ng-深度学习-课程笔记-4: 浅层神经网络(Week3)
1 神经网络概览( Neural Networks Overview )
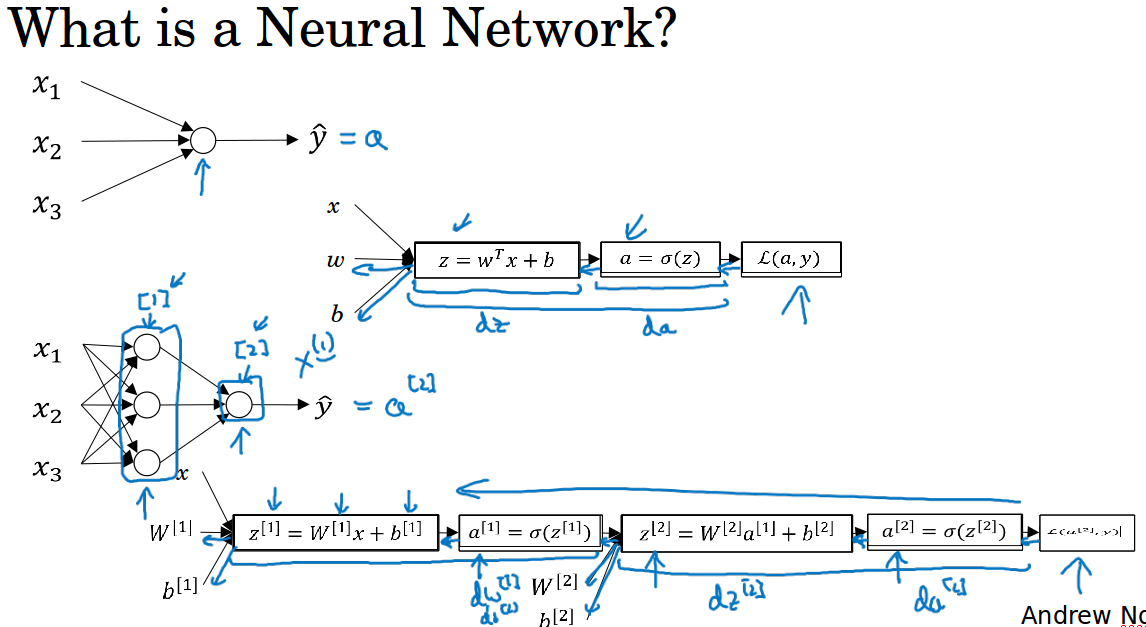
先来快速过一遍如何实现神经网络。
首先需要输入特征x,参数w和b,计算出z,然后用激活函数计算出a,在神经网络中我们要做多次这样的计算,反复计算z和a,然后用损失函数计算最后的a和y的差异。
可以把很多sigmoid单元堆叠起来构成一个神经网络。我们用上标方括号表示第几层,用上标圆括号表示第几个样本。
训练的时候通过反向传播来计算导数,先计算da,再计算dz,再到dw,db。
2 神经网络表示( Neural Network Representation )
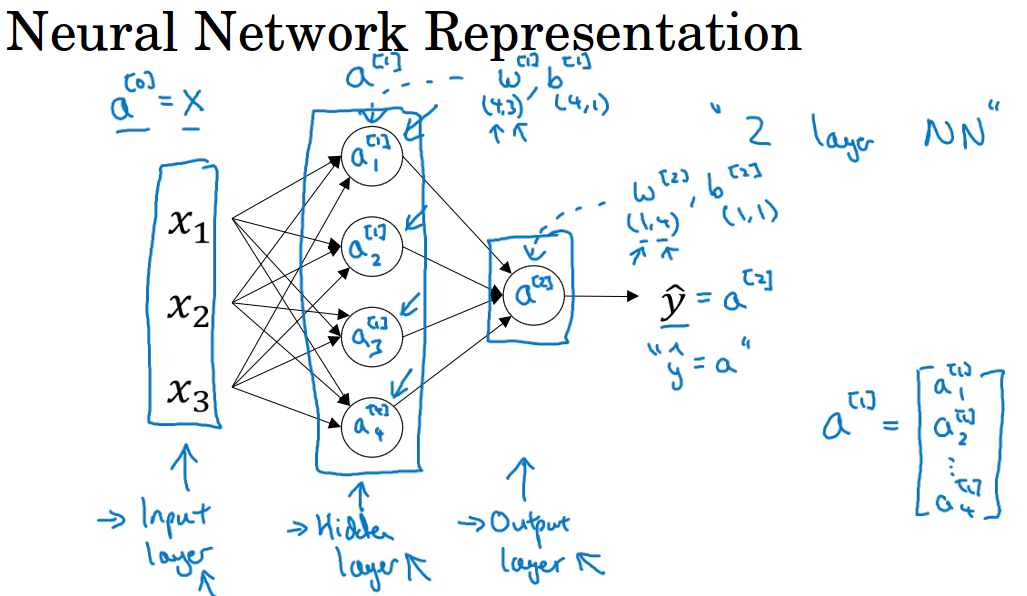
先集中看看只有一层隐藏层的神经网络。x1, x2, x3是神经网络的输入层,中间一层叫隐藏层,最后一个节点的层叫输出层。
为什么叫隐含层呢?它表示的是,在训练集中,这些中间节点的真正数值,我们是不知道的。我们能看到输入和输出,但是隐藏层的数值我们无法看到。
可以用$a^{[0]}$来表示输入x, $a^{[0]}$表示的是第0层输入层的输出。
相应的,隐藏层的输出就是$a^{[1]}$,下标则表示该层的第几个单元,图中有4个节点则代表有4个隐藏层输出。
输出层的输出就是$a^{[2]}$,表示最后的预测输出$\;\hat{y}\;$。这和之前提到的逻辑回归类似,只是这里明确地指出这些值来自哪一层。
在我们的约定中,输入层称为第0层,隐藏层称为第1层,这里的输出层称为第2层,这个网络是两层的神经网络,我们不把输入层看作一个标准的层。
隐藏层中的参数为$w^{[1]}$,$b^{[1]}$。w是一个4*3的矩阵,b是一个4*1的矩阵。4代表隐藏层的单元数量,3代表输入层的特征数量。
类似的,输出层的参数为$w^{[2]}$,$b^{[2]}$。它们的shape分别为1*4和1*1。
