C++ 顺序容器原理
容器分为顺序容器与关联容器,顺序容器也称为序列式容器。序列式容器按元素插入的顺序存储元素,这些元素可以进行排序,但未必是有序的。C++本身内置了一个序列式容器array(数组),STL另外提供了vector,list,forward_list,deque,stack,queue,priority-queue,string等等序列式容器。所有的容器都是基于模板实现的,因为容器必须保证能装得下各种各样的类型。其中,stack,queue都是基于deque来实现的,priority-queue基于heap来实现,从技术上来说它们属于容器适配器(adapter)。其中array与forward_list是C++11添加的新容器类型。
1、vector
vector的底层数据结构是动态数组,因此,vector的数据安排以及操作方式与std::array十很相似,它们间的唯一差别在于对空间的运用灵活性上。array为静态数组,有着静态数组最大的缺点:每次只能分配一定大小的存储空间,当有新元素插入时,要经历 “找到更大的内存空间”->“把数据复制到新空间” ->“销毁旧空间” 三部曲, 对于std::array而言,这种空间管理的任务压在使用它的用户身上,用户必须把握好数据的数量,尽量在第一次分配时就给数据分配合理的空间(这有时很难做到),以防止“三部曲”带来的代价,而数据溢出也是静态数组使用者需要注意的问题。而vector用户不需要亲自处理空间运用问题。vector是动态空间,随着新元素的插入,旧存储空间不够用时,vector内部机制会自行扩充空间以容纳新元素,当然,这种空间扩充大部分情况下(几乎是)也逃脱不了“三部曲”,只是不需要用户自己处理,而且vector处理得更加安全高效。vector的实现技术关键就在于对其大小的控制以及重新配置时数据移动效率。
标准库的实现者使用了这样的内存分配策略:以最小的代价连续存储元素。为了使vector容器实现快速的内存分配,其实际分配的容量要比当前所需的空间多一些(预留空间),vector容器预留了这些额外的存储区用于存放添加的新元素,于是不必为每个新元素进行一次内存分配。当继续向容器中加入元素导致备用空间被用光(超过了容量 capacity),此时再加入元素时vector的内存管理机制便会扩充容量至两倍,如果两倍容量仍不足,就扩张至足够大的容量。容量扩张必须经历“重新配置、元素移动、释放原空间”这个浩大的工程。按照《STL源码剖析》中提供的vector源码,vector的内存配置原则为:
- 如果vector原大小为0,则配置1,也即一个元素的大小。
- 如果原大小不为0,则配置原大小的两倍。
当然,vector的每种实现都可以自由地选择自己的内存分配策略,分配多少内存取决于其实现方式,不同的库采用不同的分配策略。
迭代器失效问题
(1)vector管理的是连续的内存空间,在容器中插入(或删除)元素时,插入(或删除)点后面的所有元素都需要向后(或向前)移动一个位置,指向发生移动的元素的迭代器都失效。这里以插入操作示例:
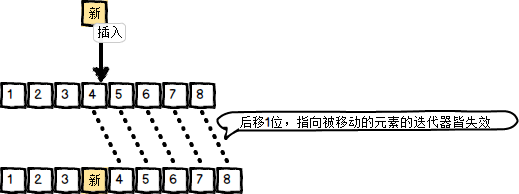
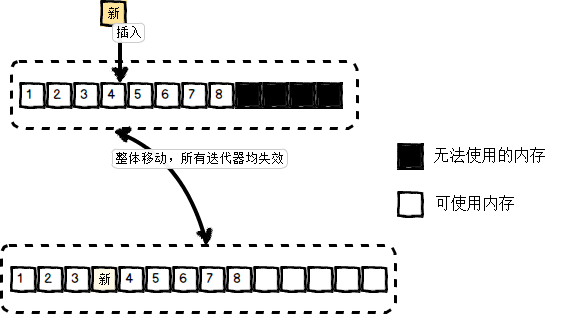
(2)随着元素的插入,原来分配的连续内存空间已经不够且无法在原地拓展新的内存空间,整个容器会被copy到另外一块内存上,此时指向原来容器元素的所有迭代器通通失效。
(3)删除元素后,指向被删除元素的迭代器失效,这是显而易见的。
vector使用优劣
优点:
(1) 不指定一块内存大小的数组的连续存储,即可以像数组一样操作,但可以对此数组进行动态操作。通常体现在push_back() pop_back()
(2) 随机访问方便,即支持[ ]操作符和vector.at()
(3) 节省空间。
缺点:
(1) 在内部进行插入删除操作效率低。
(2) 只能在vector的最后进行push和pop,不能在vector的头进行push和pop。
