SIMD数据并行(三)——图形处理单元(GPU)

在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multiple Data,单指令流多数据流)。其中MIMD的表现形式主要有多发射、多线程、多核心,在当代设计的以处理能力为目标驱动的处理器中,均能看到它们的身影。同时,随着多媒体、大数据、人工智能等应用的兴起,为处理器赋予SIMD处理能力变得愈发重要,因为这些应用存在大量细粒度、同质、独立的数据操作,而SIMD天生就适合处理这些操作。
SIMD结构有三种变体:向量体系结构、多媒体SIMD指令集扩展和图形处理单元。本文集中围绕图形处理单元( Graphics Processing Unit, GPU)进行描述。
图形处理单元(GPU)
0. 写在前面
GPU 独立于 CPU 而发展,拥有自己的一套体系结构,并在发展中形成了自己的专门术语。加上不同设计厂商之间使用的术语往往不太一样,容易给 GPU 初学者带来名词分辨上的困扰。
鉴于 NVIDIA GPU 的成功,本文只使用 NVIDIA 官方术语进行表述。我自己在看《计算机体系结构:量化方法研究》这本书时,也存在着不少困惑,有些名词感觉前后表达的意思不容易对上号,甚至多看几遍之后,困惑愈深。不过最终我还是理了一个基本不差的脉络出来,如果有读者发现我表述中差错的地方,敬请指正。
1. 简介
谈到 GPU,人们首先想到的可能是「显卡」,进而想到「英伟达(NVIDIA)」。的确, GPU 的祖先便是图形加速器,用于辅助 CPU 做图形处理的工作,而黄仁勋创办的英伟达正是 GPU 领域的佼佼者,不断引领着 GPU 架构的发展革新。
我们知道,图形显示是由一个个细小的像素组合而成,在计算机的世界中,像素的变化即意味着一组固定宽度比特位所表示的参数的变化。因此,对一副图形进行变换,本质上是对成千上万个像素的参数进行计算的结果,而这其中必然存在大量的数据并行度。
GPU 天生是处理并行问题的好手,在它的体系结构中融合了线程并行、指令并行、SIMD 数据并行的多种并行处理形式,它可以概括为是一个由多个多线程 SIMD 处理器组成的 MIMD 处理器。
GPU 处理数据并行任务能有很好的效能比,但处理控制为主的任务则不够经济,因此 GPU 一直以来是作为 CPU 的外设而存在的。随着异构处理器的兴起,二者常常被集成在同一个处理器芯片中,相辅相成。同时,GPU的计算能力已不局限于图形处理,而是正在被迁移到更多的数据并行计算场景。
2. 架构组成
了解 GPU 比较适合先从一个大的角度看下去,然后往下深入到局部的部件。正所谓「窥一斑而现全身」,从图1可以看到,GPU 几乎是由众多相同的部件复制组合而成。
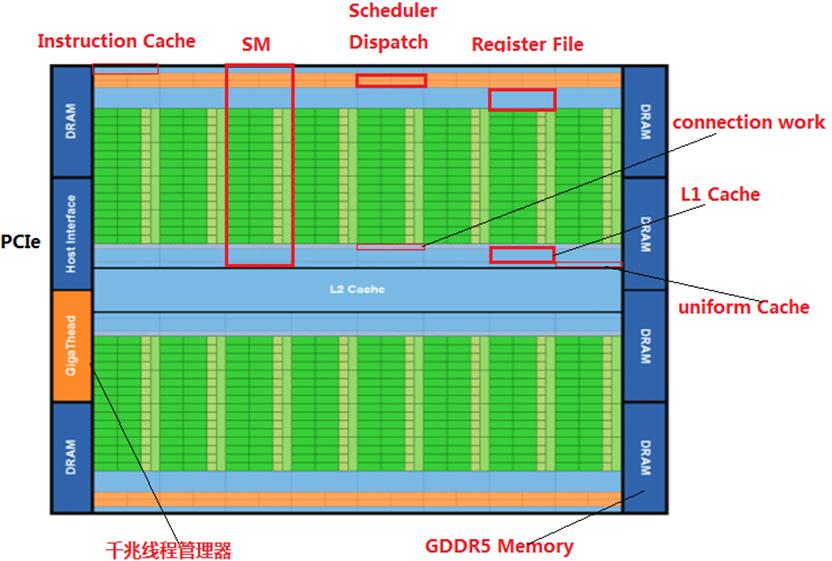
图1 Fermi GTX 480 GPU 的平面图
从硬件抽象的角度看:
GPU,与 CPU 经总线连接通信,并通过片外 DRAM 交换数据。GPU 的主体由多个(16/32···)相同的流式多处理器组成。
流式多处理器(Streaming Multiproeessor,SM),它是具有独立PC的完整处理器。每个流式多处理器拥有多个(16···)独立 SIMD 线程,称为「warp」。各 warp 不会同时执行,而是依据每个 warp 的忙闲状态进行恰当的调度,这也正是 GPU 设计的基本思想:通过足够多的线程切换来隐藏访问 DRAM 的延迟。