3 计算神经网络的输出( Computing a Neural Network's Output )
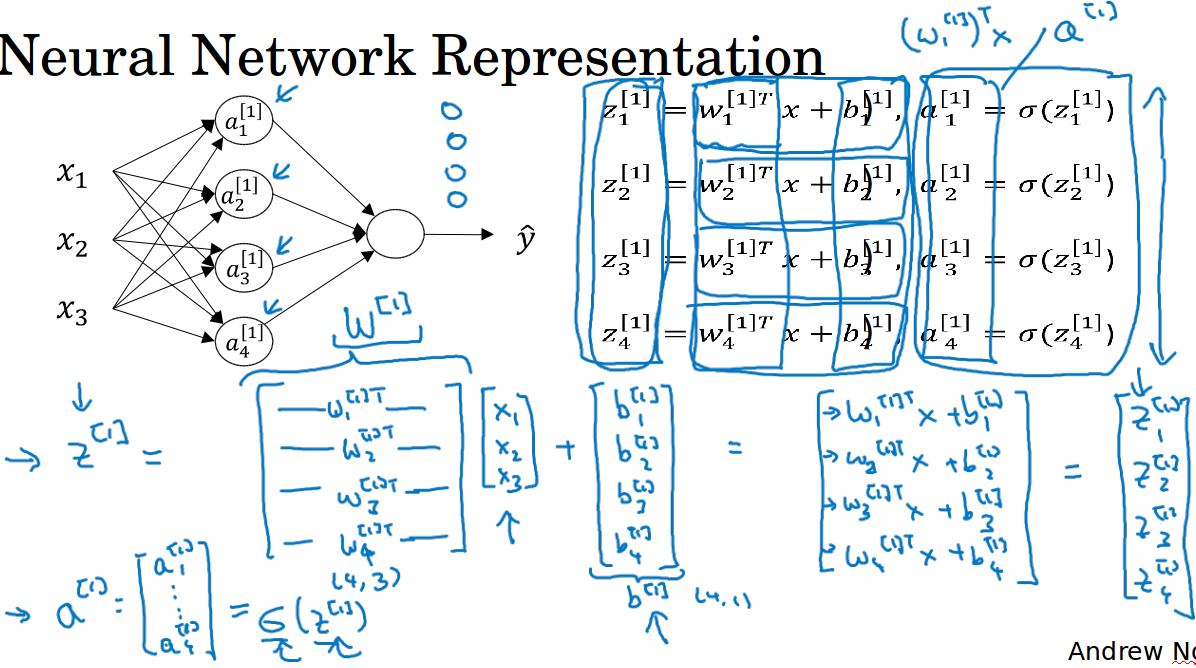
对于每一个神经单元,就是做一个加权和然后使用激活函数,即从x到z,从z得到a。神经网络不过是重复计算这个步骤很多次。
对于隐藏层四个节点的计算如图所示,后面的层也是类似地依次计算,最终得到输出。
4 多个例子中的向量化( Vectorizing across multiple examples )
多样本的输出计算也就是多次进行单样本的输出计算,用向量化的形式可以很好的理解这个过程。
比如,本来x的shape是3*1,w是4*3,得到的z就是4*1,其中4代表4个隐藏层的单元数,1代表1个样本。
现在X是多个样本,是3*m,w还是4*3,得到的Z就是4*m,4代表隐藏层的单元数,m代表的是样本数。

5 激活函数( Activation functions )
之前使用的激活函数都是sigmoid函数,我们还可以使用其它激活函数。
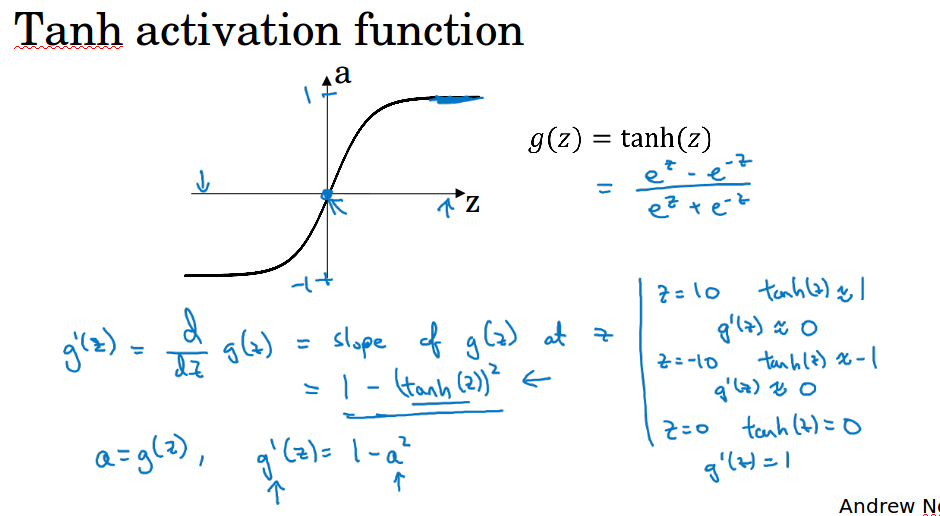
tanh( hyperbolic tangent 双曲正切),函数值介于-1到1之间,实际上这是sigmoid函数平移后的版本。
使用tanh几乎总比sigmoid表现更好,因为它的平均值为0,可以使得计算结果的平均值接近于0,起到了类似数据中心化的效果,它使得下一层的学习更方便。
ng表示他几乎不用sigmoid了,tanh几乎在任何场合都优于sigmoid,不过注意在输出层还是使用sigmoid,因为它输出[0,1]更符合概率分布。
sigmoid和tanh都有一个缺点,就是当自变量很大或者很小的时候,函数的导数特别小接近于0,这样会拖慢梯度下降的迭代,ng这里提到的问题应该就是梯度消失的问题了。
梯度消失是由于神经网络层数很多的时候,求导多次,导致梯度变得很小很小,这样前面的层就会学的很慢很慢,最后造成表现不好的结果。
