{
if (itemDR["LatestHourdata1_avg"] != null)
{
Avgdata1 = float.Parse(itemDR["LatestHourdata1_avg"].ToString()); //数据库中LatestHourdata1_avg总和
Avgdata1 = (Avgdata1 + LatestHourdata1) / (allcount + );//(数据库的总和+最新的一条)/(数据库的总和数量+1)=日平均值
}
if (itemDR["LatestHourdata2_avg"] != null)
{
Avgdata2 = Convert.ToInt32(itemDR["LatestHourdata2_avg"].ToString()); //数据库中LatestHourdata2_avg总和
Avgdata2 = (Avgdata2 + LatestHourdata2) / (allcount + );//(数据库的总和+最新的一条)/(数据库的总和数量+1)=日平均值
}
//根据网站规则判断PM2.5的平均严重性 if (Avgdata2 >= && Avgdata2 <= )
{
Avgdata3 = " Good (at 24-hour exposure at this level)";
}
else if (Avgdata2 >= && Avgdata2 <= )
{
Avgdata3 = " Moderate (at 24-hour exposure at this level)";
}
else if (Avgdata2 >= && Avgdata2 <= )
{
Avgdata3 = " Unhealthy for Sensitive Groups (at 24-hour exposure at this level)";
}
else if (Avgdata2 >= && Avgdata2 <= )
{
Avgdata3 = " Unhealthy (at 24-hour exposure at this level)";
}
else if (Avgdata2 >= && Avgdata2 <= )
{
Avgdata3 = " Very Unhealthy (at 24-hour exposure at this level)";
}
else
{
Avgdata3 = " Hazardous (at 24-hour exposure at this level)";
}
}
else
{
Avgdata1 = LatestHourdata1;
Avgdata2 = LatestHourdata2;
}
}
} List<SqlParameter> pars = new List<SqlParameter>();
pars.Add(new SqlParameter("@whereDatetime", getTime));
pars.Add(new SqlParameter("@datetime", getTime));
pars.Add(new SqlParameter("@LatestHourdata1", LatestHourdata1));
pars.Add(new SqlParameter("@LatestHourdata2", LatestHourdata2));
pars.Add(new SqlParameter("@LatestHourdata3", getlist[i][].ToString()));
pars.Add(new SqlParameter("@Avgdata1", Avgdata1));
pars.Add(new SqlParameter("@Avgdata2", Avgdata2));
pars.Add(new SqlParameter("@Avgdata3", Avgdata3)); string sql = @"if not exists(select * from dbo.T_twitter where datetime=@whereDatetime) begin
insert T_twitter (datetime,LatestHourdata1,LatestHourdata2,LatestHourdata3,Avgdata1,AvgData2,AvgData3)
VALUES(@datetime,@LatestHourdata1,@LatestHourdata2,@LatestHourdata3,@Avgdata1,@Avgdata2,@Avgdata3) end";
ControlDB(sql, pars, "");//插入数据
}
}
} /// <summary>
/// 获取页面数据保存至txt
/// </summary>
public static void GetUSA()
{
WebRequest request = WebRequest.Create(GetURL);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
//reader.ReadToEnd() 表示取得网页的源码 FileStream fs = new FileStream(txtURL, FileMode.Create);
byte[] data = System.Text.Encoding.Default.GetBytes(reader.ReadToEnd());
//开始写入
fs.Write(data, , data.Length);
//清空缓冲区、关闭流
fs.Flush();
fs.Close();
} /// <summary>
/// 根据路径读取txt文件
/// </summary>
/// <param name="path">txt路径</param>
/// <returns></returns>
public static List<string[]> Read(string path)
{
List<string[]> list = new List<string[]>();
StreamReader sr = new StreamReader(path, Encoding.Default);
String line;
while ((line = sr.ReadLine()) != null)
{
int i = line.ToString().IndexOf("title");
if (i > )
{
string titleStr = line.ToString().Substring(i + ); //截取到title后面的值
string[] titlelist = titleStr.Split('"'); //以" 截取
string titledata = titlelist[];
string[] datalist = titledata.Split('&'); //以& 截取
string data = datalist[];
string[] datastrlist = data.Split(new char[] { ';' }, StringSplitOptions.RemoveEmptyEntries);//以; 截取
list.Add(datastrlist);
}
}
sr.Close();
return list;
} /// <summary>
/// 增查表
/// </summary>
/// <returns></returns>
public static DataTable ControlDB(string sql, List<SqlParameter> par, string type)
{
DataAccess controData = new DataAccess();
DataTable resultDT = new DataTable();
if (type == "select")
{
resultDT = controData.GetDataTable(sql, par.ToArray());
}
else
{
int result = controData.ExecuteSql(sql, par.ToArray());
}
return resultDT;
}
}
}
Demo下载:
http://files.cnblogs.com/files/xinchun/GetUSAData.zip
点滴积累【C#】---抓取页面中想要的数据的更多相关文章
- 使用PHP的正则抓取页面中的网址
最近有一个任务,从页面中抓取页面中所有的链接,当然使用PHP正则表达式是最方便的办法.要写出正则表达式,就要先总结出模式,那么页面中的链接会有几种形式呢? 链接也就是超级链接,是从一个元素(文字. ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
- 通过CURL抓取页面中的图片路径并下载到本地
1.首页是图片处理页面downpic.php <?phpfunction getImage($url,$filename="") { if($url=="" ...
