Kafaka高可用集群环境搭建
zk集群环境搭建:https://www.cnblogs.com/toov5/p/9897868.html
三台主机每台的Java版本1.8
下面kafka集群的搭建:
3台虚拟机均进行以下操作:
// 解压下载好的kafka压缩包并重命名
cd /home
wget http://mirror.bit.edu.cn/apache/kafka/1.1.1/kafka_2.11-1.1.1.tgz
tar -xzvf kafka_2.11-1.1.1.tgz
mv kafka_2.11-1.1.1 kafka
// 修改配置文件
vi ./kafka/config/server.properties
修改如下:
主机1的:(其他主机类似)
broker.id=0 #做标记的哦 其他的主机 1 2 与Zookeeper的data目录下的myId一致!
listeners=PLAINTEXT://192.168.91.1:9092 #监听的IP地址和端口号 这其实是个协议 要写全! 监听的本机的ip端口号哈 其他的主机ip地址更改
zookeeper.connect=192.168.91.1:2181,192.168.91.3:2181,192.168.91.4:2181 #zk的集群地址
然后修改系统环境中配置kafka的路径
vi /etc/profile
// 在文件最下方添加kafka路径
export KAFKA_HOME=/home/kafaka/kafka
// PATH的修改 多路径PATH写法为PATH=${ZOOKEEPER_HOME}/bin:${KAFKA_HOME}/bin:$PATH
$PATH:${KAFKA_HOME}/bin
我的配置后:
export PATH=$PATH:${KAFKA_HOME}/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH

// 使修改完的环境变量生效
source /etc/profile
此时 其他的两台
scp -r ./kafaka/ root@192.168.91.3:/home
scp -r ./kafaka/ root@192.168.91.4:/home
然后分别修改server.properties
broker.id=X #做标记的哦 其他的主机 X =1 和 2
listeners=PLAINTEXT://192.168.91.X:9092 #监听的IP地址和端口号 这其实是个协议 要写全! 监听的本机的ip端口号哈 其他的主机ip地址更改
,修改 /etc/profile 与第一台一致
此时的环境便搭建完毕!
先启动Zookeeper集群,
逐个主机启动: /home/zookeeper/zookeeper-3.4.6/bin/zkServer.sh start
查看启动状态: /home/zookeeper/zookeeper-3.4.6/bin/zkServer.sh status
再启动kafka集群
2、在后台开启3台虚拟机的kafka程序
/home/kafaka/kafka
./bin/kafka-server-start.sh -daemon config/server.properties
启动成功!
注意每个服务器要关闭防火墙!!
Kafka 没有后台图形化 不跟rabbitmq似的哈哈
查看Zookeeper:

每个broker启动后 会去zk注册信息,创建节点信息

下面创建个topic试试:
参考官网:http://kafka.apachecn.org/quickstart.html
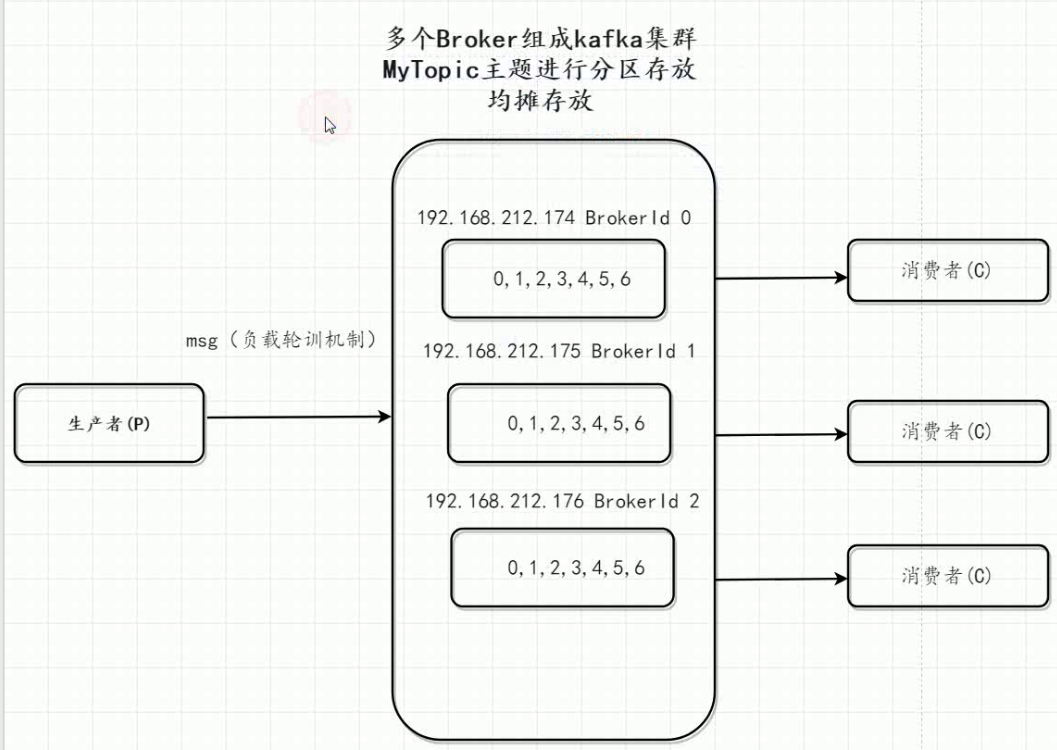
创建topic时候 需要指定分区partition 1 表示只在一个broker里面存放。(单节点存放)
3 表示三个broker里面存放 。生产者投递消息时候 均摊存放!