可以用relu( rectified linear unit修正线性单元 ) 来解决这个问题。
选择激活函数有一些经验法则:做二分类的时候,sigmoid很适合做输出层的激活,其它层使用relu。
relu已经变成激活函数的默认选择了,如果你不确定隐层应该用哪个,就用relu作为激活,虽然人们有时候也会使用tanh。
relu的缺点是当z小于等于0时导数为0,所以有一个leakly relu,z小于等于0时导数不为0,但实践中很少使用。
现实中导数不会总是等于0,实践上神经网络有很多单元,总会有些单元导数不为0,所以通常使用relu,神经网络的学习会快很多,比tanh和sigmoid快,主要是它不会衰减梯度。
深度学习的其中一个特点就是在建立神经网络时经常有很多不同的选择,比如隐层个数,单元个数,激活函数,如何初始化权重,你很难去定下一个准则来确定什么参数最适合你的问题,有时候真的很难。
ng会在接下来这三门课中让我们了解到他在行业里见到的热门选择或冷门选择,但对于你的应用,事实上很难预先准备知道什么参数最有效。
所以一个建议是你不确定哪个激活函数的话,先试试,在验证集上跑跑,看看哪个参数效果好就用那个。
这里不会建议你一定要用relu而不用其它的,这对你目前或未来的问题中,可能管用也可能不管用。

6 为什么需要非线性激活函数( Why do you need non-linear activation functions )
如果你使用线性激活函数,或者没有激活函数,无论你的神经网络有多少层,你一直在做的只是计算线性激活函数。
这样做不如直接去掉所有隐藏层,因为你在这个过程中只是在做一个w的乘法,$w^{[1]}*w^{[2]}*w^{[3]}*...$,这里的123指的是层数。
在两层神经网络,如果你在隐藏层用线性激活,在输出层用sigmoid,这和没有隐层的逻辑回归是一样的。线性隐层一点意义都没有,因为线性函数的组合还是线性函数。
除非你引入非线性函数,否则你无法学习到更有趣的函数,层数再多也不行。
