pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结
对于一个没有字段名标题的数据,如data.csv

1.获取数据内容。pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv")
print(df)
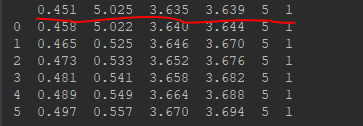
为了解决这个问题,我们添加“header=None”,告诉函数,我们读取的原始文件数据没有列索引。因此,read_csv为自动加上列索引。
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv", header=None)
print(df)
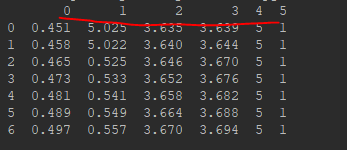
2.局部获取。有时候我们需要取某些列数据,如下(X,y):

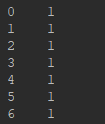
- pd.read_csv()函数有"header=None"参数:
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv", header=None)
# 注意有"header=None", df.ix[:,0:4]就是左闭右闭的区间
X= df.ix[:,0:4]
y = df.ix[:,5]
print(X)
print(y)

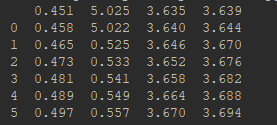
- pd.read_csv()函数没有"header=None"参数:
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv")
# 注意没有"header=None", df.ix[:,0:4]就是左闭右开的区间
X= df.ix[:,0:4] # 实际上X应该是df.ix[:,0:5]
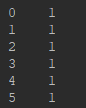
y = df.ix[:,5]
print(X)
print(y)
在第二种情况中,带上names属性还是df.ix[:,0:4]就是左闭右开的区间。
# 设置表头
names = ["US0","US1","US2","US3","US4","Class"]
# 读入数据 (没有属性行:header=None)
df = pd.read_csv("../data/data.csv", names=names)
# 注意没有"header=None", df.ix[:,0:4]就是左闭右开的区间
X= df.ix[:,0:4] # 实际上X应该是df.ix[:,0:5]
y = df.ix[:,5]
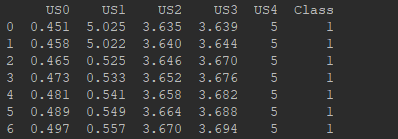
print(df)
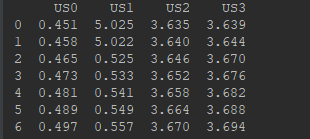
print(X)
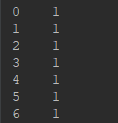
print(y)
总结:pd.read_csv()函数,有"header=None", df.ix[:,0:4]就是左闭右闭的区间;没有"header=None", df.ix[:,0:4]就是左闭右开的区间。
pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结的更多相关文章
- 【转】C#读取文件时的共享方式
string sFileName = @"C:\Exchange.dat";System.IO.StreamReader file = new System.IO.StreamRe ...
- python在读取文件时出现 'gbk' codec can't decode byte 0x89 in position 68: illegal multibyte sequence
python在读取文件时出现“UnicodeDecodeError:'gbk' codec can't decode byte 0x89 in position 68: illegal multiby ...
- Python读取文件时出现UnicodeDecodeError 'gbk' codec can't decode byte 0x80 in position x
Python在读取文件时 with open('article.txt') as f: # 打开新的文本 text_new = f.read() # 读取文本数据出现错误: UnicodeDecode ...
- Python读取文件时出现UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position xx: 解决方案
Python在读取文件时 with open('article.txt') as f: # 打开新的文本 text_new = f.read() # 读取文本数据 出现错误: UnicodeDecod ...
- pandas模块之读取文件
首先我们来看一个文件 1 男 北京 刘一 我笑 #跳过此行,序号1 2 女 上海 刘珊 你笑 3 男 杭州 刘五 他笑 #跳过此行,序号四 4 女 重庆 刘六 不笑了 下面来分析内容,并使用参数 1 ...
- 读取文件时,使用file.eof()判断结尾注意事项
今天写一个小功能需要读取文件,在判断文件结尾时使用了以下语句: while(infile.eof() && infile.good()) { infile.read((); encod ...
- 在系统中使用read函数读取文件内容
read函数(读取文件) read函数可以读取文件.读取文件指从某一个已打开地文件中,读取一定数量地字符,然后将这些读取的字符放入某一个预存的缓冲区内,供以后使用. 使用格式如下: number = ...
- nodejs读取文件时相对路径的正确写法(使用fs模块)
在开发nodejs中,我们往往需要读取文件或者写入文件,最常用的模块就是fs核心模块.一个最简单的写入文件的代码如下(暂时不考虑回调函数): fs.readFile("./test.txt& ...
- 第9.6节 Python使用read函数读取文件内容
一.语法 read(size=-1) read函数实际上在读取文本文件和二进制文件时,调用的是不同类的read,这是因为文本文件和二进制文件打开后返回的文件对象类型不同,同时读取的具体处理机制上也不同 ...
随机推荐
- Laravel 的 make:auth Artisan 命令到底生成了哪些文件?
众所周知,在 Laravel 中执行 $ php artisan make:auth $ php artisan migrate 命令后,我们就能拥有一个完整的登录.注册认证系统,这为开发带来极大的便 ...
- what is diff. b/w app state & session state
Application state is a data repository available to all classes in an ASP.NET application. Applicati ...
- MongoDB整理笔记のReplica oplog
主从操作日志oplog MongoDB的Replica Set架构是通过一个日志来存储写操作的,这个日志就叫做"oplog".oplog.rs是一个固定长度的capped coll ...
- java实现链式队列
java实现链式队列...比较简单 package datastruct; public class QueueLink implements Queue { // 定义一个节点内部类 class N ...
- javaweb分页
package com.aishang.util; //分页 public class Pagemethod { public static int[] getPageArray(int selInd ...
- Java集合类总结 (三)
HashSet类 关于HashMap的实现细节 HashMap是用LinkedList实现的,每个list被称为一个桶(bucket),在hashmap中要查找一个元素,首先对传入的key进行散列,并 ...
- cocos学习
第一章 JavaScript 快速入门 1.1 变量 在 JavaScript 中,我们像这样声明一个变量: var a; 保留字 var 之后紧跟着的,就是一个变量名,接下来我们可以为变量赋值: v ...
- HBase优化实战
本文来自网易云社区. 背景 Datastream一直以来在使用HBase分流日志,每天的数据量很大,日均大概在80亿条,10TB的数据.对于像Datastream这种数据量巨大.对写入要求非常高,并且 ...
- cinder侧卸载卷流程分析
cinder侧卸载卷分析,存储类型以lvm+iscsi的方式为分析基础在虚机卸载卷的过程中,主要涉及如下三个函数1)cinder.volume.api.begin_detaching 把volume的 ...
- 《C#多线程编程实战》2.3 Mutex
这个真的是大坑. 如果深入研究,像是同步域,上下文这类都会出现. 但是书上有没有讲. 完全不知道什么意思. 勉勉强强讲这个Mutex的用法搞明白了. 这个是原书代码: class Program { ...