- java使用htmlunit工具抓取js中加载的数据
htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容.项目可以模拟浏览器运行,被誉为java浏览器的开源实现.这个没有界面的浏览器,运行速度 ...
- Fiddler中如何抓取app中https(443端口)数据
Fiddler不但能截获各种浏览器发出的HTTP请求, 也可以截获手机发出的HTTP/HTTPS请求,总结下Fiddler截获IPhone和Android发出的HTTP/HTTPS包,前提条件是:安装 ...
- PHP抓取页面中的邮箱
<?php $url='http://www.cnblogs.com/tinyphp/p/3234926.html'; //当页已留邮箱 $content=file_get_contents($ ...
- 浅谈如何使用python抓取网页中的动态数据
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的.所以也就引出了什么是动态数据的概念, 动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到 ...
- 用正则表达式抓取网页中的ul 和 li标签中最终的值!
获取你要抓取的页面 const string URL = "http://www.hn3ddf.gov.cn/price/GetList.html?pageno=1& ...
- Heritrix源码分析(九) Heritrix的二次抓取以及如何让Heritrix抓取你不想抓取的URL
本博客属原创文章,欢迎转载!转载请务必注明出处:http://guoyunsky.iteye.com/blog/644396 本博客已迁移到本人独立博客: http://www.yun5u ...
随机推荐
- Ruby:Sublime中开发Ruby需要注意的Encoding事项
背景 最近在用Sublime作为开发环境学习Ruby,本文就记录一下Ruby和Sublime在编码方面的问题. Sublime相关 默认的文件存储编码:UTF8 Sublime文件默认存储编码为UTF ...
- OAuth:OAuth概述
OAuth addresses these issues by introducing an authorization layer and separating the role of the cl ...
- (Inside Out) Web地图坐标系——TDT的奇妙
一个GIS科班出生的研究生.把已还到课本的基础GIS知识,准备又一次学习,并结合这几年下来自身在行业中GIS的应用.总结一些有用的GIS知识点.一备不时之需,二为积累沉淀,三则是年龄越大.记性越差,加 ...
- C#视频播放器【转】
1对于视频播放器来说,最重要的功能,莫过于播放视频文件了这就要用到VS自带的控件——Windows Media Player windows media player 将Windows Media P ...
- Converting a fisheye image into a panoramic, spherical or perspective projection [转]
Converting a fisheye image into a panoramic, spherical or perspective projection Written by Paul Bou ...
- 自定义控件 淘宝头条【ViewFlipper】
简易版 代码 ); tv.setOnClickListener(new OnClickListener() { @Override public void onClick(View v) { Acti ...
- 关于Javascript你可能不知道的事
NaN表示一个不能产生正常结果的运算结果.它不等于任何值,包括它自己.可以用isNaN(number)来检测. 同Java中的字符串一样,JS中的字符串是不可变的.也就是说一旦字符串被创建,就无法改变 ...
- OpenGL入门学习(转载)
说起编程作图,大概还有很多人想起TC的#include <graphics.h>吧? 但是各位是否想过,那些画面绚丽的PC游戏是如何编写出来的?就靠TC那可怜的640*480分辨率.16色 ...
- Qt 之 QtConcurrent
本文以 Qt 中的 QtConcurrent::run() 函数为例,介绍如何将函数运行在单独的某一个线程中. 1 QtConcurrent::run() QtConcurrent 是一个命名空间, ...
- 使用System.getProperty方法,如何配置JVM系统属性 (转载)
很多时候需要在项目中读取外部属性文件,用到了System.getProperty("")方法.这个方法需要配置JVM系统属性,那么如何配置呢? 那就是使用java -D 配置系统属 ...