word2vec是如何工作的?
如何有效的将文本向量化是自然语言处理(Natural Language Processing: NLP)领域非常重要的一个研究方向。传统的文本向量化可以用独热编码(one-hot encoding)、词袋模型(bag-of-words)和TF-IDF等方式,但是以上得到的文本向量可能维度都很好,在一些情况下可能并不适合进行NLP建模,如基于大量文本用独热编码的方式得到的向量维度是非常大的,这样子就不适合进行进一步分析及处理,并且丢失掉文本很多语意信息,无法高效地去发现文本中潜在的规律及模式。(好吧,废话有点多了!)所以13年的时候谷歌的研究员Tomas Mikolov(此人是大牛啊,12年在微软做实习生的时候就发现了词的语意是可以被更低维度的向量表示的,想想我那会还在迷茫人生,赶紧掩脸)通过训练一个浅层神经网络(如逻辑回归、线性判别分析模型等线性机器学习模型均可用)正式提出了Word2vec。
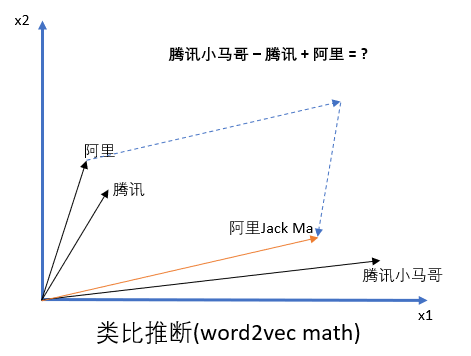
(好吧,我还是得继续多点废话,因为要先介绍下Word2Vec是怎么样一个算法)Word2Vec被提出来的时候就被划分为无监督学习,这个是因为被拿来做训练的文本是不需要有标记的,它是通过处理非常大量的文本数据来提取并学习文本中的语意的。利用word2vec算法,不需要告知算法腾讯的创始人是小马哥,也不需要知道阿里巴巴的创始人是Jack Ma,word2vec通过类比推断会自动去判别,如下面图所示(it is so powerful and magic, isn't it?),这是因为word2vec能从相似性的角度去做推断(这里的相似性不是说句型一样,而是语境语意类似,比如说北京天安门,众所周知这是一个景点,然后说广州小蛮腰,知道这也是一个景点,重点是语意理解上两个单词表达都是这么情况,跟上述腾讯和阿里巴巴创始人的例子类似)。说回标记的问题,这里其实很tricky,要说它是在没有标记的情况下进行训练的又不是很准确,因为其实它只是不需要人为对文本进行标记,但是算法本身是通过训练神经网络从句子中邻近的单词(surrounding words)来预测目标单词(target words),而之所以被归为无监督学习是因为标记本身就是来自文本数据。
但是预测结果并不是需要被担心和关注的点,这点需要被明确起来。接触过迁移学习(Transfer Learning)的人应该知道,我们一般会用一些已经训练好的模型来提取数据特征或者直接用于其他数据上(同等维度)得到想要的预测结果,这是因为神经网络经过训练之后,被保存下来的模型其实是一组参数矩阵,该参数矩阵代表了被预测值或者产生的特征,而word2vec在运用的过程中需要被关注的点也是在这里。
接下来看看Word2vec的表征是如何得到的?
