Apache Spark简单介绍、安装及使用
Apache Spark安装及配置(OS X下的Ubuntu虚拟机)
安装 Anaconda
bash Anaconda2-4.1.1-Linux-x86_64.sh
$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
设置JAVA_HOME
gedit .bashrc
JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JAVA_HOME
PATH=$PATH:$JAVA_HOME
export PATH
$ tar -zxvf spark-2.0.0-bin-hadoop2.7.tgz
$ rm spark-2.0.0-bin-hadoop2.7.tgz
gedit .bashrc
export PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_DRIVER_PYTHON_OPTS=notebook
cd ~/spark-2.0.0-bin-hadoop2.7
./bin/pyspark
Apache Spark简单使用
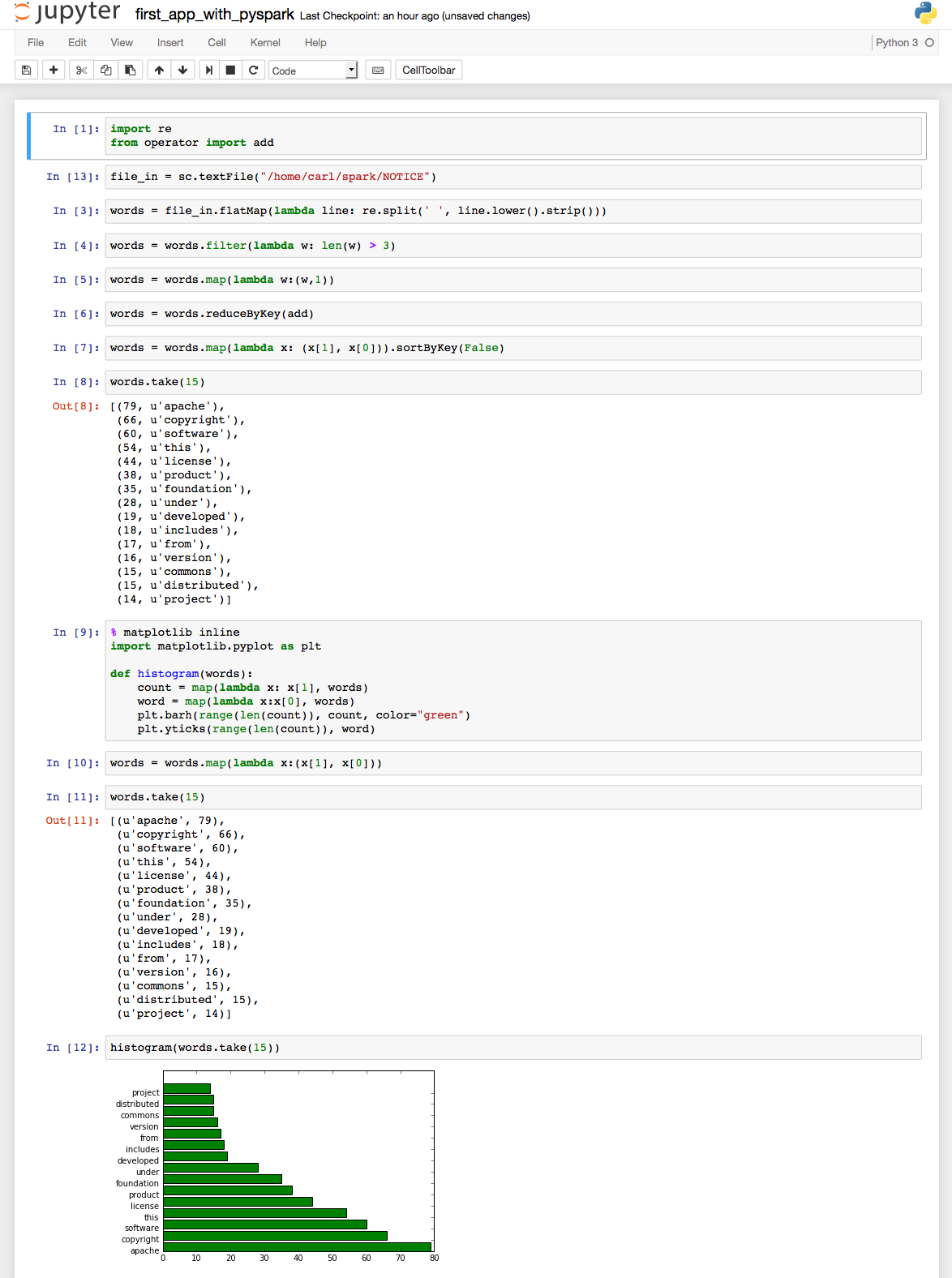
# coding: utf-8 # In[1]: import re
from operator import add # In[13]: file_in = sc.textFile("/home/carl/spark/NOTICE") # In[3]: words = file_in.flatMap(lambda line: re.split(' ', line.lower().strip())) # In[4]: words = words.filter(lambda w: len(w) > 3) # In[5]: words = words.map(lambda w:(w,1)) # In[6]: words = words.reduceByKey(add) # In[7]: words = words.map(lambda x: (x[1], x[0])).sortByKey(False) # In[8]: words.take(15) # In[9]: get_ipython().magic(u'matplotlib inline')
import matplotlib.pyplot as plt def histogram(words):
count = map(lambda x: x[1], words)
word = map(lambda x:x[0], words)
plt.barh(range(len(count)), count, color="green")
plt.yticks(range(len(count)), word) # In[10]: words = words.map(lambda x:(x[1], x[0])) # In[11]: words.take(15) # In[12]: histogram(words.take(15))
如果你对网络爬虫感兴趣,请查看另一篇随笔: 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
Apache Spark简单介绍、安装及使用的更多相关文章
- Spark简单介绍,Windows下安装Scala+Hadoop+Spark运行环境,集成到IDEA中
一.前言 近几年大数据是异常的火爆,今天小编以java开发的身份来会会大数据,提高一下自己的层面! 大数据技术也是有很多: Hadoop Spark Flink 小编也只知道这些了,由于Hadoop, ...
