基于Python语言使用RabbitMQ消息队列(三)
发布/订阅
前面的教程中我们已经创建了一个工作队列。在一个工作队列背后的假设是每个任务恰好会传递给一个工人。在这一部分里我们会做一些完全不同的东西——我们会发送消息给多个消费者。这就是所谓的“发布/订阅”模式。
为了解释这种模式,我们将会构建一个简单的日志系统。它包含两个程序——第一个产生日志消息,第二个接收并把他们打印出来。
在我们的日志系统中,每一个接收程序的正在运行的拷贝都会获知消息,那样我们将能够运行一个接收者把日志指向磁盘;同时我们将能够运行另一个接收者在屏幕上查看日志。
实质上,被发布的消息将会广播给所有接收。
交易所
在前面的教程中我们向一个队列中发送和接收消息. 现在来介绍Rabbit中的完整的消息模型 .
我们快速回顾一下前面的教程:
- 生产者是一个发送消息的用户应用。
- 队列是一个存储消息的缓冲区。
- 消费者是一个接收消息的用户应用。
RabbitMQ中消息模型的核心思想是,生产者从不直接发送任何消息给一个队列。实际上,生产者通常甚至一点都不知道一条消息会被发送给什么队列。
相反,生产者只能发送消息给一个交易所(exchange)。交易所是一个很简单的东西。它一面接收来自生产者的消息,一面把消息推送给队列。交易所必须准确知道如何对待它接收到的消息。它该被追加到一个特定队列中吗?还是应该把它追加到多个队列?又或者它该被忽略?这些规则都是由交易类型(exchange type)所定义的。 
有几种可用的交易类型: direct, topic, headers 和 fanout. 我们会关注最后一个——fanout. 我们来创建一个这种类型的交易所,命名为 logs:
channel.exchange_declare(exchange='logs',
type='fanout')- 1
- 2
fanout类型交易所非常简单。从名字中你可能已经猜到(其实英语非母语的也不大好猜到,fan(风扇)+out(外、出)的组合,我觉得在这里可以理解为扇出去、扬出去的意思),它只是广播它接到的所有消息给它知道的所有队列 ,这恰恰是我们的日志程序所需要的。
列出所有交际所
为了列出所有交易所,你可以运行Trabbitmqctl:
sudo rabbitmqctl list_exchanges 在这个列表中会有些像amq.* 的交易所和默认的(未命名的)交易所
这些是被默认创建的,但你目前不太可能需要用到它们。默认交易所
在之前的教程中我们队交易所一无所知。但仍然能够给队列发送消息。这是因为我们使用了默认交易所,我们通过空字符串 (“”)来标识。
回顾一下我们之前如何发布一条消息:
channel.basic_publish(exchange='',
routing_key='hello',
body=message)exchange 参数就是交易所的名字。空字符串代表默认或者无名交易所:
消息路由到名字被routing_key所指定的队列,如果队列存在的话。
现在我们可以把消息发布到命名交易所了:
channel.basic_publish(exchange='logs',
routing_key='',
body=message)- 1
- 2
- 3
临时队列
你可能记得我们先前使用了有特定名字的队列 (记得 hello 和 task_queue?)。能给队列命名对我们来说很关键——我们需要把工人们指向同一个队列。当你想要在生产者和消费者中分享队列时,给队列一个名字就很重要。
但那不符合我们的日志程序需要。我们想获取所有日志消息,不只是他们的一个子集。我们也仅对当前活跃的消息感兴趣,而不是旧有的,解决这个问题我们需要做两件事。
第一,无论何时连接到Rabbit我们都需要一个新鲜的(fresh)空的(empty)队列 ,为实现这一点我们使用随机的名字创建一个队列,或者更好的——让服务器随机选一个队列名给我们。 我们不给queue_declare提供队列参数就可以做到:
result = channel.queue_declare()- 1
这样的话, result.method.queue 就会包含一个任意的队列名,例如它可能看上去是这样的 : amq.gen-JzTY20BRgKO-HjmUJj0wLg.
第二, 一旦我们断开消费者链接,队列就该被删除掉。通过一个exclusive 标志实现:
result = channel.queue_declare(exclusive=True)- 1
绑定

我们已经创建了一个fanout 交易所和一个队列。现在我们要通知交易所发送消息给我们的队列。交易所和一个队列之间的关系叫做绑定。
channel.queue_bind(exchange='logs',
queue=result.method.queue)- 1
- 2
从现在开始logs交易所会追加消息给我们的队列。
列出所有绑定
你可以列出所有存在的绑定,使用…好吧,你已经猜到了:
rabbitmqctl list_bindings
整合
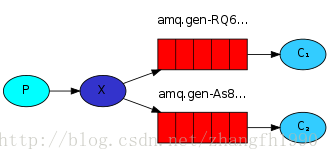
用来发送日志消息的生产者程序,看起来和之前并没有多大不同。最大的变化是我们现在想要发送消息给logs交易所而不是无名交易所。当发送时我们需要提供一个routing_key,但对于fanout类型交易所来说它的值是被忽略的。 下面是emit_log.py 脚本代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
如你所见,建立完连接后我们生命了交易所。这一步是必须的,因为发布到一个不存在的交易所是被禁止的。
如果没有队列连接(bound)到交易所,消息就会丢失,但对我们来说没有关系;如果没有消费者监听我们可以安全地忽略掉这个消息。
receive_logs.py代码:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
大功告成!如果你想把日志保存到一个文件中只需要打开控制台,键入:
python receive_logs.py > logs_from_rabbit.log- 1
如果你想在屏幕查看日志, 打开一个新的控制台运行:
python receive_logs.py- 1
下两图分别为在我的Ubuntu终端使用cat命令输出的存入到日志文件的日志和屏幕显示的日志
图1 
图2 
当然需要运行emit_log.py 
使用 rabbitmqctl list_bindings 你可以确认代码创建了绑定和队列,就像我们想要的那样。在两个运行的情况下你应该会看到如下内容:
sudo rabbitmqctl list_bindings
# => Listing bindings ...
# => logs exchange amq.gen-JzTY20BRgKO-HjmUJj0wLg queue []
# => logs exchange amq.gen-vso0PVvyiRIL2WoV3i48Yg queue []
# => ...done.- 1
- 2
- 3
- 4
- 5
结果的解释很直白: 来自logs交易所的数据去往两个服务器指定了名字的队列 ,这正是我们所预想的。
若想知道如何监听消息子集,请前往下一节。
基于Python语言使用RabbitMQ消息队列(三)的更多相关文章
- 基于Python语言使用RabbitMQ消息队列(一)
介绍 RabbitMQ 是一个消息中间人(broker): 它接收并且发送消息. 你可以把它想象成一个邮局: 当你把想要寄出的信放到邮筒里时, 你可以确定邮递员会把信件送到收信人那里. 在这个比喻中, ...
- 基于Python语言使用RabbitMQ消息队列(六)
远程过程调用(RPC) 在第二节里我们学会了如何使用工作队列在多个工人中分布时间消耗性任务. 但如果我们想要运行存在于远程计算机上的方法并等待返回结果该如何去做呢?这就不太一样了,这种模式就是常说的远 ...
- 基于Python语言使用RabbitMQ消息队列(五)
Topics 在前面教程中我们改进了日志系统,相比较于使用fanout类型交易所只能傻瓜一样地广播,我们用direct获得了选择性接收日志的能力. 虽然使用direct类型交易所改进了我们的系统,但它 ...
- 基于Python语言使用RabbitMQ消息队列(四)
路由 在上一节我们构建了一个简单的日志系统.我们能够广播消息给很多接收者. 在本节我们将给它添加一些特性——我们让它只订阅所有消息的子集.例如,我们只把严重错误(critical error)导入到日 ...
- 基于Python语言使用RabbitMQ消息队列(二)
工作队列 在第一节我们写了程序来向命名队列发送和接收消息 .在本节我们会创建一个工作队列(Work Queue)用来在多个工人(worker)中分发时间消耗型任务(time-consuming tas ...
- python学习之-- RabbitMQ 消息队列
记录:异步网络框架:twisted学习参考:www.cnblogs.com/alex3714/articles/5248247.html RabbitMQ 模块 <消息队列> 先说明:py ...
- Python并发编程-RabbitMQ消息队列
RabbitMQ队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
- OpenStack 安装数据库和rabbitmq消息队列 (三)
一)安装配置数据库 1.1.安装包 # yum install mariadb mariadb-server python2-PyMySQL -y 1.2.配置数据库 # vim /etc/my.cn ...
- Python RabbitMQ消息队列
python内的队列queue 线程 queue:不同线程交互,不能夸进程 进程 queue:只能用于父进程与子进程,或者同一父进程下的多个子进程,进行交互 注:不同的两个独立进程是不能交互的. ...
随机推荐
- 学习小程序第三天 WXML语言特性
WXML语言特性 1.数据绑定 Musstache 语法 获取json中指定键值:变量名加双括号的绑定语法 如下: (1)绑定文本 注意所有组件和属性 都要小写 (2)绑定属性 ( ...
- 【c++习题】【17/5/22】重载数组下标操作符
一.写出程序运行结果 1#include <iostream > using namespace std; int a[10]={1,2, 3, 4, 5, 6, 7, 8, 9, 10} ...
- EG:nginx反向代理两台web服务器,实现负载均衡 所有的web服务共享一台nfs的存储
step1: 三台web服务器环境配置:iptables -F; setenforce 0 关闭防火墙:关闭setlinux step2:三台web服务器 装软件 step3: 主机修改配置文件:vi ...
- 主攻ASP.NET.4.5 MVC4.0之重生:二维码生成和谷歌二维码
使用ThoughtWorks.QRCode.Codec 效果图 using ThoughtWorks.QRCode.Codec; 非原创代码 public void code(string id) { ...
- systemverilog新增的always_comb,always_ff,和always_latch语句
在Verilog中,设计组合逻辑和时序逻辑时,都要用到always: always @(*) //组合逻辑 if(a > b) out = 1; else out = 0; always @(p ...
- ACM训练小结-2018年6月14日
于恢复性训练Day2情况如下:https://vjudge.net/contest/234651 先看A题,读懂题意,没有想明白,码完后连续多次WA,后找到错误AC. 对B题,发现其是一个 ...
- Java Interface接口
Java 中接口概念 接口可以理解为一种特殊的 类,由 全局常量 和 公共的抽象方法 所组成. 类是一种具体实现体,而接口定义了某一批类所需要遵循的规范,接口不关心这些类的内部数据, 也不关心这些类里 ...
- Spring MVC 接收多个实体参数
在SpringMVC 的接收参数中,如果接收一个实体对象,只需要在方法参数中这样做:@RequestBody User user //单个的时候这样接收 @RequestMapping(value = ...
- streambase service 变为 window service启动
1.配置出.sbdeploy文件 2.安装streambase服务 streambase command line :--install-service 即可安装对应的的window service ...
- linux基础(9)-获取时间
获取今天日期 date +%Y-%m-%d date +%y-%m-%d date +%F 获取昨天日期 date -d yesterday +%F date -d -1day +%F ...