Spark-源码-Spark-Submit 任务提交
Spark 版本:1.3
调用shell, spark-submit.sh args[]
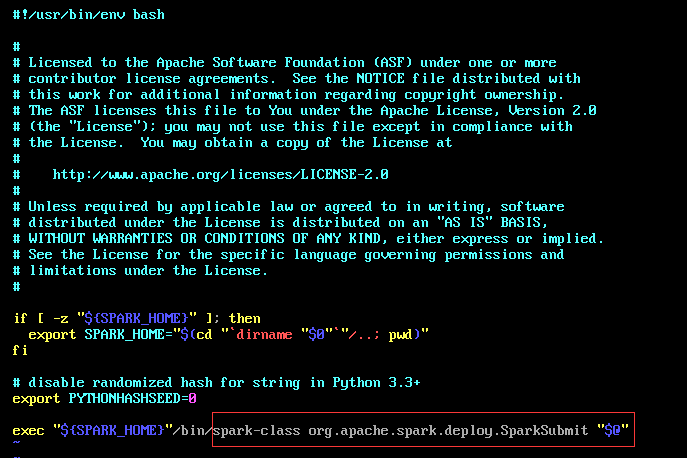
首先是进入 org.apache.spark.deploy.SparkSubmit 类中
调用他的 main() 方法
def main(args: Array[String]): Unit = {
//
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
1.1 val appArgs = new SparkSubmitArguments(args) /*在SparkSubmitArguments(args)中获取到提交参数并进行一些初始化,*/
"""将我们手动写出的args赋值到 SparkSubmitArguments 的各个变量中"""
parseOpts(args.toList)
"""将没有写出的args通过默认文件赋值为默认变量"""
mergeDefaultSparkProperties()
"""使用`sparkProperties`映射和env vars来填充任何缺少的参数"""
loadEnvironmentArguments() 此时将 action:SparkSubmitAction = Option(action).getOrElse(SUBMIT) """也就是说在没有指定action 的情况下默认为 SUBMIT"""
validateArguments() """确保存在必填字段。 只有在加载所有默认值后才调用此方法。"""
1.2 if (appArgs.verbose) {
printStream.println(appArgs)
}
"""如果我们手动写出了verbose参数为true 则打印如下的变量信息"""
"""master deployMode executorMemory executorCores totalExecutorCores propertiesFile driverMemory driverCores
driverExtraClassPath driverExtraLibraryPath driverExtraJavaOptions supervise queue numExecutors files pyFiles
archives mainClass primaryResource name childArgs jars packages packagesExclusions repositories verbose"""
1.3 appArgs.action match {case SparkSubmitAction.SUBMIT => submit(appArgs)...}
"""匹配action的值(其实是个枚举类型的匹配), 匹配 SparkSubmitAction.SUBMIT 执行submit(appArgs)"""
2.1 submit(args: SparkSubmitArguments)
/**
* Submit the application using the provided parameters.
*
* This runs in two steps. First, we prepare the launch environment by setting up
* the appropriate classpath, system properties, and application arguments for
* running the child main class based on the cluster manager and the deploy mode.
* Second, we use this launch environment to invoke the main method of the child
* main class.
*/
private[spark] def submit(args: SparkSubmitArguments): Unit = {
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args) def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
exitFn()
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
使用提供的参数提交申请。这分两步进行。
"""首先,我们通过设置适当的类路径,系统属性和应用程序参数来准备启动环境,以便 根据 集群管理器 和 部署 模式运行子主类。"""
"""其次,我们使用此启动环境来调用子主类的main方法。"""
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args) //为变量赋值
在独立群集模式下,有两个提交网关:
(1)传统的Akka网关使用 o.a.s.deploy.Client 作为包装器(wrapper)
(2)Spark 1.3中引入的基于REST的新网关
后者是Spark 1.3的默认行为,但如果主端点不是REST服务器,Spark提交将故障转移以使用旧网关。
根据他的部署模式来运行或者(failOver重设参数并重新提交) 之后执行 doRunMain()方法
2.1.1 doRunMain()
其中如果有proxyUser属性则去获取他的代理对象调用proxyUser的 runMain(...)方法, 没有则直接运行 runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
2.2 def runMain(childArgs: Seq[String],childClasspath: Seq[String],sysProps: Map[String, String],childMainClass: String,verbose: Boolean):Unit
"""使用提供的启动环境运行子类的main方法。 请注意,如果我们正在运行集群部署模式或python应用程序,则此主类将不是用户提供的类。"""
Thread.currentThread.setContextClassLoader(loader) 给当前线程设置一个Context加载器(loader)
for (jar <- childClasspath) { addJarToClasspath(jar, loader) } 将childClasspath的各个类加载,实际上是调用的 loader.addURL(file.toURI.toURL) 方法
for ((key, value) <- sysProps) {System.setProperty(key, value) } 将各个系统参数变量设置到系统中
mainClass: Class[_] = Class.forName(childMainClass, true, loader) 使用loader将我们写的主类加载 利用反射的方法加载主类
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass) 加载mainMethod,并在接下来的代码中对它做检查,
必须是static~("The main method in the given main class must be static")
mainMethod.invoke(null, childArgs.toArray)
到此为止启动我们的主类的main方法!!!
