索引原理 B tree
数据库原理之-索引
背景介绍:
用数据库的时候经常有几个疑问:
1:为啥通过加索引就能提升数据的查询料率?
2:为啥加多了索引会导致增删改的效率变低?
3:为啥有的人能用好有的人用不好?
这些问题我们可能不一定能说出答案。知道这些问题的答案有什么好处呢?如果开发的应用使用的数据库表中只有1万条数据,那么了解与不了解真的没有差别, 然而, 如果开发的应用有几百上千万甚至亿级别的数据,那么不深入了解索引的原理, 写出来程序就根本跑不动,就好比如果给货车装个轿车的引擎,这货车还能拉的动货吗?
这其中很重要的一点就是我们使用的数据库的结构是:关系型数据库。
索引是什么:
用一个很简单很让人无语的解释是:索引对于数据库就像是目录对于新华字典。想从一新华字典里找到一个字的释义最快的方式就是通过目录去寻找对应的页码,而想从数据库里找到对应的数据最快的方式是通过索引。
索引的原理:
想要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree。当然, 有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。
聚集索引:
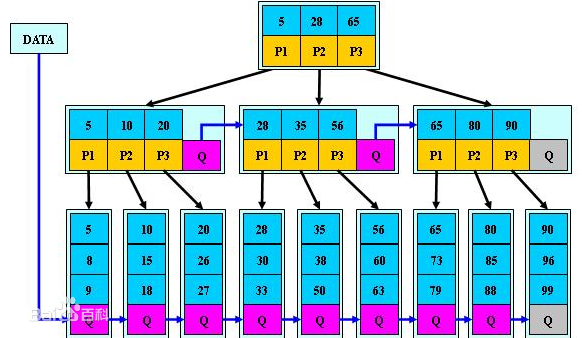
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
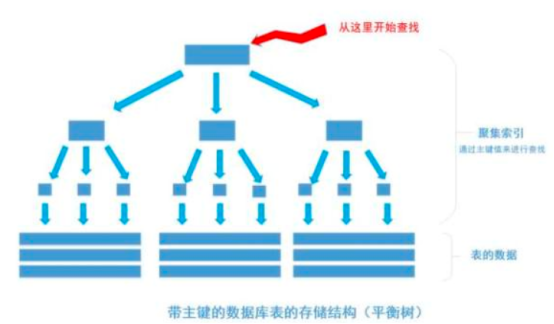
上图就是带有主键的表(聚集索引)的结构图。其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
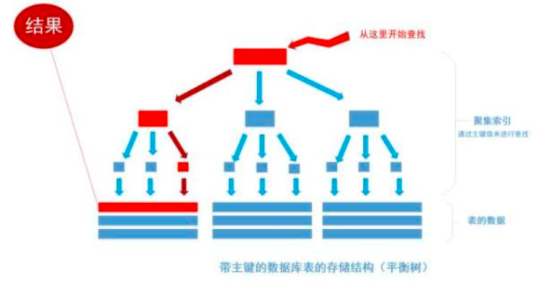
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是

用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
为什么过多使用索引会降低增删改的性能?
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
非聚集索引
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图
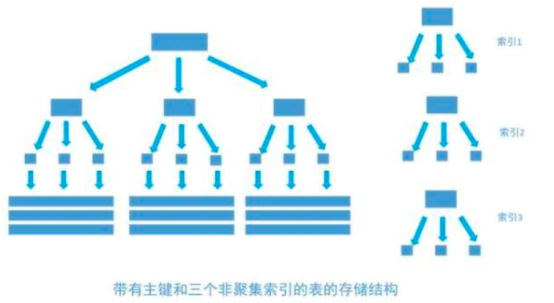
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图
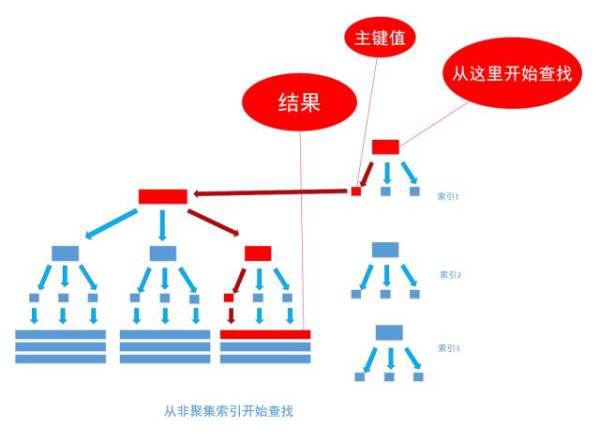
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
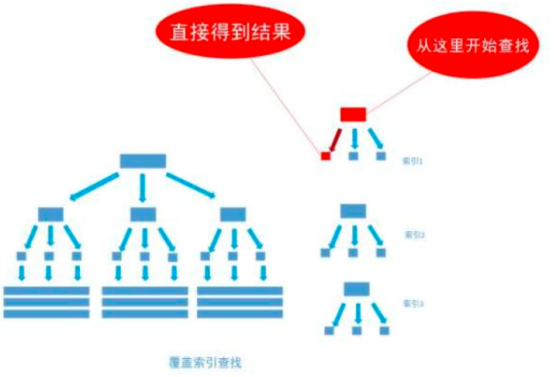
覆盖索引
不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引
create index index_birthday on user_info(birthday);
//查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = '1991-11-1'
这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图
在了解数据库索引之前,首先了解一下数据库索引的数据结构基础,B+tree
B+tree 是一个n叉树,每个节点有多个叶子节点,一颗B+树包含根节点,内部节点,叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上叶子节点的节点。
B+tree的性质:
1.n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
B+tree结构原型图大概如下(引用):
索引原理 B tree的更多相关文章
- B-tree&B+tree&数据库索引原理
B-tree&B+tree:https://www.cnblogs.com/vianzhang/p/7922426.html 数据库索引原理:https://www.cnblogs.com/a ...