主要可以用Skip-Gram和Continuous Bag-of-Words (CBOW)通过简单的神经网络训练得到word2vec嵌入(embedding)
1、Skip-gram
该方式主要是通过输入句子中特定的单词来预测该单词周边的其他单词。如下面图中的句子所示,假设分词得到如下的结果,句子前面是一共五个单词,Skip-gram的意思就是输入“喜欢”这个词,然后通过训练模型推断出“小马哥”、“非常”和“学习”、“自然语言处理”四个单词,当然这里是假设窗口大小为5。之所以叫Skip-gram是因为这是一个n-grams模型,但是不是固定长度的n-gram而是略过了中间的单词来进行建模的一个语言模型。回到上面的例子,更准确的讲法是通过“喜欢”来预测“小马哥”这个单词的时候,中间是略过了非常,以此类推下去。

word2vec的原作者是用soft-max来做为最后的分类器的,因为不是这篇的重点,所以就不讲soft-max是如何计算的了。模型都是跟数值直接打交道,所以我们需要对句子中的分词结果进行编码才能放入模型,而skip-gram的方式是直接用的独热编码的方式来对每个单词进行编码。具体的一个流程是对文本进行 分词 --> 统计词汇量 --> 基于词汇量对句子或者文本进行独热编码(向量wt表示的是该标识符在位置t的独热编码) --> 训练 --> 模型 --> 预测。网络结构可表述为下图所示,如果窗口大小为5,那么需要循环训练四次来得到目标单词周边的四个单词的预测结果:

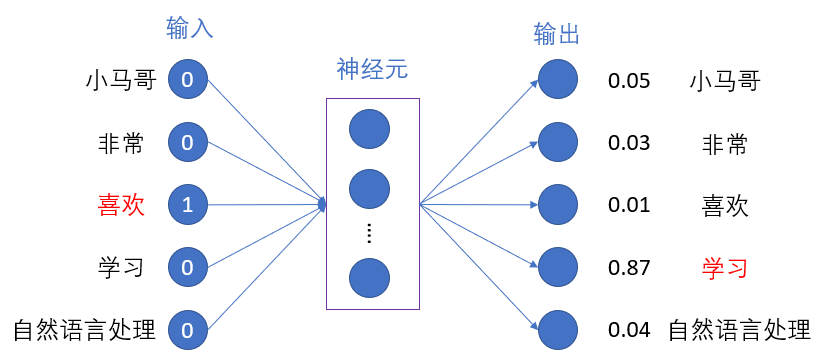
就如上述说的迁移学习,当skip-gram的模型训练结束之后,模型训练得到的参数矩阵(weight matrix)就是被训练用来表征语意的。这里得益于独热编码的好处,训练得到的参数矩阵的每一行就是表征了文本中的每个单词。这里可以参看上图,输入层是一个1 x 5的向量,假设隐藏层有3个神经元,那么从输入层映射到隐藏层需要一个5 x 3的矩阵,在经过训练迭代之后得到这个5 x 3矩阵中的每一行就是表征了相对应的单词(具体的计算方式可以参看下图)。所以这里的参数矩阵就是最终需要的词嵌入,而参数矩阵跟独热编码得到输入向量的内积得到的就是词向量。不仅如此,在原作者的论文,他们还证明了语意上相近的单词会有类似的向量表征,这是因为这些单词最终是都有类似的周边单词。
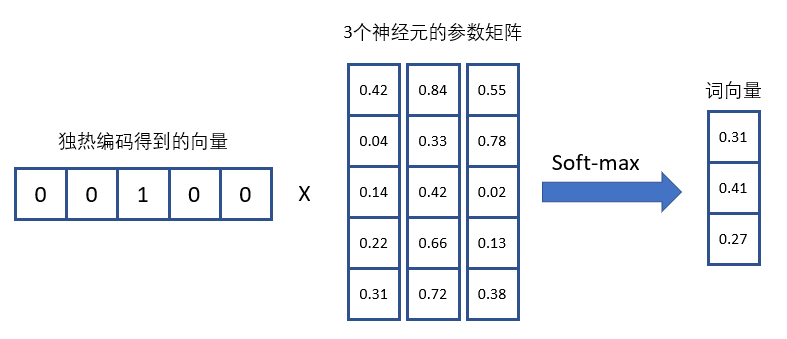
通过上述向量和矩阵的相乘,并引入softmax作为激活函数得到最终的结果,而通过结果就可以理解原本的向量是5维的,现在得到的词向量的维度变小了。
2、Continuous Bag-of-Words (CBOW)
CBOW是通过目标单词周边的单词来预测目标单词,这点刚好跟skip-gram模型相反。

而作为网络的输入不再仅仅是独热编码方式得到的结果,此时的输入是目标单词周边的每个单词独热编码的和。还是回到小马哥的例子,该句子中分词之后一共有13个词语(忽略句号和逗号),现在要预测的目标词语是“喜欢”,那么“小马哥”、“非常”和“学习”、“自然语言处理”这四个单词对各自独热编码的结果的和就是网络的输入。具体执行可以参看下图的神经网络执行过程:
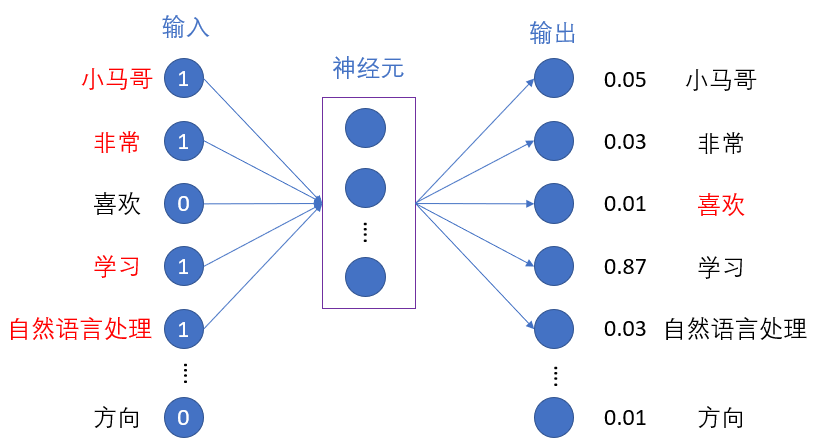
为了方便建立词语之间的联系,窗口是随着句子的方向滑动,并且选取中心词作为预测目标,目标词语的周边单词作为网络输入,而窗口中的五个词语的内容就是CBOW,如下图所示。

这就是如何通过skip-gram和CBOW训练得到词向量,也就是所谓的word2vec模型。论文的作者在论文中指出,skip-gram比较适合小型的文本集和文本中含有一些稀有词,而CBOW则比较适合文本中有高频出现的词语的文本集,这样子有助于提升训练的速度并且或者更高的准确性。
PS:基于的理解解析了该模型,如有任何问题,欢迎指出来一起讨论,非常感谢你读本博文。
word2vec是如何工作的?的更多相关文章
- 关于 word2vec 如何工作的问题
2019-09-07 22:36:21 问题描述:word2vec是如何工作的? 问题求解: 谷歌在2013年提出的word2vec是目前最常用的词嵌入模型之一.word2vec实际是一种浅层的神经网 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- NLP自然语言处理
