论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言
在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构。本文主要讲解2016-2017年的一些经典CNN结构。
CIFAR和SVHN上,DenseNet-BC优于ResNeXt优于DenseNet优于WRN优于FractalNet优于ResNetv2优于ResNet,具体数据见CIFAR和SVHN在各CNN论文中的结果。ImageNet上,SENet优于DPN优于ResNeXt优于WRN优于ResNet和DenseNet。
WideResNet( WRN )
- motivation:ResNet的跳连接,导致了只有少量的残差块学到了有用信息,或者大部分残差块只能提供少量的信息。于是作者探索一种新的网络WideResNet(在ResNet的基础上减小深度,增加宽度)。
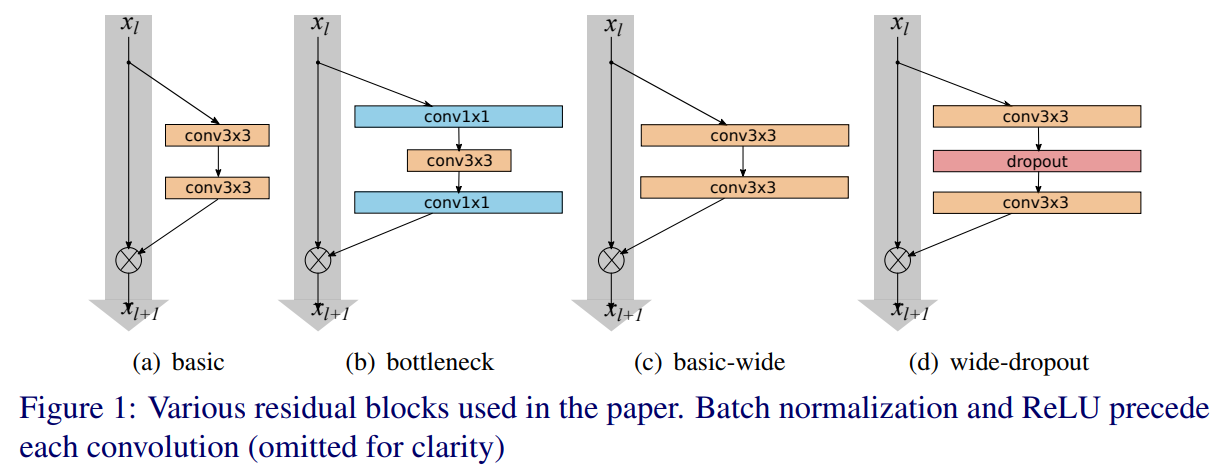
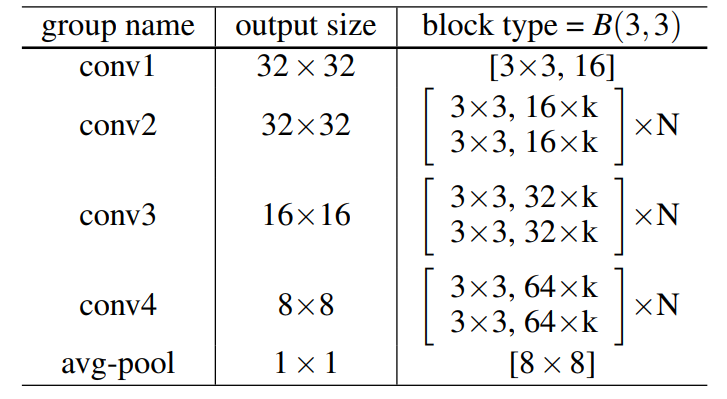
- 网络结构:在ResNetv2的基础上改进,增大每个残差块中的卷积核数量。如下两个图所示。其中B(3,3)表示一个两个3x3卷积,k表示一个宽度因子,当k为1时卷积核个数和ResNetv2相等,k越大网络越宽。另外WRN在卷积层之间加入dropout(下一个卷积层之前的bn和relu之后),如下第一个图的图(d)所示(在ResNetv2中把dropout放在恒等映射中实验发现效果不好于是放弃了dropout)。用WRN-n-k来表示一个网络,n表示卷积层的总数,k表示宽度因子。
- 训练配置:SGD,momentum为0.9,学习率为0.1,权重衰减为0.0005,batch size为128。
- 实验:在CIFAR,SVHN,COCO数据集上取得了state-of-the-art的结果,同时在ImageNet上也表现优秀(比某些ResNet表现好,并没有超越ResNet的最优结果)。作者根据实验结果认为ResNet的主要能力来自于残差块,而深度的效果只是一个补充。
FractalNet
- motivation:WideResNet通过加宽ResNet得到state-of-the-art的表现,推测ResNet的主要能力来自于残差块,深度不是必要的。相比之下,分形网络则是直接认为ResNet中的残差结构也不是必要的,网络的路径长度(有效的梯度传播路径)才是训练深度网络的基本组建。
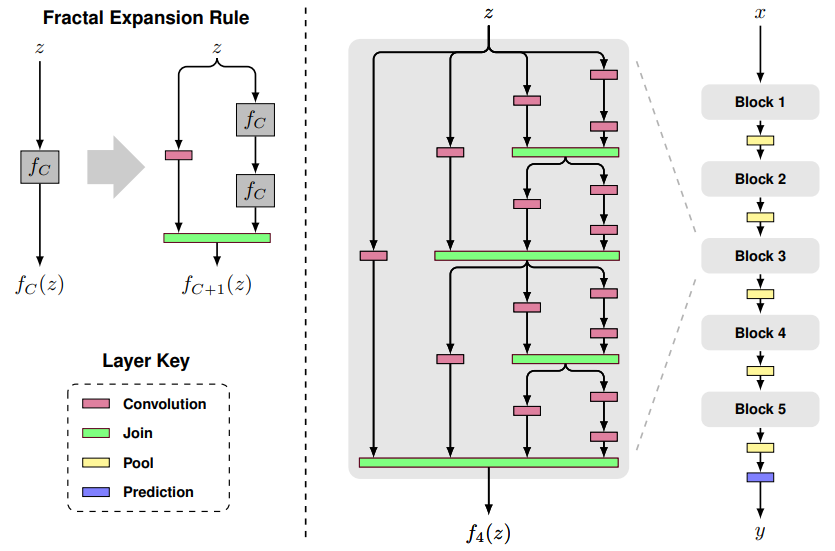
- 网络结构:如下图所示,分形网络是通过不同长度的子路经组合,让网络自身选择合适的子路经集合,另外分形网络还提出了drop paht的方法。其中local drop就是join模块以一定概率drop每个输入,但至少留下一个。global drop就是对整个网络只留下一列。
