pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结
对于一个没有字段名标题的数据,如data.csv

1.获取数据内容。pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv")
print(df)
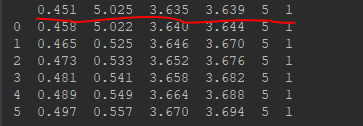
为了解决这个问题,我们添加“header=None”,告诉函数,我们读取的原始文件数据没有列索引。因此,read_csv为自动加上列索引。
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv", header=None)
print(df)
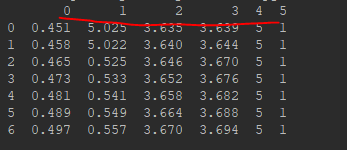
2.局部获取。有时候我们需要取某些列数据,如下(X,y):

- pd.read_csv()函数有"header=None"参数:
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv", header=None)
# 注意有"header=None", df.ix[:,0:4]就是左闭右闭的区间
X= df.ix[:,0:4]
y = df.ix[:,5]
print(X)
print(y)

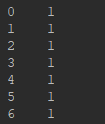
- pd.read_csv()函数没有"header=None"参数:
import pandas as pd
# 读取数据
df = pd.read_csv("../data/data.csv")
# 注意没有"header=None", df.ix[:,0:4]就是左闭右开的区间
X= df.ix[:,0:4] # 实际上X应该是df.ix[:,0:5]
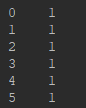
y = df.ix[:,5]
print(X)
print(y)
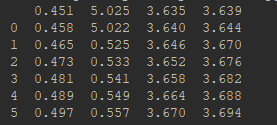
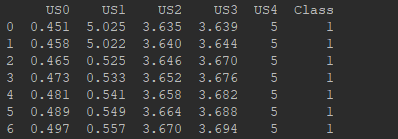
在第二种情况中,带上names属性还是df.ix[:,0:4]就是左闭右开的区间。
# 设置表头
names = ["US0","US1","US2","US3","US4","Class"]
# 读入数据 (没有属性行:header=None)
df = pd.read_csv("../data/data.csv", names=names)
# 注意没有"header=None", df.ix[:,0:4]就是左闭右开的区间
X= df.ix[:,0:4] # 实际上X应该是df.ix[:,0:5]
y = df.ix[:,5]
print(df)
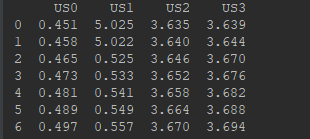
print(X)
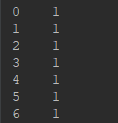
print(y)
总结:pd.read_csv()函数,有"header=None", df.ix[:,0:4]就是左闭右闭的区间;没有"header=None", df.ix[:,0:4]就是左闭右开的区间。
pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结的更多相关文章
- 【转】C#读取文件时的共享方式
string sFileName = @"C:\Exchange.dat";System.IO.StreamReader file = new System.IO.StreamRe ...
- python在读取文件时出现 'gbk' codec can't decode byte 0x89 in position 68: illegal multibyte sequence
python在读取文件时出现“UnicodeDecodeError:'gbk' codec can't decode byte 0x89 in position 68: illegal multiby ...
- Python读取文件时出现UnicodeDecodeError 'gbk' codec can't decode byte 0x80 in position x
Python在读取文件时 with open('article.txt') as f: # 打开新的文本 text_new = f.read() # 读取文本数据出现错误: UnicodeDecode ...
- Python读取文件时出现UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position xx: 解决方案
Python在读取文件时 with open('article.txt') as f: # 打开新的文本 text_new = f.read() # 读取文本数据 出现错误: UnicodeDecod ...
- pandas模块之读取文件
首先我们来看一个文件 1 男 北京 刘一 我笑 #跳过此行,序号1 2 女 上海 刘珊 你笑 3 男 杭州 刘五 他笑 #跳过此行,序号四 4 女 重庆 刘六 不笑了 下面来分析内容,并使用参数 1 ...
- 读取文件时,使用file.eof()判断结尾注意事项
今天写一个小功能需要读取文件,在判断文件结尾时使用了以下语句: while(infile.eof() && infile.good()) { infile.read((); encod ...
- 在系统中使用read函数读取文件内容
read函数(读取文件) read函数可以读取文件.读取文件指从某一个已打开地文件中,读取一定数量地字符,然后将这些读取的字符放入某一个预存的缓冲区内,供以后使用. 使用格式如下: number = ...
- nodejs读取文件时相对路径的正确写法(使用fs模块)
在开发nodejs中,我们往往需要读取文件或者写入文件,最常用的模块就是fs核心模块.一个最简单的写入文件的代码如下(暂时不考虑回调函数): fs.readFile("./test.txt& ...
- 第9.6节 Python使用read函数读取文件内容
一.语法 read(size=-1) read函数实际上在读取文本文件和二进制文件时,调用的是不同类的read,这是因为文本文件和二进制文件打开后返回的文件对象类型不同,同时读取的具体处理机制上也不同 ...
随机推荐
- 编写高质量代码改善C#程序的157个建议——建议37:使用Lambda表达式代替方法和匿名方法
建议37:使用Lambda表达式代替方法和匿名方法 在建议36中,我们创建了这样一个实例程序: static void Main(string[] args) { Func<int, int, ...
- Android 基于google Zxing实现对手机中的二维码进行扫描
转载请注明出处:http://blog.csdn.net/xiaanming/article/details/14450809 有时候我们有这样子的需求,需要扫描手机中有二维码的的图片,所以今天实现的 ...
- 验证码-WebVcode
验证码的实现 <img src="../Common/WebVcode.aspx" title="看不清?点此更换" alt="看不清?点此更换 ...
- attachEvent 与 addEventListener 的监听
说到 attachEvent 与 addEventListener 的事件必然会提到 浏览器的判断,因为attachEvent只适用于于IE 先来看看常用的浏览器的判断 //判断浏览器类型 if(n ...
- html5标签兼容低版本浏览器
随着html5(后面用h5代表)标签越来越广泛的使用,IE不识别h5标签的问题让人很是烦恼. 在火狐和chrome之类的浏览器中,遇到不认识的标签,只要给个display:block属性,就能让这个元 ...
- 异常上报功能Bugly简介
目的:为了能够快速定位到线上版本bug位置,经过比较之后,决定使用腾讯家的Bugly. 1.注册产品 官方文档使用指南 1.1 登录 - 使用 QQ 登录Bugly官网 没有账号就注册,要实名就实名, ...
- kali linux之edb--CrossFire缓冲区溢出
漏洞的罪恶根源------变量,数据与代码边界不清,开发人员对用户输入没做过滤,或者过滤不严 如这个脚本,写什么,显示什么,但是加上:,|,&&,后面加上系统命令,就执行命令了 缓冲区 ...
- Docker Community Edition 镜像使用帮助
1.什么是Docker 容器技术 在计算机的世界中,容器拥有一段漫长且传奇的历史.容器与管理程序虚拟化 (hypervisor virtualization,HV)有所不同,管理程序虚拟化通过中间层将 ...
- php常用的系统函数大全
字符串函数 strlen:获取字符串长度,字节长度 substr_count 某字符串出现的次数 substr:字符串截取,获取字符串(按照字节进行截取) mb_strlenmb_substr str ...
- Ajax轮询 select循环输出
弹出层 <include file="Pub:header"/> <style> .del{color:red} .addname{color:#337ab ...