warp,每个 warp 有自己的 PC,执行 SIMD 指令完成计算和访存。SIMD 指令功能单元含有多个(16/32···)并行的线程处理器(或者说车道)
线程处理器,它执行一个 warp 中 SIMD 指令对应的单个元素,可根据谓词寄存器或者遮罩位状态,决定执行或忽略对应元素的操作。同一个 warp 中的多个车道不能同时执行不同指令。
从程序抽象的角度看:
网格,在 GPU 上运行,由一个或多个线程块构成的代码。
线程块,在流式多处理器上执行的向量化循环,由一个或多个 SIMD指令线程构成。
CUDA 线程,SIMD 指令线程的垂直抽取,对应于车道所执行的单个元素。
GPU 拥有两层硬件调度程序:
线程块调度器(NVIDIA 称 Giga 线程引擎),将线程块指定给流式多处理器,确保线程块被分配给其共享存储器拥有相应数据的流式多处理器。
warp 调度器,流式多处理器内部的SIMD线程(warp)调度程序,由它来调度应该何时运行哪个warp。一个流式多处理器中可能同时存在两个 warp 调度器。
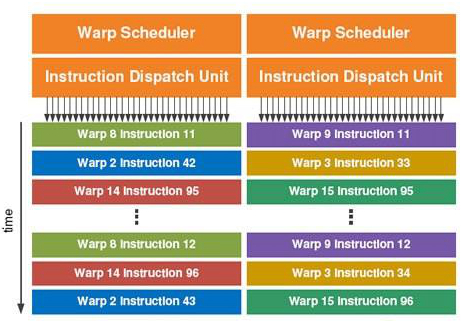
图2 warp 调度器分配指令给 warp 执行(图中含两个warp 调度器)
从存储器的角度看:
全局存储器,由GPU所有流式处理器共享,它是位于流式处理器片外的 DRAM。流式处理器间不能直接进行通信,但可以使用全局存储器中的原子存储操作进行协调。系统处理器(CPU)和 GPU 之间的数据交换也是通过全局存储器。
共享存储器,位于流式处理器内部,这一存储器由单个流式处理器内部所有 warp 共享,但无法被其它流式处理器访问。流式处理器内的 warp 可以通过共享存储器进行通信。
局部存储器,各 warp 在片外 DRAM 获得的一个专用部分,它不能在同一流式处理器的各 warp 间共享。局部存储器用于栈帧、溢出寄存器和不能放在寄存器中的私有变量。
寄存器,大量存在于 GPU中。由于每一个 warp 都是一个独立的线程,因此各 warp 都分配有独立的向量寄存器组,寄存器组中的每一个向量寄存器有N个元素(16/32···),N 为 GPU 的向量长度。
缓存,在 GPU 中的容量不如 CPU,因为 GPU 不依赖大型缓存来包含应用程序的整个工作集,而是使用较少的流式缓存,依靠大量的线程来隐藏访问 DRAM 的长延迟。CPU 中用来放置cache的芯片面积在 GPU 中替换为计算资源和大量的寄存器,用来执行大量的 SIMD 线程。GPU 中的缓存要么被看作带宽滤选器,以减少对全局存储器的要求,要么被看作有限几种变量的加速器,这些变量的修改不能通过多线程来隐藏。
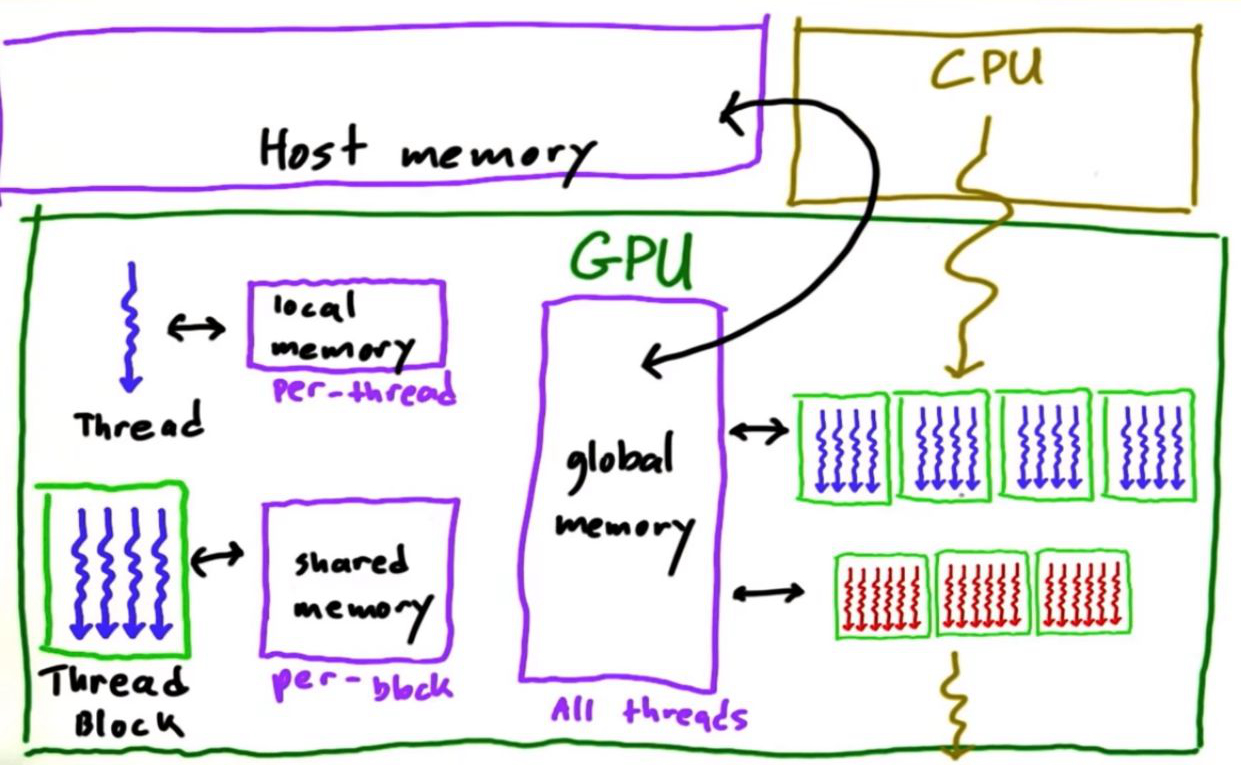
图3 GPU 存储访问关系
图4 显示了以上软硬件之间的层级对应关系:

图4 GPU 软硬件间的层级对应关系
3. GPU的条件分支
相比于向量体系结构,GPU提供了更多的硬件机制来实现 warp 中的分支处理。GPU 用于处理分支的硬件有:谓词寄存器、分支同步栈、指令标记、内部遮罩。
当条件分支较简单时,编译器将代码编译成仅使用谓词寄存器的条件执行指令。谓词被设置为1的车道将执行操作并存储指令;其它车道将不执行和存储结果。