- 实验:在CIFAR和SVHN数据集上分形网络取得了优秀的结果(CIFAR上可以超越残差网络的表现,但是比WRN的表现差)。在ImageNet上可以达到和ResNet差不多的结果(好那么一丢丢,但是只对比了一种ResNet结构)。
- 更多细节:具体内容我在另一篇论文笔记:分形网络中有所提及。
DenseNet
- motivation之stochastic depth:这是作者黄高之前的一篇论文,因为ResNet中大部分残差块只提供少量信息,所以在ResNet基础上随机丢弃一些层,发现可以提高ResNet的泛化能力。随机丢弃一些层网络依然奏效,带来了两点启发,一是网络中的某一层可以不仅仅依赖于前层特征而依赖于更前层的特征。二是ResNet具有比较明显的冗余,网络的每一层只提取了很少的有用特征。基于以上两点DenseNet提出让网络的每一层和前面的所有层相连,同时把每一层设计地特别窄,学习很少的特征图以此降低冗余性。听起来密集连接似乎会大大增加参数量,但实际上不是,因为网络变窄了。
- motivation之设计捷径:深层网络中,输入的信息或者梯度通过很多层之后会逐渐丢失,之前的ResNet和FractalNet的一个共同特征在于,创建一个前层和后层捷径。沿着这个思路DenseNet让网络的所有层之间做一个全连接,保证所有层之间都两两连接,这么做可以加强feature的传递,更有效地利用feature(每一层可以依赖更前层的特征,每一层的特征都直接连接到输出层),减小梯度消失的问题。另外为了保留信息在连接多个输入时并没有像ResNet一样使用addition,而是使用concat。
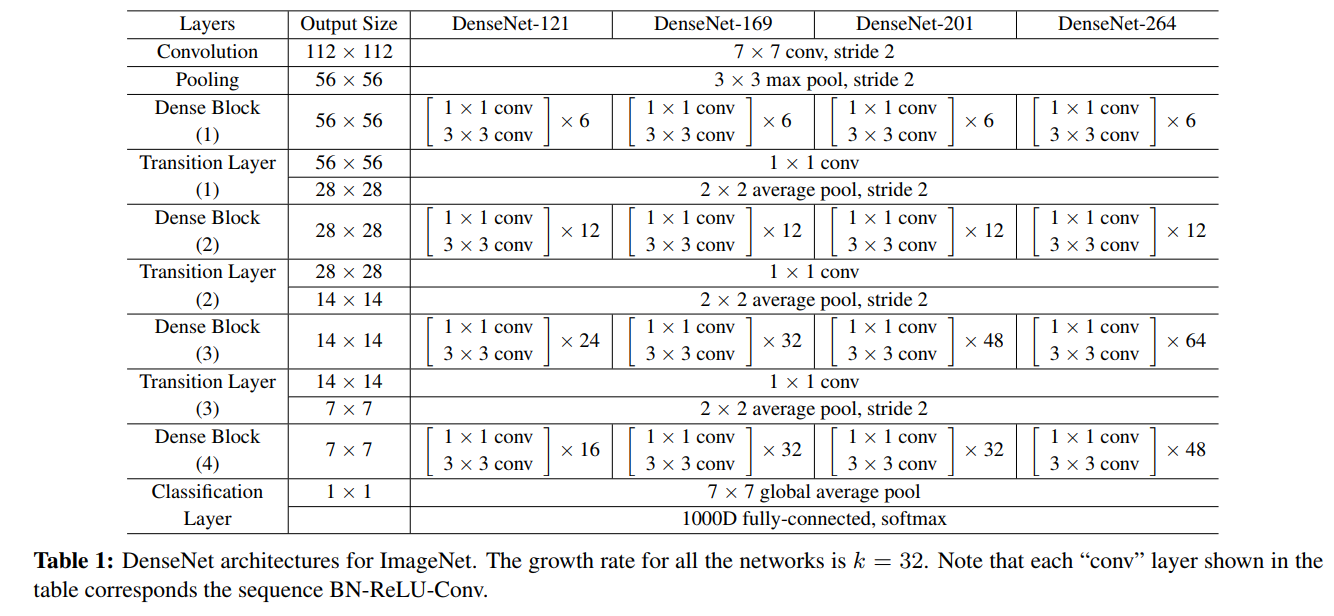
- DenseNet结构:每一层都和所有前层相连接,第一层连输入层有1个前连接,第二层就有2个前连接,那么对于L层就有1+2+...+L也就是L(1+L)/2个连接。因为feature map大小不同的时候concat并不可行,DenseNet把网络分成了几个Dense块,中间用transition layer(用来改变feature map大小)连接起来。如下第一个图所示。Dense块中为多个“BN-ReLU-Conv3x3"(这一连串操作称为一个\(H_l\)的单元操作)。DenseNet的具体结构见论文阐述。
- DenseNet-BC结构:其中B表示bottleneck结构,把3x3替换成(1x1, 3x3),\(H_l\)单元操作为“BN-ReLU-Conv1x1-Conv3x3"。C表示压缩,在transition层设一个参数\(\theta\)来减小feature map个数(通道数),论文中取值为0.5,每次transition时通道数减半。结构如下第二个图所示,其中k表示Dense块中\(H_l\)产生的feature map个数,k越小,Dense块越窄,由于k越大会导致后层concat后通道越大,论文中也称之为growth rate。进入Dense块之前使用了2k个7x7卷积。实验中1x1的卷积产生4k个feature map。