(3) 当动态添加的数据超过vector默认分配的大小时要进行整体的重新分配、拷贝与释放
2、Array
连续存储结构,每个元素在内存上是连续的
array是一个固定大小的顺序容器,不能动态改变大小,它的大小在定义后就不能被改变。由于array具有固定的大小,它不支持添加和删除元素或改变容器大小等其他容器拥有的操作。在定义一个array容器的时候必须指定大小。
Defined in header :
<array>
template<class T, std::size_t N> struct array;
内存分配策略
在内存分配策略上,array也与C-style数组类似。编译器在哪里为array分配内存,取决于array定义的位置和方式。
- 若作为函数的局部对象,则将从栈上获得内存,与之对比是的vector,vector底层数据结构是动态数组,从自由存储区上分配内存:
- 若使用new操作符分配内存,则是在自由存储区上分配内存。
- 若作为全局变量或局部静态变量,则是在全局/静态存储区上分配的内存。
例如,在函数定义的array局部对象在栈上分配内存,与此对比的是vector,它底层数据结构为动态数组,因此在自由存储区上分配内存:
#include <array>
#include <vector>
#include <iostream> using namespace std; int main() {
int stack_var;
array<int, > a;
vector<int> b(); cout << "stack area: 0x" << hex << (uintptr_t)&stack_var << endl;
cout << "a[3] address: 0x" << hex << (uintptr_t)&a[] << endl;
cout << "b[3] address: 0x" << hex << (uintptr_t)&b[] << endl; getchar();
return ;
} 输出:
stack area:0xd1fbf4
a[] address:0xd1fbe4
b[] address:0x10ab10c
Array使用优劣
(1)array比数组更安全。它提供了opeartor[]与at()成员函数,后者将进行数组越界检查。
(2)与其他容器相似,array也有自己的迭代器,因此array能够更好地与标准算法库结合起来。
(3)通过array::swap函数,可以实现线性时间内的两个数组内容的交换。
另外,不像C-style数组,array容器类型的名称不会自动转换为指针。对于C++程序员来说,array要比C-style数组更好用。
3、deque
底层数据结构
vector是单向开口的线性连续空间,deque则是一种双向开口的连续数据空间。所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作。当然vector也可以在头尾两端进行操作,但是其头部操作效果奇差,所以标准库没有为vector提供push_front或pop_front操作。与vector类似,deque支持元素的快速随机访问。deque的示意图如下:
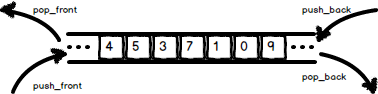
现在问题来了:如果deque以数组来实现,如何做到在头部的常数时间插入?如果是采用链表来实现,又如何做到快速随机访问?deque的内部数据结构到底如何?想必你已经猜到了,要实现如上需求,需要由一段一段的连续空间链接起来的数据结构才能满足。
内存分配策略
接着上面讲。deque由一段一段的连续空间所链接而成,一旦需要在deque的前端或尾端增加新空间,便配置一段定量的连续空间,并将该空间串接在deque的头部或尾部。deque复杂的迭代器架构,构建出了所有分段连续空间”整体连续“的假象。