当面对更复杂的控制流时,编译器将混合使用谓词寄存器和 GPU 分支指令。特殊的指令和标记将用于这些分支指令,在执行到这些分支指令时,先向分支同步栈中压入一个栈项(主要为遮罩),随后联合谓词寄存器的内容更新遮罩,在跳转的目标分支中通过遮罩来决定对应车道是否执行操作和存储;当分支结束,则弹出并恢复栈项。整个过程类似于函数调用过程中的现场保存和恢复机制,因此可实现多层分支的嵌套。
由于同一 warp 内的不同车道不能同时执行不同指令,使得 GPU 必须计算所有的分支,而各分支执行过程中必然存在部分车道执行、其它车道空闲的情况。这带来了 GPU 工作效率的下降。比如,对于相同长度的路径,if-then-else的工作效率为50%;对于嵌套的分支语句,这一效率将进一步降低。幸运的是, GPU 可以在运行时,在遮罩位为全0或全1时,略过 then 或 else 部分。
编程利器——CUDA
当 GPU 的计算潜力与一种简化 GPU 编程的编程语言相结合,使人们对 GPU 计算的兴趣大增。
编写并行程序天生要比编写顺序程序复杂得多,因为编译器只能自动并行化一些简单的并行情况,大部分时候都需要编程者自己给出并行化的信息,并进行合理的调度,以使得并行化的效能最大化。
CUDA (Compute Unified Device Architecture,计算统一设备体系结构)就是 NVIDIA 开发的一种与 C 类似的语言和编程环境,通过克服异质计算 及多种并行带来的双重挑战来提高 GPU 程序员的生产效率。
CUDA 并不只为 GPU 编程,而是把 CPU 和 GPU 当作一个整体来编程。CUDA 为系统处理器(主机)生成 C/C++,为 GPU(设备)生成 C/C++ 方言。
CUDA 将 CUDA 线程作为编程原型,表示最低级别的并行。编译器和硬件可以将数以千计的 CUDA 线程聚合在一起,利用 GPU 中的多种并行类型:多线程、MIMD、SIMD、指令并行。
关于 CUDA 语言的具体语法以及编程技巧,是一个比较大的内容,本文只介绍其概念,不做赘述。后期等信号君学习了相关的内容,可以分一个系列再来和大家探讨。
物理指令集抽象——PTX指令集
与大多数系统处理器不同,NVIDIA 编译器的指令集目标是硬件指令集的一种抽象,NVIDIA 称之为 PTX 指令集。
编译器生成的指令与 PTX 指令一一对应,但一个 PTX 指令可以扩展到许多机器指令,反之亦然。PTX 使用虚拟寄存器,而不是实际的物理寄存器。从 PTX 指令集到 GPU 物理指令集的这一层抽象解释由优化程序实现。优化程序在 warp 之间划分可用的寄存器,它还会清除死亡代码,将指令打包在一起,并计算分支发生发散的位置和发散路径可能会聚的位置。
之所以要使用 PTX 指令集,而不是直接使用物理指令集,是为了解决软硬件工程中挥之不去的兼容性问题。PTX 的存在为编译器提供了一种稳定的指令集,可以实现各代GPU 之间的兼容性。不同的 GPU 只需要适配相应的优化程序即可实现代码兼容,这就给了 GPU 硬件非常大的变化空间。
PTX 抽象指令集的这一思想可以类比于 x86微体系结构。众所周知,Intel 为了实现当代内核指令对以往版本内核代码的兼容,在硬件上做了一个解释层,将复杂指令翻译成一组微指令,然后再进行真正的指令译码操作。它们的区别在于:x86 的这一转换是在运行时以硬件方式实现,而 PTX 指令转换为物理指令是在载入时以软件实现的。