- 实验:在CIFAR和SVHN上超越了前人的表现(超越WRN和FractalNet),在ImageNet上和ResNet达到差不多的表现但参数量不到一半,计算量为ResNet的一半。
- 训练配置:SGD,权重衰减为0.0001,momentum为0.9。CIFAT和SVHN的batch size为64,学习率为0.1,50%和75%的epoch时除以10。在CIFAR上300个epoch,在SVHN上40个epoch。ImageNet上epoch为90,batch size为256,学习率为0.1,在30轮和60轮降为原来的1/10。原生的DenseNet实现对内存的利用效率不高(大量的concat会给显存带来高负荷),作者另外写了一个技术报告来介绍如何提升DenseNet的内存使用效率,同时提供torch,pytorch,mxnet以及caffe的实现。

ResNeXt(2016年ImageNet分类任务的亚军)
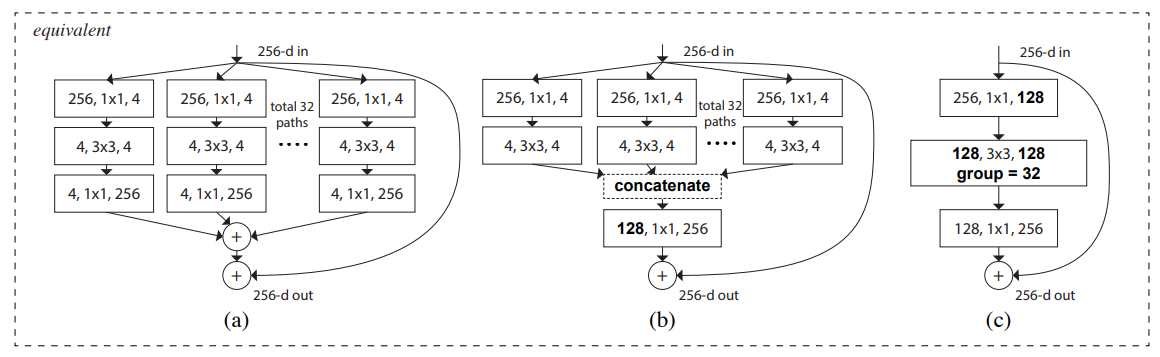
- motivation:视觉识别的研究已经从“人工设计的特征工程”转移到“网络结构设计的网络工程”上。于是作者同时借鉴了VGG和ResNet的“堆叠相同shape子结构”思想和Inception的"split-transform-merge"思想,提出了ResNeXt的结构,把ResNet中残差块的结构改成如下第一个图的图右那种结构,类似Inception块,但是里面的每个小块又是相同的结构,而且最后是addition而不是concat,通过堆叠这样的ResNeXt块来构建ResNeXt网络。
- 网络结构:如下第二个图所示,三个子图的结构是等价的,最后一个子图用了组卷积技术使得结构更加紧凑简洁,模型实现使用的是最后一个子图的结构。BN-Relu的使用遵循的是原始的ResNetv1,在每个卷积后加BN-Relu,到block的输出时(最后一个BN-Relu)把relu放在addition的后面。shortcut都用恒等映射,除了要用映射(projection)增维的时候。
- ImageNet预处理和预测:预处理遵循VGG的做法来裁剪图像,所有消融学习(ablation study)中使用single-crop-224进行预测。
- ImageNet训练配置:SGD,batch size为256,权重衰减为0.0001,momentum为0.9,学习率为0.1,遵循ResNet的实现做三次除以10的衰减,何凯明初始化。