一般只有一个地方会用线性函数,就是在线性回归的输出层,因为它要预测的是一个实数,负无穷到正无穷。

7 激活函数的导数( Derivatives of activation functions )
这一节ng帮我们计算出了几个常用激活函数的导数,可以直接拿来用,当然可以自行推导验证一下。
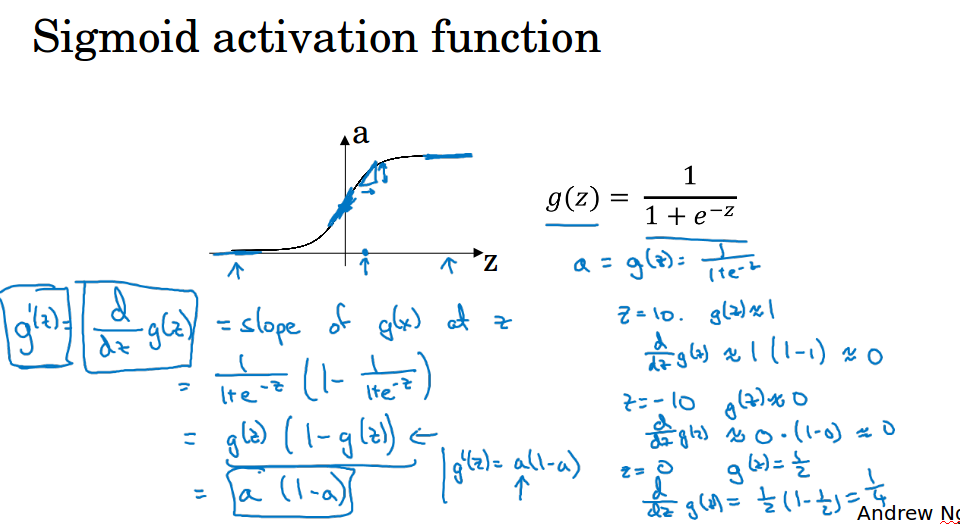
sigmoid:导数为a * ( 1 - a)
tanh:导数为1 - a*a
relu:导数为,z大于等于0时为1,z小于0时为0

8 神经网络的梯度下降( Gradient descent for Neural Networks )
做几个符号约定,$n^{[0]}$代表特征数,即输入层的单元个数,$n^{[1]}$代表隐层的单元个数,$n^{[2]}$代表输出层的单元个数。
$w^{[1]}$代表第0层到第1层的权重,shape为( $n^{[1]}$,$n^{[0]}$ ),$b^{[1]}$的shape为( $n^{[1]}$,1),后面的层以此类推。
根据前面讲的内容,可以列出代价函数的式子进行梯度下降的计算,之前讲过梯度下降,也讲过向量化的实现,所以关键在于如何计算偏导,利用前向计算和反向传播可以得到。
显然,除了求导的时候需要链式求导,其它的都和逻辑回归中做的东西差不多。
图中np.sum中参数axis为1代表按行相加(0按列相加),keepdim为True表示最后得到(n, 1)的列向量


9 随机初始化( Random Initizlization )
在神经网络中随机初始化很重要(而不是初始化为0),如果全部初始化为0的话,隐层的每个单元学习到的权重w都是一样的(对称的),这种情况下多个隐藏单元没有任何意义,因为它们做的是一样的事情,而我们需要不同的隐藏单元去计算不同的函数。