转:https://blog.csdn.net/qq_17677907/article/details/86448214 1.有哪些文本表示模型,它们各有什么优缺点? 文本表示模型是研究如何表示文 ...
- FastText的内部机制
文章来源:https://towardsdatascience.com/fasttext-under-the-hood-11efc57b2b3 译者 | Revolver fasttext是一个被用于 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- word2vec 中的数学原理详解
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了很多人的关注.由于 word2vec 的作者 Tomas Miko ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 中英文维基百科语料上的Word2Vec实验
最近试了一下Word2Vec, GloVe 以及对应的python版本 gensim word2vec 和 python-glove,就有心在一个更大规模的语料上测试一下,自然而然维基百科的语料进入了 ...
随机推荐
- vue使用v-for循环,动态修改element-ui的el-switch
在使用element-ui的el-switch中,因为要用v-for循环,一直没有成功,后来仔细查看文档,发现可以这样写 <el-switch v-for="(item, key) i ...
- 兼容性良好的 sticky-footer 布局
<div class="content"> <div class="content-wrapper"> <div class=&q ...
- linux下ssh/sftp配置和权限设置
基于 ssh 的 sftp 服务相比 ftp 有更好的安全性(非明文帐号密码传输)和方便的权限管理(限制用户的活动目录). 1.开通 sftp 帐号,使用户只能 sftp 操作文件, 而不能 ssh ...
- java中泛型的简单使用
泛型是在jdk1.5之后引入的,我们可以在类的声明处增加泛型列表,如:<T,E,V>.此处,字符可以是任何标识符,一般采用这3个字母. 1.泛型类声明 class MyCollection ...
- flask笔记(一)
1.第一个flask项目 # 首先你要安装flask这个模块 pip install flask # 安装好了之后,直接新建一个py文件,开始写最简单的flask项目了 from flask impo ...
- Sass学习日志
一.什么是SASS SASS是一中CSS的开发工具,提供了许多便利的写法,大大节约了设计者们的时间,使得CSS的开发,变得简单和可维护.本文总结了SASS的主要方法.我们的目标是,有了这篇文章,日常的 ...
- C++最接近整数的浮点运算
Function return ceil 不小于给定值的最接近整数值 floor 不大于给定值的最接近整数 trunc (C++11) 绝对值不大于给定值的最接近整数 round(C++11) 最接近 ...
- Django模板简介
在settings.py中有个TEMPLATES的设置,其中BACKEND用来配置Django模板引擎, DIRS 定义了一个目录列表,模板引擎按列表顺序搜索这些目录以查找模板源文件 一般我们都会把模 ...
- jdbc执行过程 jar包下载
工具和准备: MYSQL 8.0jar包: 链接:https://pan.baidu.com/s/1O3xuB0o1DxmprLPLEQpZxQ 提取码:grni 使用eclipse开发首先把jar包 ...
- flex布局入门总结——语法篇
前几天看了阮一峰的Flex布局教程,讲的很不错,总结一下,有兴趣的可以去看原文http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html 一 F ...