既然deque是由一段一段定长的连续空间所构成,就需要有结构来管理这些连续空间。deque采用一块map(非STL中的map)作为主控,map是一块小的连续空间,其中每个元素都是指针,指向一块较大的线性连续空间,称为缓冲区。而缓冲区才是存储deque元素的空间主体。示例图: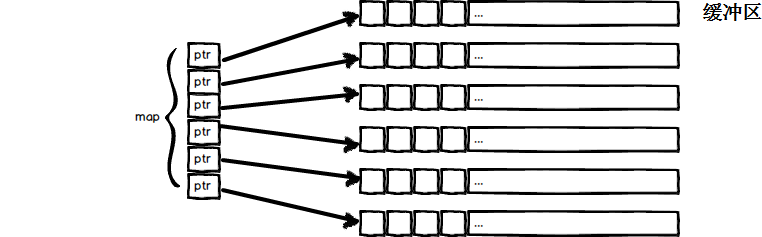
map本身也是一块固定大小的连续空间,当缓冲区数量增多,map容不下更多的指针时,deque会寻找一块新的空间来作为map。
deque的迭代器
为了使得这些分段的连续空间看起来像是一个整体,deque的迭代器必须有这样的能力:它必须能够指出分段连续空间在哪里,判断自己所指的位置���否位于某一个缓冲区的边缘,如果位于边缘,则执行operator-- 或operator++时要能够自动跳到下一个缓冲区。因此,尽管deque的迭代器也是Ramdon Access Iterator 迭代器,但它的实现要比vector的复杂太多。SGI版本的STL deque实现思路可以看侯捷的《STL源码剖析》。
迭代器失效问题
(1)在deque容器首部或者尾部插入元素不会使得任何迭代器失效。
(2)在其首部或尾部删除元素则只会使指向被删除元素的迭代器失效。
(3)在deque容器的任何其他位置的插入和删除操作将使指向该容器元素的所有迭代器失效。
deque使用优劣
deque是在功能上合并了vector和list。
优点:(1) 随机访问方便,即支持[ ]操作符和vector.at()
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:(1) 占用内存多
4、list
底层数据结构
list同样是一个模板类,它底层数据结构为双向循环链表。因此,它支持任意位置常数时间的插入/删除操作,不支持快速随机访问。
迭代器类型
list的迭代器具备前移、后移的能力,所以list提供的是Bidirectional iterator(双向迭代器)。由于采用的是双向迭代器,自然也很方便在指定元素之前插入新节点,所以list很正常地提供了insert()操作与push_back()/pop_back()操作。在C++11中,list新增了三个接口,以支持在指定位置构造对象后插入容器中:
| 接口(C++11新增) | 描述 |
|---|---|
| emplace | 在指定位置之前插入新构造的元素 |
| emplace_front | 在链表头插入新构造的元素 |
| emplace_back | 在链表尾插入新构造的元素 |
内存分配策略
list的空间配置策略,自然是像我们普通双向链表那样,有多少元素申请多少内存。它不像vector那样需要预留空间供新元素的分配,也不会因找不到连续的空间而引起整个容器的内存迁移。
迭代器失效问题
list 有一个重要性质:插入操作(insert)与接合操作(splice)都不会造成原有的list迭代器失效。这在vector是不成立的,因为vactor的插入可能引起空间的重新配置,导致原来的迭代器全部失效。list的迭代器失效,只会出现在删除的时候,指向删除元素的那个迭代器在删除后失效。
通常来说,forward_list在使用灵活度上比不上list,因为它只能单向迭代元素,且提供的接口没有list多。然而,在内存的使用上,它是比list占优势的。当对内存的要求占首要位置时,应该选择forward_list。
list使用优劣
优点:
(1) 不使用连续内存完成动态操作。
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:
(1) 不能进行内部的随机访问,即不支持[ ]操作符和vector.at()
(2) 相对于verctor占用内存多
4、容器适配器
stack,也称为栈,是一种先进后出的数据结构。STL中的statck是一种容器适配器。所谓的容器适配器,是以某种容器作为底部容器,在底部容器之上修改接口,形成另一种风貌。stack默认以双端队列deque作为底部容器。stack没有提供迭代器,通过push/pop接口对栈顶元素进行操作。