- 实验:实验表示,保持同样的复杂度,增加“cardinality”(这个词下图中有解释,相同于一个ResNeXt块的分支数)可以提高准确率,另外,增加模型容量时,增加“cardinality”比增加深度或宽度更加有效。101-layer ResNeXt准确率比ResNet-200更高,同时花费一半的复杂度(Flops)。

DPN(2017年ImageNet定位任务的冠军)
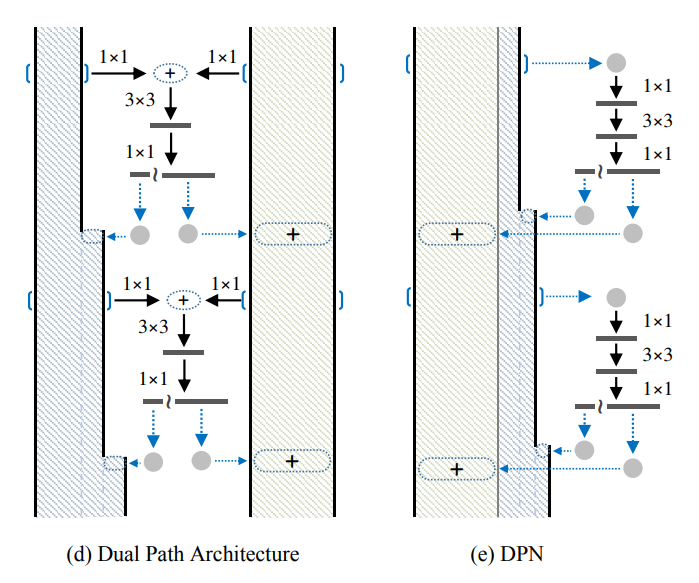
- motivation:结合ResNet的优点(重用特征)和DenseNet的优点(在重用特征上存在冗余,但是利于探索新特征),提出一种新的网络结构,称为对偶路径网络(Dual Path Network)。
- 网络结构:如下图所示,d和e等价,网络分为residual path和densely connected path在卷积块最后的1x1将输出切为两路,一路连到residual path上加起来,一路练到densely connected path上concat起来。
- 实验:ImageNet(分类)上表现超过ResNeXt,而且模型更小,计算复杂度更低。另外在VOC 2007的目标检测结果和VOC 2012的语义分割结果也超越了DenseNet,ResNet和ResNeXt。
SENet(2017年ImageNet分类任务的冠军)
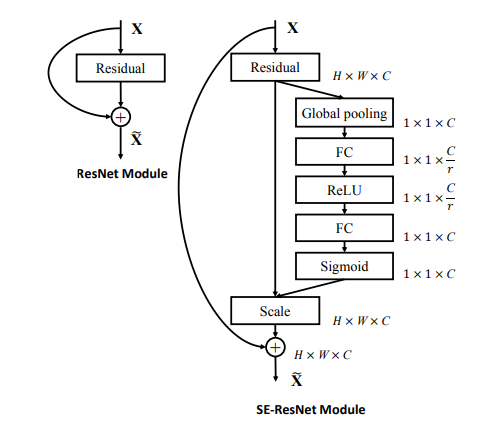
- motivation:已经很多工作在空间维度上提升网络性能,比如Inception嵌入多尺度信息,聚合多种不同感受野上的特征来获得性能增益。那么网络是否可以从其它层面去提升性能,比如考虑特征通道之间的关系,基于这一点作者提出了SENet(Squeeze-and-Excitation Network),通过学习的方式获取每个通道的重要程度,从而进行特征重标定。
- 网络结构:如下第一个图所示,\(F_{tr}\)表示transformation(比如一系列的卷积操作),\(F_{sq}\)表示squeeze操作,产生一个通道描述符,表征特征通道上响应的全局分布。\(F_{ex}\)表示excitation操作,通过参数w来为每个特征通道生成权重,建模特征通道间的重要性。\(F_{scale}\)表示一个reweight操作,将excitation输出的权重(特征通道的重要性)逐个乘到先前的特征,完成特征重标定。
- SE-ResNet模块:如下第二个图是SE嵌入到ResNet中的一个例子,这里使用全局均值池化作为squeeze操作,使用两个FC组成的bottleneck结构作为excitation操作。SE可以嵌入到任意网络中得到不同种类的SENet,比如SE-ReNeXt,SE-BN-Inception,SE-Inception-ResNet-v2等等。