延迟优化 & 吞吐量优化
在研究计算机体系结构时,延迟和吞吐量是经常会被提及的两个指标。「延迟」表示从发出一条指令/请求,到得到结果所经历的时间;「吞吐量」表示单位时间内,完成的指令/请求数。
绝大部分的CPU 为了通用和低延迟做了更多优化,我们称之为基于延迟优化的处理器。GPU为了高并发、高流水牺牲了通用性和延迟,我们称之为基于吞吐量优化的处理器。
GPU 依赖于流式多处理器中的硬件多线程以隐藏访存延时,但这并不意味着延迟不存在。例如,流式多处理器中的某个 warp 发起外部 DRAM 访问,由于没有缓存支持,这一访问结果可能需要几十个 cycle 后才能有效,于是该 warp 只能选择等待,但在它等待的间隙,warp 调度器将执行处理器内的其它线程。尽管单个线程的访存发生大量的延迟,但从流式多处理器整体而言,它的吞吐量还是很大。
基于延迟还是吞吐量来优化计算机系统并没有一个绝对的优劣标准,而是从计算机系统的应用场景出发来考量。拿 GPU 的主要工作图形处理来讲,一般的图形都是以几十帧每秒的速率切换,因此 GPU 只需要以 ms 级的速率完成一幅图像内容的处理即可满足要求,这时候单个线程的延迟就显得无关紧要了。
有一点值得注意的是:低延迟不意味着低吞吐量;高吞吐量也不意味着高延迟。延迟与吞吐量之间也没有绝对的限制关系。一个计算机系统它可以是低延迟的同时,具备高的吞储量。
参考资料
【1】John L. Hennessy,David A. Patterson . 计算机体系结构:量化研究方法:第5版[M].北京:人民邮电出版社,2013. (原名《Computer Architecture:A Quantitative Approach》)
【2】David A. Patterson,John L. Hennessy . 计算机组成与设计:硬件/软件接口:第5版[M].北京:机械工业出版社,2015. (原名《Computer Organization and Design:The Hardware/Software Interface》)
·END·
你可能还感兴趣:
欢迎来我的微信公众号做客:信号君
专注于信号处理知识、高性能计算、现代处理器&计算机体系
技术成长 | 读书笔记 | 认知升级

幸会~
![]()
SIMD数据并行(三)——图形处理单元(GPU)的更多相关文章
- SIMD数据并行(四)——三种结构的比较
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
- SIMD数据并行(二)——多媒体SIMD扩展指令集
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
- SIMD数据并行(一)——向量体系结构
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
- 【深度学习系列2】Mariana DNN多GPU数据并行框架
[深度学习系列2]Mariana DNN多GPU数据并行框架 本文是腾讯深度学习系列文章的第二篇,聚焦于腾讯深度学习平台Mariana中深度神经网络DNN的多GPU数据并行框架. 深度神经网络( ...