queue,也称为队列,是一种先进先出的数据结构,它同样也是一种容器适配器。它的底部容器默认为deque。同样,queue也没有提供迭代器,通过push向队尾压入元素,pop从队首弹出元素。
priority-queue,优先队列,是一种拥有权值观念的队列,例如在以整数大小作为衡量的权值定义下,priority-queue总是弹出最大的数。priority-queue的底部数据结构默认是max-heap,大顶堆。
使用区别:
1)如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
2)如果你需要大量的插入和删除,而不关心随机存取,则应使用list
3)如果你需要随机存取,而且关心两端数据的插入和删除,则应使用deque
4)如果知道数据的多少,并且不会改变,则使用array
总结:
| 容器 | 底层数据结构 | 元素访问方式 | 插入或删除元素效率 | 迭代器失效情况 |
|---|---|---|---|---|
| array | 固定大小的数组 | 支持快速随机访问 | 不能添加或删除元素 | 通常不会发生迭代器失效,除非对象已经被销毁,则原来的迭代器全部失效 |
| vector | 可动态增长的数组 | 支持快速随机访问 | 尾部可高效插入/删除元素 | 若插入操作引起内存重新分配,则全部迭代器失效;否则插入点/删除点之后的迭代器失效; |
| list | 双向链表 | 只支持元素的双向顺序访问 | 在list的任何位置可高效插入/删除元素 | 插入操作后指向容器的迭代器有效;删除操作指向其他位置的迭代器有效 |
| deque | 双端队列 | 支持快速随机访问 | 首尾可高效插入/删除元素 | 情况较多,见上面分析 |
| forward_list | 单向链表 | 只支持元素的单向顺序访问 | 在链表的任何位置可高效插入/删除元素 | 插入操作后指向容器的迭代器有效;删除操作指向其他位置的迭代器有效 |
| string | 只存储字符元素的动态数组 | 支持快速随机访问 | 尾部可高效插入/删除元素 | 若插入操作引起内存重新分配,则全部迭代器失效;否则插入点/删除点之后的迭代器失效; |
| stack | 默认deque | 先进后出,只能访问栈顶元素 | ---- | 没有迭代器 |
| queue | 默认deque | 先进先出,只能访问队首元素 | ---- | 没有迭代器 |
| priority-queue | 默认max-heap | 先进先出,只能访问队首元素 | ---- | 没有迭代器 |
注意:
- “尾部可高效插入/删除元素”,意味着在除了尾部之外的其他位置插入/删除元素是较低效的。
- “顺序访问”意味着要访问某一个元素,必须遍历其他元素。
- 迭代器失效意味着指针、引用在同样的情况下也会失效。
C++ 顺序容器原理的更多相关文章
- 转 Spring源码剖析——核心IOC容器原理
Spring源码剖析——核心IOC容器原理 2016年08月05日 15:06:16 阅读数:8312 标签: spring源码ioc编程bean 更多 个人分类: Java https://blog ...
- C++ 顺序容器基础知识总结
0.前言 本文简单地总结了STL的顺序容器的知识点.文中并不涉及具体的实现技巧,对于细节的东西也没有提及.一来不同的标准库有着不同的实现,二来关于具体实现<STL源码剖析>已经展示得全面细 ...
- c++ 顺序容器学习
所谓容器,就是一个装东西的盒子,在c++中,我们把装的东西叫做“元素” 而顺序容器,就是说这些东西是有顺序的,你装进去是什么顺序,它们在里面就是什么顺序. c++中的顺序容器一共有这么几种: vect ...
- C++ Primer 第九章 顺序容器
由于书籍上写的已经很经典了,故大部分用图片的形式来阐述概念,代码纯手打进行验证. 1.顺序容器类型:vector.deque.list.forword_list.array.string. 2.顺序容 ...