- Mongodb简单介绍安装
具体详细内容,请查阅 Mongodb官方文档 一.简单介绍 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. M ...
- Apache Flume的介绍安装及简单案例
概述 Flume 是 一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件.Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink).为了保证 ...
- 在linux上安装elasticsearch简称ES 简单介绍安装步骤
1.简介 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 ...
- Spark(二) -- Spark简单介绍
spark是什么? spark开源的类Hadoop MapReduce的通用的并行计算框架 spark基于map reduce算法实现的分布式计算 拥有Hadoop MapReduce所具有的优点 但 ...
- Apache Shiro简单介绍
1. 概念 Apache Shiro 是一个开源安全框架,提供身份验证.授权.密码学和会话管理.Shiro 框架具有直观.易用等特性,同时也能提供健壮的安全性,虽然它的功能不如 SpringSecur ...
- web服务的简单介绍及apache服务的安装
一,web服务的作用: 是指驻留于因特网上某种类型计算机的程序,可以向浏览器等Web客户端提供文档.可以放置网站文件,让全世界浏览: 可以放置数据让全世界下载.目前最主流的三个Web服务器是Ap ...
- 3.如何安装Apache Spark
如何安装Apache Spark 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹 ...
- 分享一个.NET平台开源免费跨平台的大数据分析框架.NET for Apache Spark
今天早上六点半左右微信群里就看到张队发的关于.NET Spark大数据的链接https://devblogs.microsoft.com/dotnet/introducing-net-for-apac ...
随机推荐
- C# i=0;i=i++,i的值是多少?
昨天看群里dalao们聊天,有一个人出来问这个问题 这个题应该是挺常见的 int i = 0, t; for(t = 0;t <= 5;t++) { ...
- [版本控制之道] Git 常用的命令总结(欢迎收藏备用)
坚持每天学习,坚持每天复习,技术永远学不完,自己永远要前进 总结日常开发生产中常用的Git版本控制命令 ------------------------------main-------------- ...
- Angular企业级开发(2)-搭建Angular开发环境
1.集成开发环境 个人或团队开发AngularJS项目时,有很多JavaScript编辑器可以选择.使用优秀的集成开发环境(Integrated Development Environment)能节省 ...
- fir.im Weekly - 关于 iOS10 适配、开发、推送的一切
"小程序"来了,微信变成名副其实的 Web OS,新一轮的Web App 与Native App争论四起.程序员对新技术永远保持灵敏的嗅觉和旺盛的好奇心,@李锦发整理了微信小程序资 ...
- VS2015在创建项目时的一些注意事项
一.下面是在创建一个新的项目是我最常用的,现在对他们一一做一个详细的介绍: 1.Win32控制台应用程序我平时编写小的C/C++程序都用它,它应该是用的最多的. 2.名称和解决方案名称的区别:名称是项 ...
- 使用Expression实现数据的任意字段过滤(1)
在项目常常要和数据表格打交道. 现在BS的通常做法都是前端用一个js的Grid控件, 然后通过ajax的方式从后台加载数据, 然后将数据和Grid绑定. 数据往往不是一页可以显示完的, 所以要加分页: ...
- scala练习题1 基础知识
1, 在scala REPL中输入3. 然后按下tab键,有哪些方法可以被调用? 24个方法可以被调用, 8个基本类型: 基本的操作符, 等: 2,在scala REPL中,计算3的平方根,然 ...
- HttpPost过程中使用的URLEncoder.encode(something, encode)
URLEncoder.encode("刘美美", "utf-8").toString() = %E5%88%98%E7%BE%8E%E7%B ...
- swift 中关于open ,public ,fileprivate,private ,internal,修饰的说明
关于 swift 中的open ,public ,fileprivate,private, internal的区别 以下按照修饰关键字的访问约束范围 从约束的限定范围大到小的排序进行说明 open,p ...
- Xamarin.Android之使用百度地图起始篇
一.前言 如今跨平台开发层出不穷,而对于.NET而言时下最流行的当然还是Xamarin,不仅仅能够让我们在熟悉的Vs下利用C#开发,在对原生态类库的支持方面也有着非常的好支持,今天我们将会以百度地图类 ...