关于Hadoop结合RDBMS应用的一些思考
最近一段时间一直在从事和hadoop相关的工作,主要是技术内容学习、安装配置优化以及一些框架结构的设计。在此期间,我对于RDBMS和Hadoop的结合应用有了一些自己的看法,写出来大家共同探讨一下。
1、为什么要用Hadoop
这个在网上已近有很多的人说过这个问题,我在这里就不多述了。但是我想说下,对于一个工具而言,只有最合适的应用场景没有最牛的工具。hadoop对我而言也只是一个工具,所以,更多的时候我是从业务角度出发去考虑hadoop能给我带来什么。
2、RDBMS?
RDBMS是关系型数据库英文缩写,但对于我而言,就是oracle(因为我现在的公司用就是)。关于RDBMS和NOSQL谁更好这个话题争论的太多了,我也看了不少。但是我个人的感觉是,当前的RDBMS做的工作想用Hadoop来替代,基本是不可能,二者只能是互补互助,才能和谐共进(构建和谐社会,哈哈)。
3、数据仓库和数据库
就我个人的理解,数据仓库更倾向于数据的挖掘和分析,对实时性要求较低。而数据库则是对实时性响应较高,做为数据挖掘而言,虽然就目前当前看来是可以胜任,但是一旦数据量庞大(TB级别数据甚至PB级别),直接结果将是数据检索速度急剧下降,一些oracle执行的的挖掘job都有可能跑不出结果。所以,这也是为什么我在思考如何将hadoop和RDBMS结合应用的原因。废话不多说了,自己画了个草图大家先看看:
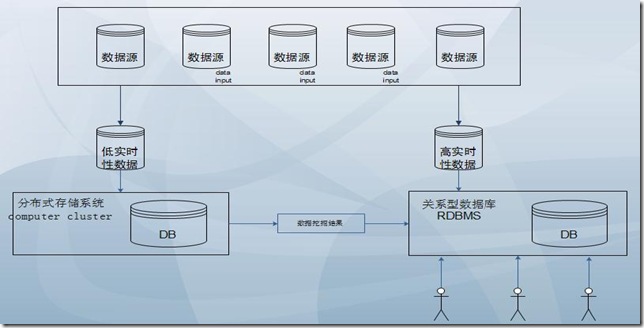
4、总体思想
由于工作环境和工作内容的特殊性,我这里并不涉及到大并发访问,所以,只要满足实时性的查询和数据挖掘即可。基于上图,我的总体思想如下:
a、将数据源在输入的时候就对数据进行拆分,一些侧重于数据分析和对实施响应要求较低的数据文件划分为“低实时性数据”。将一些相应速度要求较高的数据文件划分为“高实时性数据”。当然,这样划分可能数据之间可能会有交集,也就是说存在数据重复存放的可能性,所以,划分的具体原则需要结合业务详细制定。
b、“低实时性数据”存入HDFS文件系统,采用M/R或是Hive来进行一些挖掘的工作。而“高实时性数据”则存放在传统的RDBMS中,用以响应用户的实时查询需求。
c、Hadoop挖掘的数据结果可以协商好的格式存放到RDBMS中,提供为数据分析的基础。实际上,可以理解是Hadoop对数据内容进行的预处理,RDBMS则是在该结果的基础上进行高级功能(分析、比对、数据碰撞等)内容展示和二次分析。
d、用户也可直接的发送指令给Hadoop,进行一些特殊的数据挖掘工作,结果不需要存放到RDBMS中,直接反馈到用户web界面。(图上没表现出来)
5、总结
a、当前这样的应用模型可能会带来一些冗余数据,但是至少缓解了一些当前RDBMS的压力。
b、我最早也想过完全替换RDBMS,对于实时的查询我想采用hbase,但是在一段时间之后我发现hbase对一些查询支持的并不好。这里专门提出来也是希望大家能够给我解疑答惑,对于hbase如何应用是合适的?或者说在这个模型中是否还有hbase的位置?
b、上面说的内容都是基于我当前的工作环境来论述,大家如果觉得有疑问可以给我留言或发邮件(dajuezhao@gmail.com)。

按默认排序 显示最新评论 共有4个评论 (最后回答: 2年前)
-
我有个疑问:当我们的数据要求实时性很高,而且数据量比较大的情况,那应该采取怎样的方案处理呢?
目前我个人采用的内存方式实现的,但是随着数据量的不断增加,内存可能还是不行。

-
我说第一眼看这个帖子这么面熟,仔细一看,原来是别人转载到这里了。
高实时的海量数据查询确实是个问题,我目前也面临这个问题,对于这个问题我有以下考虑:
1、根据业务需求对高实时响应查询的数据进行分类的存储,尽最大可能减少查询的范围。
2、是否可以对数据做预处理,在海量数据中提炼出来实际可要的数据,做数据准备。
3、采用HBase来解决查询的问题。(入库速率和稳定性是个挑战)
总的说来,1和2都是通过对数据范围的缩减来提升查询速度。3则是利用HBase来解决问题。