- 训练配置:跟随VGG的标准设定进行数据增强。输入图像使用通道均值相减。使用了数据平衡策略用于mini-batch采样(这个策略引用于另一篇论文Relay bp for effective learning of deep cnn)。SGD,momentum为0.9,mini-batch为1024,学习率0.6,每30轮除以10,训练100轮,何凯明初始化。预测时使用center crop。
- 实验:ImageNet分类中,在ResNet,ResNeXt,VGG,BN-Inception,Inception-ResNet-v2,mobileNet,shuffleNet上都做了实验,发现加入SE后表现提升。此外还在场景分类和目标检测中做了实验,加入SE后表现提升。

参考文献
- WRN(2016 BMVC):Wide Residual Networks(模型源码-torch实现)
- FractalNet:(2017 ICLR):FractalNet: Ultra-Deep Neural Networks without Residuals(模型源码-caffe实现)
- DenseNet(2017 CVPR):Densely Connected Convolutional Networks(模型源码-torch实现)
- ResNeXt(2017 CVPR):Aggregated Residual Transformations for Deep Neural Networks(模型源码-torch实现)
- DPN(2017 NIPS):Dual Path Networks(模型源码-mxnet实现)
- SENet(2018 CVPR):Squeeze-and-Excitation Networks(模型源码-caffe实现)
论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)的更多相关文章
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- (转载)经典计算机视觉论文笔记——DeepFace\DeepID\DeepID2\DeepID3\FaceNet\VGGFace汇总
1. DeepFace:Closing the Gap to Human-Level Performance in Face Verification 最早将深度学习用于人脸验证的开创性工作.Face ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- 大话CNN经典模型:VGGNet
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC20 ...
随机推荐
- C#中释放数据库连接资源
