基于物理文件的HBase备份还原
前提说明:
1、HBase数据分表,所以备份的粒度是表。
2、备份的内容为Azure的Blob存储。
HBase Blob备份
备份时,需要先将表disable,以保持数据一致性。
备份的工具可以用Azcopy,或者Azure Client等。各种工具另一篇单独介绍。其它没什么可说的。
备份完成后,相应的表可以drop或进行其它操作。
HBase Blob还原
HBase中之前不存在该表(或者之前删除的很干净)
这种场景下,还原比较容易。步骤如下。
1、将数据所在的Folder(以表名为文件夹名)复制到存储账号/容器/hbase/data/default目录下。Folder对应的同名Blob文件(记录权限等属性)不需要复制。
2、在HBase中执行数据恢复的命令(TaskLog为表名):
hbase hbck -repair 'TaskLog' -ignorePreCheckPermission -fixMeta
3、scan 'TaskLog' 查看还原的结果。
遇到的问题及解决方案
通过Azcopy复制过来的文件可以恢复,但是通过AzureClient API复制过来的文件在进行恢复时报错:
[main] util.HBaseFsck: Unable to read .tableinfo from wasb://hdptestjn@hdptestjn.blob.core.chinacloudapi.cn/hbase
org.apache.hadoop.hbase.TableInfoMissingException: No table descriptor file under wasb://hdptestjn@hdptestjn.blob.core.chinacloudapi.cn/hbase/data/default/CM_EvcRegisterBatteryInfo
at org.apache.hadoop.hbase.util.FSTableDescriptors.getTableDescriptorFromFs(FSTableDescriptors.java:513)
at org.apache.hadoop.hbase.util.FSTableDescriptors.getTableDescriptorFromFs(FSTableDescriptors.java:500)
at org.apache.hadoop.hbase.util.FSTableDescriptors.getTableDescriptorFromFs(FSTableDescriptors.java:480)
at org.apache.hadoop.hbase.util.HBaseFsck.loadHdfsRegionInfos(HBaseFsck.java:1182)
at org.apache.hadoop.hbase.util.HBaseFsck.onlineConsistencyRepair(HBaseFsck.java:660)
at org.apache.hadoop.hbase.util.HBaseFsck.onlineHbck(HBaseFsck.java:697)
at org.apache.hadoop.hbase.util.HBaseFsck.exec(HBaseFsck.java:4751)
at org.apache.hadoop.hbase.util.HBaseFsck$HBaseFsckTool.run(HBaseFsck.java:4552)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
at org.apache.hadoop.hbase.util.HBaseFsck.main(HBaseFsck.java:4540)
报错原因:通过AzureClient API复制文件时,把权限给搞丢了。
正常的权限信息如下:
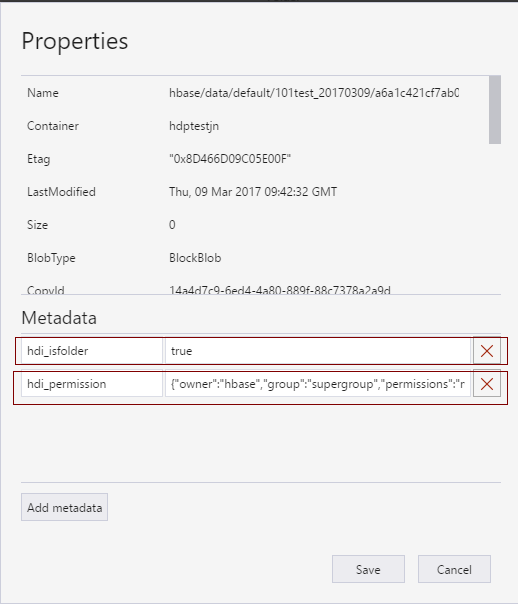
文件夹(对应的blob)的属性有两个:hdi_isfolder=true,hdi_permission={"owner":"hdp","group":"supergroup","permissions":"rwxr-xr-x"}
文件的属性有一个:hdi_permission={"owner":"hdp","group":"supergroup","permissions":"rw-r--r--"}
解决方案:通过AzureClient API复制文件时,添加以上权限信息。注意owner和group要修改成目标HBase所有Linux系统的实际用户和组。
另外,通过Azcopy复制文件时,权限信息带过来了,但owner和group仍旧是源文件的属性。如果源和目标的用户/组不一致时,会产生权限的问题,需要注意。
HBase中之前存在该表(或者之前删除的不彻底)
HBase如果已经存在该表,或曾经存在过而元数据清理不彻底,则在恢复时可能会出错。
所以,下面是清理元数据的方案。清理完毕后,再采用上面的方案进行恢复即可。
1、查看HDFS文件,是否存在相应的目录,如果有,则删除:
hdfs dfs -rmr /hbase/data/default/TaskLog
2、查看zookeeper中是否还有元数据 的残留,如果有,则删除:
1)进入zookeeper的bin目录,如: /usr/hdp/2.5.0.0-1245/zookeeper/bin/
2)连接某一个zookeeper节点,如,执行:./zkCli.sh -server 10.0.0.13:2181
3)查看目录(ls /hbase-unsecure/table)下是否存在表TaskLog,如果有,则删除,即执行命令:
rmr /hbase-unsecure/table/TaskLog
3、重新修复HBase的表结构,执行命令:
hbase hbck -ignorePreCheckPermission -fixMeta
4、清理完毕后,即可进行还原操作。
基于物理文件的HBase备份还原的更多相关文章
- HBase备份还原OpenTSDB数据之Snapshot
前言 本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,想了解前因后果的可以看上一篇和上上篇. opentsdb在hbase中生成4个表(tsdb, tsdb- ...