- C++学习基础四——顺序容器和关联容器
—顺序容器:vector,list,queue1.顺序容器的常见用法: #include <vector> #include <list> #include <queue ...
- C++ 顺序容器
<C++ Primer 4th>读书笔记 顺序容器内的元素按其位置存储和访问.容器类共享公共的接口,每种容器类型提供一组不同的时间和功能折衷方案.通常不需要修改代码,只需改变类型声明,用一 ...
- C++ Primer : 第九章 : 顺序容器的操作以及迭代器失效问题
顺序容器的添加.访问.删除操作以及forward_list的特殊操作,还有迭代器失效问题. 一.向容器添加元素 // array不支持这些操作 // forward_list有自己撰于的版本的inse ...
- C++ Primer : 第九章 : 顺序容器的定义、迭代器以及赋值与swap
顺序容器属于C++ STL的一部分,也是非常重要的一部分. 顺序容器包括: std::vector,包含在头文件<vector>中 std::string, 包含在头文件<strin ...
- 顺序容器:vector,deque,list
1.顺序容器:vector,deque,list 容器类共享公共接口,只要学会其中一种类型就能运用另一种类型.每种容器提供一组不同的时间和功能这种方案,通常不需要修改代码,秩序改变类型声明,每一种容器 ...
随机推荐
- JavaScript三(语法、关键保留字及变量)
基本概念 一.区分大小写 在ECMAScript中的一切(变量.函数名.操作符)都是区分大小写的. 如变量名test和Test分别表示两个不同的变量, 二.标识符 所谓标识符,就是指变量.函数.属性的 ...
- Linux 驱动之内核定时器
1.定时器 之前说过两类跟时间相关的内核结构. 1.延时:通过忙等待或者睡眠机制实现延时. 2.tasklet和工作队列,通过某种机制使工作推后运行,但不知道运行的详细时间. 接下来要介绍的定时器,可 ...
- 算法笔记_173:历届试题 斐波那契(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 斐波那契数列大家都非常熟悉.它的定义是: f(x) = 1 .... (x=1,2) f(x) = f(x-1) + f(x-2) ... ...
- Windows安装MySQL解压版
1:解压 2:设置环境变量 3:修改my.ini [mysqld] basedir = D:\MySQL\Server\mysql--win32 datadir = D:\MySQL\Server\d ...
- CSS3 选择器浏览器兼容性汇总 IE8
1.css选择器 css(包括css1.css2和css3)有哪些选择器? http://www.w3school.com.cn/cssref/css_selectors.asp 2.CSS3选择器 ...
- TOMCAT配置管理员
迁移时间--2017年7月9日15:16:02Author:Marydon CreateTime--2016年10月18日16:19:22Author:Marydon配置tomcat管理员参考链接 ...
- EditPlus破解版|很不错的编辑器
Windows自带的notepad,功能一般.editplus,很值得推荐的编辑器! 注册秘钥: 用户名:www.dayanzai.me序列号:D2C86-E97A0-BF376-FDC33-27C1 ...
- Java BigDecimal进行精确计算
前言 float和double类型的主要设计目标是为了科学计算和工程计算.他们执行二进制浮点运算,这是为了在广域数值范围上提供较为精确的快速近似计算而精心设计的.然而,它们没有提供完全精确的结果,所以 ...
- 照片管家iOS-实现本地相册、视频、安全保护、社交分享源码下载Demo
<照片管家> APP功能: 1.本地照片批量导入与编辑 2.本地视频存储与播放 3.手势密码.数字密码.TouchID安全保护 4.QQ.微信.微博.空间社交分享 5.其他细节功能. 运用 ...
- ios NSURLSession使用说明及后台工作流程分析
NSURLSession是iOS7中新的网络接口,它与咱们熟悉的NSURLConnection是并列的.在程序在前台时,NSURLSession与NSURLConnection可以互为替代工作.注意, ...