Spark-源码-Spark-Submit 任务提交的更多相关文章
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
- Spark源码分析之二:Job的调度模型与运行反馈
在<Spark源码分析之Job提交运行总流程概述>一文中,我们提到了,Job提交与运行的第一阶段Stage划分与提交,可以分为三个阶段: 1.Job的调度模型与运行反馈: 2.Stage划 ...
- Spark 源码浅读-SparkSubmit
Spark 源码浅读-任务提交SparkSubmit main方法 main方法主要用于初始化日志,然后接着调用doSubmit方法. override def main(args: Array[St ...
- Spark 源码解析:TaskScheduler的任务提交和task最佳位置算法
上篇文章< Spark 源码解析 : DAGScheduler中的DAG划分与提交 >介绍了DAGScheduler的Stage划分算法. 本文继续分析Stage被封装成TaskSet, ...
- Spark源码分析之四:Stage提交
各位看官,上一篇<Spark源码分析之Stage划分>详细讲述了Spark中Stage的划分,下面,我们进入第三个阶段--Stage提交. Stage提交阶段的主要目的就一个,就是将每个S ...
- spark 源码分析之十九 -- Stage的提交
引言 上篇 spark 源码分析之十九 -- DAG的生成和Stage的划分 中,主要介绍了下图中的前两个阶段DAG的构建和Stage的划分. 本篇文章主要剖析,Stage是如何提交的. rdd的依赖 ...
- Spark源码分析:多种部署方式之间的区别与联系(转)
原文链接:Spark源码分析:多种部署方式之间的区别与联系(1) 从官方的文档我们可以知道,Spark的部署方式有很多种:local.Standalone.Mesos.YARN.....不同部署方式的 ...
- Spark源码分析 -- TaskScheduler
Spark在设计上将DAGScheduler和TaskScheduler完全解耦合, 所以在资源管理和task调度上可以有更多的方案 现在支持, LocalSheduler, ClusterSched ...
- Spark源码分析 – DAGScheduler
DAGScheduler的架构其实非常简单, 1. eventQueue, 所有需要DAGScheduler处理的事情都需要往eventQueue中发送event 2. eventLoop Threa ...
- spark 源码分析之四 -- TaskScheduler的创建和启动过程
在 spark 源码分析之二 -- SparkContext 的初始化过程 中,第 14 步 和 16 步分别描述了 TaskScheduler的 初始化 和 启动过程. 话分两头,先说 TaskSc ...
随机推荐
- Siebel Tools配置
默认安装的Siebel+Tools,Tools登陆时有3个选项:Local.Sample.Server,具体涵义如下: Local:指本地数据库.按照Siebel开发建议,开发人员需要从Siebel ...
- 2016微软技术大会Azure相关回顾
3 天的时间稍纵即逝,伴随着本届大会压轴大奖的揭晓,2016 年度的微软技术大会完美落幕.以“数字化转型”为主题,来自微软全球的近百位顶尖技术专家.工程师和业务负责人拔冗而至,在 130 余场的专业技 ...
- MapReduce框架结构及代码示例
一个完整的 mapreduce 程序在分布式运行时有三类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.MapTask:负责 map 阶段的整个数据处理流程 3.Redu ...
- GridView的分页代码
1.前台代码 <PagerTemplate><div style="text-align:center; color:Blue"> <asp:Link ...
- Flask入门模板Jinja2语法与函数(四)
1 模板的创建 模板文件结构: project/ templates/ 模板文件 跳转模板一般使用: from flask import render_template,render_template ...
- C# WinForm 程序免安装 .NET Framework(XP/win7/win10环境运行)
前文 首先感谢群里的大神宇内流云 提供的anyexec for windows版本. 经过本人搭建虚拟机在xp环境 使用anyexec运行winfrom程序后,测试通过,如下是用的xp运行winfro ...
- /etc/hosts.allow和/etc/hosts.deny详解
今天遇到一台服务器22端口正常,但是通过ssh连接的问题.排查了防火墙和端口问题,半天没有找出来原因,后来求助大神,终于明白了通过etc目录下hosts.deny和hosts.allow文件可以限制远 ...
- Git/Github Learning
通过网上查找资料,我了解到Git/Github是一款免费.开源的分布式版本控制系统,它可以敏捷高效地处理任何或小或大的项目.同时,它是一个开源的分布式版本控制系统,用以有效.高速的处理从很小到非常大的 ...
- 【洛谷5287】[HNOI2019] JOJO(主席树优化KMP)
点此看题面 大致题意: 每次往一个字符串末尾加上\(x\)个字符\(c\),或者回到某一历史版本,求\(KMP\)的\(\sum Next_i\). 问题转化 考虑到可以离线. 于是,我们就可以用一个 ...
- POJ 1503 大整数
之前做的大整数,都是一位一位操作. 优化方案:压缩方案. 模板: + - * 操作符重载 #include<cstdio> #include<iostream> #inclu ...