-
额 方法多的很,搜索嘛直接用其他分布式搜索引擎

-
b、我最早也想过完全替换RDBMS,对于实时的查询我想采用hbase,但是在一段时间之后我发现hbase对一些查询支持的并不好。这里专门提出来也是希望大家能够给我解疑答惑,对于hbase如何应用是合适的?或者说在这个模型中是否还有hbase的位置?
hbase是kv类型的查询,同时不支持跨行事物,存取其他的字段由应用程序来控制,其实对于互联网处于对索引使用方面考虑,其实很多sql都是kv类型。所以应该不是大问题。hbase的hql是非常简单和弱模式的模型。hbase完全替换关系型数据库需要时间,通过修改应用程序现在就可以实用hbase

关于Hadoop结合RDBMS应用的一些思考的更多相关文章
- 后Hadoop时代的大数据技术思考:数据即服务
1. Hadoop 的神话正在破灭 IBM leads BigInsights for Hadoop out behind barn. Shots heard IBM has announced th ...
- Sqoop迁移Hadoop与RDBMS间的数据
Sqoop是用来实现结构型数据(如:关系型数据库RDBMS)和Hadoop之间进行数据迁移的工具.它充分利用了MapReduce的并行特点以批处理的方式加快数据的传输,同时也借助MapReduce实现 ...
- hadoop 二次排序的一些思考
先说一下mr的二次排序需求: 假如文件有两列分别为name.score,需求是先按照name排序,name相同按照score排序 数据如下: jx 20 gj 30 jx 10 gj 15 输出结果要 ...
- Hadoop和RDBMS的混合系统介绍
现在大数据概念被时常提起,社会各界对其关注度越来越高.往往越是火热的东西,人们越容易忽略它的本质.在 slides 中,我首先按照自己的理解,简单的理顺数据处理领域的发展历程.之后,落脚点是两个比较有 ...
- Hadoop学习路线图
Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括, ...
- 对于spark以及hadoop的几个疑问(转)
Hadoop是啥?spark是啥? spark能完全取代Hadoop吗? Hadoop和Spark属于哪种计算计算模型(实时计算.离线计算)? 学习Hadoop和spark,哪门语言好? 哪里能找到比 ...
- Hadoop家族 路线图(转)
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- Hadoop虽然强大,但不是万能的(CSDN)
Hadoop很强大,但企业在使用Hadoop或者大数据之前,首先要明确自己的目标,再确定是否选对了工具,毕竟Hadoop不是万能的!本文中列举了几种不适合使用Hadoop的场景. 随着 Hadoop ...
- Hadoop学习(1)-- 入门介绍
Hadoop是Apache基金会开发的一个分布式系统基础架构,是时下最流行的分布式系统架构之一.用户可以在不了解分布式底层的情况下,在Hadoop上快速进行分布式应用的开发,并利用集群的计算和存储能力 ...
随机推荐
- 去除windows的Shift+Space 全角半角切换
windows7下的输入法,有一个“全/半角切换”的快捷方式“Shift+Space”,我们可以通过以下方式查看到: “开始”->“控制面板”->“区域和语言”->“键盘和语言”-& ...
- Mysql DBA 20天速成教程,DBA大纲
Mysql DBA 20天速成教程 基本知识1.mysql的编译安装2.mysql 第3方存储引擎安装配置方法3.mysql 主流存储引擎(MyISAM/innodb/MEMORY)的特点4.字符串编 ...
- freemarker 如何获得list的索引值
<#list toplist as toplists> ${toplists_index} </#list> 相当方便
- 函数fsp_alloc_seg_inode_page
分配一个新的inode page /**********************************************************************//** Allocat ...
- bzoj2668
对于这种题很容易看出是费用流吧…… 但这道题不容易建模: 首先是怎么表示目标状态和其实状态,看起来有黑有白很复杂 但实际上,不难发现,白色格子没什么用,起决定作用的是黑格子 也就是我们可以把问题简化: ...
- windows8安装xna4.0不能开发Xbox和PC端游戏的解决办法
vs2012安装wp8后,只能开发手机端的xna游戏程序,没有xbox和pc端的,看来官方是不打算更新了,不过我们还是有办法的. 前提条件下,您得安装了vs2010和xna4.0 game studi ...
- [POJ 2420] A Star not a Tree?
A Star not a Tree? Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 4058 Accepted: 200 ...
- C#中哈希表与List的比较
简单概念 在c#中,List是顺序线性表(非链表),用一组地址连续的存储单元依次存储数据元素的线性结构. 哈希表也叫散列表,是一种通过把关键码值映射到表中一个位置来访问记录的数据结构.c#中的哈希表有 ...
- 【转】parallels desktop 11 授权许可文件删除方法
原文网址:http://www.macappstore.net/tips/parallels-desktop-uninstall/ 很多同学在安装parallels desktop 11破解版后显示还 ...
- Entity Framework 并发处理
什么是并发? 并发分悲观并发和乐观并发. 悲观并发:比如有两个用户A,B,同时登录系统修改一个文档,如果A先进入修改,则系统会把该文档锁住,B就没办法打开了,只有等A修改完,完全退出的时候B才能进入修 ...