- 深度神经网络DNN的多GPU数据并行框架 及其在语音识别的应用
深度神经网络(Deep Neural Networks, 简称DNN)是近年来机器学习领域中的研究热点,产生了广泛的应用.DNN具有深层结构.数千万参数需要学习,导致训练非常耗时.GPU有强大的计算能 ...
- 第三篇:GPU 并行编程的运算架构
前言 GPU 是如何实现并行的?它实现的方式较之 CPU 的多线程又有什么分别? 本文将做一个较为细致的分析. GPU 并行计算架构 GPU 并行编程的核心在于线程,一个线程就是程序中的一个单一指令流 ...
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
[源码解析] PyTorch分布式优化器(2)----数据并行优化器 目录 [源码解析] PyTorch分布式优化器(2)----数据并行优化器 0x00 摘要 0x01 前文回顾 0x02 DP 之 ...
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
- C#并行编程-PLINQ:声明式数据并行
目录 C#并行编程-相关概念 C#并行编程-Parallel C#并行编程-Task C#并行编程-并发集合 C#并行编程-线程同步原语 C#并行编程-PLINQ:声明式数据并行 背景 通过LINQ可 ...
随机推荐
- Selenium2学习(十七)-- js处理日历控件(修改readonly属性)
前言 日历控件是web网站上经常会遇到的一个场景,有些输入框是可以直接输入日期的,有些不能,以我们经常抢票的12306网站为例,详细讲解如何解决日历控件为readonly属性的问题. 基本思路:先用j ...
- Linux中基于apache httpd的svn服务器搭建与配置
mod_dav_svn是apache连接svn的模块 yum install subversion mod_dav_svn httpd 配置文件简单说明, SVNParentPath 说明可以在指定的 ...
- VSCode cpptools 插件在Centos 7下不能正确显示符号列表的解决办法
vscode 的插件cpptools 0.9.3 需要glibc 2.18的版本,但是Centos 7 下没有这个版本的GLIBC,所以导致链接库丢失,后台服务不能正常运行.按以下步骤操作可修复此问题 ...
- MAVEN本地下载、安装
1. 安装jdk (此处版本选择1.7以上) 此处不做安装说明!!! 2.Eclipse.配置及安装 此处不做安装说明!!! 3.maven安装包(此处选择apache-maven-3.5.2-bin ...
- (转)Wireshark基本介绍和学习TCP三次握手
原地址https://www.cnblogs.com/TankXiao/archive/2012/10/10/2711777.html#filter 阅读目录 wireshark介绍 wireshar ...
- React中的虚拟DOM
当组件当state和props发生变化当时候,组件当render函数就会重新执行,组件就会被重新渲染,react中实现这种重新渲染,他的性能是非常高的,因为他引入了一个虚拟Dom的概念,那么什么是虚拟 ...
- 2018.11.10 Mac设置Eclipse的 .m2文件夹是否可见操作&&Mac系统显示当前文件夹的路径设置
第一行就是设置为可见的记得要重启Finder不然是没有效果的 第二行就是设置为不可见的 打开"终端"(应用程序->实用工具),输入以下两条命令: defaults write ...
- Linux云主机 监控方案浅析
1.为何需要监控 监控是运维工程师的眼睛,它可帮助运维工程师第一时间发现系统的问题. 对于服务器的整个生命周期,都要和监控打交道: 当有服务器上架,都需要加入比如CPU负载.内存.网络.磁盘等基础监控 ...
- TemplateSyntaxError at /article/list-article-titles/admin/
如图红圈所示,发现一个注释掉的{% if userinfo %}标签竟然可以影响后面的标签快,不能注释,需要完全删除才不会报错. 继续这类django在html模板中直接注释掉发生错误以及解决方案: ...
- SpringMVC学习记录六——异常定义和上传图片
19 异常处理 19.1 异常处理思路 系统中异常包括两类:预期异常和运行时异常RuntimeException,前者通过捕获异常从而获取异常信息,后者主要通过规范代码开发.测试 ...