1.确保释放数据库连接资源的两种方式如下: a.使用try...catch...finally语句块,在finally块中关闭连接: b.使用using语句块,无论如何退出,都会自动关闭连接: ...
- DALSA网口线扫相机SDK开发详解例程(C#版)
首先吐槽一句,官方的demos写的真的不好,坑爹啊.对于小白来说,开发官方demos为我所用太难了.为什么呢?因为它Dalsa的DALSA.SaperaLT.SapClassBasic.dll中,不仅 ...
- 事务传播性、隔离性与MVCC
一.事务传播性 1.1 什么是事务的传播性 事务的传播性一般在事务嵌套时候使用,比如在事务A里面调用了另外一个使用事务的方法,那么这俩个事务是各自作为独立的事务执行提交,还是内层的事务合并到外层的事务 ...
- 第七章 资源在Windows编程中的应用 P157 7-8
资源在基于SDK的程序设计中的应用实验 一.实验目的 1.掌握各种资源的应用及资源应用的程序设计方法. 二.实验内容及步骤 实验任务 1.熟悉菜单资源的创建过程: 2.熟悉位图资源的创建: 3.熟 ...
- Java字符串split分割星号*等特殊字符问题(转)
Java的split()方法分割字符串比较常用(见[Java]字符串以某特殊字符分割处理 ),但在有的时候,会遇到星号*等正则表达式中的特殊字符而无法分割的问题. 比如某需求,用户输入产品规格:厚*宽 ...
- ScrollView中嵌套ListView的问题
网上关于怎样在ScrollView中嵌套ListView的讨论有很多,我大概是搜索了一下,简单总结如下: 1.不要在ScrollView中嵌套ListView a.用一个LinearLayout来代替 ...
- 斜杠反斜杠,去空格\xa0,连接函数join()
1斜杠反斜杠 斜杠:/.反斜杠:\. 反斜杠\,在windows系统中用来表示目录. 而在unix系统中,/表示目录.由于web遵循unix命名,所以在网址(URL)中,/表示目录. 在unix系统中 ...
- marathon的高可用服务自动发现和负载均衡
上一篇我们说谈了docker+zookeeper+mesos+marathon集群,本篇我们来谈谈marathon的集群和自动发现服务. marathon的服务自动发现和负载均衡有两种,1是mesos ...
- 何时使用[self release]
这样的语句 [self release]; 乍看上去让人很困惑. 从release方法本身的作用上来说,就是给self的引用技术减一,就像release对其他对象所做的一样. 一般来说,唯一用到, ...
- MySQL数据库Query性能定位
1.SQL前面加 EXPLAIN 定位到sql级别 各个属性的含义 id select查询的序列号 select_type select查询的类型,主要是区别普通查询和联合查询.子查询之类的复杂查询. ...