- MYSQL之B+TREE索引原理
1.什么是索引? 索引:加速查询的数据结构. 2.索引常见数据结构 顺序查找: 最基本的查询算法-复杂度O(n),大数据量此算法效率糟糕. 二叉树查找:(binary tree search): O( ...
- MySQL之索引原理和慢查询优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- Mysql索引机制(B+Tree)
1,索引谁实现的: 索引是搜索引擎去实现的,在建立表的时候都会指定,搜索引擎是一种插拔式的,根据自己的选择去决定使用哪一个. 2,索引的定义: 索引是为了加速对表中数据行的检索而创建的一种分散存储的( ...
- 知识点:Mysql 索引原理完全手册(1)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) Mysql-索引原理完全手 ...
- MySQL之索引原理
--------------------------------------------------------------------------------堕落的状态,无疑是慢性自杀.想想自己为什 ...
- MySQL 深入浅出数据库索引原理(转)
本文转自:https://www.cnblogs.com/aspwebchh/p/6652855.html 前段时间,公司一个新上线的网站出现页面响应速度缓慢的问题, 一位负责这个项目的但并不是搞技术 ...
- MySQL索引原理及优化
一.各种数据结构介绍 这一小节结合哈希表.完全平衡二叉树.B树以及B+树的优缺点来介绍为什么选择B+树. 假如有这么一张表(表名:sanguo): (1)Hash索引 对name字段建立哈希索引: 根 ...
- 【Important】数据库索引原理
为什么要给表加上主键? 为什么加索引后会使查询变快? 为什么加索引后会使写入.修改.删除变慢? 什么情况下要同时在两个字段上建索引? 想理解索引原理必须清楚一种数据结构(平衡树非二叉)也就是b tre ...
随机推荐
- win7控制面板一打开就停止的解决方法
现象:win7系统,打开控制面板后,弹出提示窗口:资源管理器停止工作,需要重启.点重启后,系统自动重建桌面进程.控制面板根本无法使用. 下面是网上找到的方法,如果都不行再参照后面我的解决方法. 1. ...
- StarRTC , AndroidThings , 树莓派小车,公网环境,视频遥控(一)准备工作
原文地址:http://blog.starrtc.com/?p=48 啥也不说,先来个视频看看效果 视频播放器 00:00 00:54 概述为了体现StarRTC的实时音视频传输能 ...
- Laravel Debugbar
Installation Require this package with composer: composer require barryvdh/laravel-debugbar After up ...
- 关于在Android中Activity页面跳转的方法
一.无返回结果的页面跳转 1.创建两个类FActivity.java和SActivity.java 2.创建两个layout目录下的factivity.xml和sactivity.xml 3.在And ...
- Linux之查看文件大小和数目
1.查看当前文件大小du -sh ./ du [-abcDhHklmsSx] [-L <符号连接>][-X <文件>][--block-size][--exclude=< ...
- Spring 4 官方文档学习(五)核心技术之SpEL
题外话 官方文档用evaluate这个单词来描述从表达式中获得实际内容的过程.如果直译的话,应该是评估.估值之类的意思.个人以为翻译成解析更易懂,但parse已经是解析了,为了避免冲突,就只好保留了e ...
- e669. 绘制缓冲图像
To draw on a buffered image, create a graphics context on the buffered image. // Create a graphics c ...
- V4L2编程 视频采集-范例
http://linuxtv.org/downloads/legacy/video4linux/API/V4L2_API/v4l2spec/: http://blog.csdn.net/kangear ...
- PHP 5种方式获取文件后缀名
<?php header("content-type:text/html;charset=utf-8"); function get_ext1($filename) { re ...
- 经常使用的CSS Hack技术集锦
来源:http://www.ido321.com/938.html 一.什么是CSS Hack? 不同的浏览器对CSS的解析结果是不同的,因此会导致同样的CSS输出的页面效果不同,这就须要CSS Ha ...