- HBase备份还原OpenTSDB数据之Export/Import(增量+全量)
前言 本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,文章链接:https://www.cnblogs.com/yybrhr/p/11128149.html, ...
- mongoDB整个文件夹拷贝备份还原的坑
现网有一个mongoDB数据库需要搬迁到新服务器,开发那边的要求是先搬迁现在的数据库过去,然后剩下的以后他们用程序同步. 数据库大楷20G左右,现网是主备仲裁的,停掉备点,拷贝了全部文件. 新服务器也 ...
- 基于xtrabackup实现mysql备份还原
简介 Xtrabackup2.2版之前包括4个可执行文件: innobackupex: Perl 脚本 xtrabackup: C/C++ 编译的二进制 xbstream: 支持并发写的流文件格式 x ...
- (4.16)mysql备份还原——物理备份之XtraBackup实践
关键词:XtraBackup实践,物理备份,xtrabackup备份,innobackupex备份 [1]如何使用? [3]系列:innobackupex --help |more [4]系列:xtr ...
- MySQL数据库备份还原(基于binlog的增量备份)
MySQL数据库备份还原(基于binlog的增量备份) 一.简介 1.增量备份 增量备份 是指在一次全备份或上一次增量备份后,以后每次的备份只需备份与前一次相比增加或者被修改的文件.这就意味 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- 文件操作 系统备份和还原,压缩,解压 tar dump/restore
基本操作命令: ls -a 显示指定目录下的目录和文件,包括隐藏的文件和目录 ls -l 将文件和目录详细列出来,包括文件状态,权限,拥有者,文件名,文件大小等 改变工作目录命令 cd cd .. 进 ...
- SQL Server 数据库备份还原和数据恢复
认识数据库备份和事务日志备份 数据库备份与日志备份是数据库维护的日常工作,备份的目的是在于当数据库出现故障或者遭到破坏时可以根据备份的数据库及事务日志文件还原到最近的时间点将损失降到最低点. 数据 ...
随机推荐
- Java相关脚本
本人摘自:https://github.com/oldratlee/useful-scripts/blob/master/docs/java.md#beer-show-busy-java-thread ...
- poj 3104 dring 二分
Drying Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 7684 Accepted: 1967 Descriptio ...
- 《JavaWeb从入门到改行》很好的复习资料: SQL语句到底怎么写 ?
本文用到的数据库如下: CREATE DATABASE exam; /创建部门表/ CREATE TABLE dept( deptno INT PRIMARY KEY, dname ), loc ) ...
- C#与.NET的区别和C#程序结构
C#语言及其特点 (1)语法简洁,不允许直接操作做内存,去掉指针操作 (2)彻底的面向对象设计,C#具有面向对象所应用的一切特性:封装.继承.多态 (3)与Web紧密结合,C#支持绝大多数的Web标准 ...
- BZOJ5068: 友好的生物(状压 贪心)
题意 题目链接 Sol 又是一道神仙题??.. 把绝对值拆开之后状压前面的符号?.. 下界显然,但是上界为啥是对的呀qwq.. #include<bits/stdc++.h> using ...
- Java设计模式—工厂方法模式&抽象工厂模式
工厂方法模式与抽象工厂模式都是设计模式中重要而且常见的模式. 工厂方法模式:定义一个用于创建对象的接口,让子类决定实例化哪一个类.工厂方法使一个类的实例化延迟到其子类. 通用类图如下: 在 ...
- Teamviewer 手机端怎么使用右键-已解决
Teamviewer 手机端怎么使用右键 可能很多人和我一样,关掉了那个提示,然后记不住操作 怎么控制电脑使用右键? 长按就可以了 拖到指定地点,然后长按不送,就会出来电脑右键菜单
- mac下安装elasticsearch报错Exception BindTransportException[Failed to bind to [9300-9400]]
解决办法:进入 config目录下 修改 vim elasticsearch.xml network.host设置为 0.0.0.0 即可外网访问.
- Java基础之StringBuffer和StringBuilder的区别
StringBuffer是一个字符串的缓存类,属于一个容器,对于容器,我们可以进行增删改查. StringBuffer的容器长度是可变的,并且里面可以存放多种的数据类型.它跟其他容器,比如数组,是很不 ...
- 网络虚拟化技术 -- LXC TUN/TAP MACVLAN MACVTAP
Linux的网络虚拟化是LXC项目中的一个子项目,LXC包括文件系统虚拟化,进程空间虚拟化,用户虚拟化,网络虚拟化,等等 [ LXC内核命名空间 ],这里使用LXC的网络虚拟化来模拟多个网络环境. 创 ...