只会在1个broker进行创建
在某一台服务器上创建 topic:
/home/kafaka/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.91.1:2181 --replication-factor 1 --partitions 1 --topic test # 创建topic时候 会向zk进行连接 1表示在单机上存储创建

zk查看:

broker就是我们指定的这台服务器上 partition是1 的话每次都投递到 0这个broker上哦
下面介绍下日志查看:
kafka的日志存放是在配置中的 server.properties:

创新topic后发送消息
往指定的broker发送消息
bin/kafka-console-producer.sh --broker-list 192.168.91.1:9092 --topic test

启动consumer进行消费:连接的不是同一台主机,也可以进行消费
bin/kafka-console-consumer.sh --bootstrap-server 192.168.91.3:9092 --topic test --from-beginning

同是一个集群。互通的 ,只是消息存放的地方有别而已。
继续创建topic,存放到三个broker:
/home/kafaka/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.91.1:2181 --replication-factor 1 --partitions 3 --topic my_test_topic
创建成功后查看日志目录:
broker0

broker1

broker2

通过test-0 my_test_topic_x 可以看出编号是有自己的算法的
得出的结论是 topic 在三台不同的节点进行存放的,生产者投递消费进行均摊。
Kafaka高可用集群环境搭建的更多相关文章
- ElasticSearch高可用集群环境搭建和分片原理
1.ES是如何实现分布式高并发全文检索 2.简单介绍ES分片Shards分片技术 3.为什么ES主分片对应的备分片不在同一台节点存放 4.索引的主分片定义好后为什么不能做修改 5.ES如何实现高可用容 ...
- SpringCloud之Eureka高可用集群环境搭建
注册中心集群 在微服务中,注册中心非常核心,可以实现服务治理,如果一旦注册出现故障的时候,可能会导致整个微服务无法访问,在这时候就需要对注册中心实现高可用集群模式. Eureka集群相当简单:相互注册 ...
- rabbitmq+haproxy+keepalived高可用集群环境搭建
1.先安装centos扩展源: # yum -y install epel-release 2.安装erlang运行环境以及rabbitmq # yum install erlang ... # yu ...
- CentOS下RabbitMq高可用集群环境搭建
准备工作 1,准备两台或多台安装有rabbitmq-server服务的服务器 我这里准备了两台,分别如下: 192.168.40.130 rabbitmq01192.168.40.131 rabbit ...
- Mysql高可用集群环境介绍
MySQL高可用集群环境搭建 01.MySQL高可用环境方案 02.MySQL主从复制原理 03.MySQL主从复制作用 04.在Linux环境上安装MySQL 05.在MySQL集群环境上配置主从复 ...
- Apache httpd和JBoss构建高可用集群环境
1. 前言 集群是指把不同的服务器集中在一起,组成一个服务器集合,这个集合给客户端提供一个虚拟的平台,使客户端在不知道服务器集合结构的情况下对这一服务器集合进行部署应用.获取服务等操作.集群是企业应用 ...
- Flink的高可用集群环境
Flink的高可用集群环境 Flink简介 Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能. 因现在主要Flink这一块做先关方面的学习, ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- Mysql双主双从高可用集群的搭建且与MyCat进行整合
1.概述 老话说的好:瞻前顾后.患得患失只会让我们失败,下定决心,干就完了. 言归正传,之前我们聊了Mysql的一主一从读写分离集群的搭建,虽然一主一从或一主多从集群解决了并发读的问题,但由于主节点只 ...
随机推荐
- Ubuntu 下Apache安装和配置2
在Ubuntu上安装Apache,有两种方式:1 使用开发包的打包服务,例如使用apt-get命令:2 从源码构建Apache.本文章将详细描述这两种不同的安装方式. 方法一:使用开发包的打包服务—— ...
- mongo 过滤查询条件后分组、排序
描述:最近业主有这么一个需求,根据集合中 时间段进行过滤,过滤的时间时间段为日期类型字符串,需要根据某一日期进行截取后.进行分组,排序 概述题目:根据createTime时间段做查询,然后以 天进行分 ...
- python cPickle和pickle 序列化
在Python中提供了两个模块:cPickle和pickle来实现序列化,前者是由C语言编写的,效率比后者高很多,一般编写程序的时候,采取的方案是先导入cPickle模块,如果此模块不存在,再导入pi ...
- 洛谷P1122 最大子树和
P1122 最大子树和 题目提供者该用户不存在 标签动态规划树形结构 难度普及/提高- 通过/提交54/100 提交该题 讨论 题解 记录 题目描述 小明对数学饱有兴趣,并且是个勤奋好学的学生,总是在 ...
- 《从零开始学Swift》学习笔记(Day 39)——构造函数重载
原创文章,欢迎转载.转载请注明:关东升的博客 构造函数作为一种特殊方法,也可以重载. Swift中构造函数可以多个,他们参数列表和返回值可以不同,这些构造函数构成重载. 示例代码如下: class ...
- 解决asp.net中HTML中talbe的行高被内容撑的变高的问题
将asp.net页面中的如下语句: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" " ...
- 明文post密码
w 作者:余天升链接:https://www.zhihu.com/question/20306241/answer/14696464 看到上面几位的回答,我真心觉得,当前信息安全保护的意识过于低下,连 ...
- .net 取得类的属性、方法、成员及通过属性名取得属性值
//自定义的类 model m = new model(); //取得类的Type实例 //Type t = typeof(model); //取得m的Type实例 Type t = m.G ...
- MySQL中的SQL流程分析简述
分析MySQL中这条语句的整个流程 update table_a set c1=xx where c2=xxx 朋友考我的一个问题在此处列出个人见解 1 客户端连接进来首先进行权限验证 2 验证通过后 ...
- Python打印一个等边三角形
如图所示: * *** ***** ******* ********* #想要几层就输入数字几, num = int(input('请输入一个奇数数字:')) for i in range(num,0 ...