所以要随机初始化,可以用$np.random.randn( (2,2) ) * 0.01$ 和$np.zeros( (2,1) )$初始化w1和b1,通常喜欢把w初始化为很小的随机数,因为如果用sigmoid或tanh时权值太大会导致梯度特别小,学习缓慢。
ng-深度学习-课程笔记-4: 浅层神经网络(Week3)的更多相关文章
- Andrew Ng - 深度学习工程师 - Part 1. 神经网络和深度学习(Week 3. 浅层神经网络)
=================第3周 浅层神经网络=============== ===3..1 神经网络概览=== ===3.2 神经网络表示=== ===3.3 计算神经网络的输出== ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(一)CNN 卷积神经网络
深度学习课程笔记(一)CNN 解析篇 相关资料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html 首先提到 Why CNN for I ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
随机推荐
- Nginx 0.8.x + PHP 5.2.13(FastCGI)搭建胜过Apache十倍的Web服务器[摘抄]
[文章作者:张宴 本文版本:v6.3 最后修改:2010.07.26 转载请注明原文链接:http://blog.s135.com/nginx_php_v6/] 前言:本文是我撰写的关于搭建“Ngin ...
- HTML实体大全
HTML 4.01 支持 ISO 8859-1 (Latin-1) 字符集. ISO-8859-1 的较低部分(从 1 到 127 之间的代码)是最初的 7 比特 ASCII. ISO-8859-1 ...
- 64位ubuntu下用code::blocks IDE配置opengl开发环境
http://jingyan.baidu.com/article/c74d60007d104f0f6b595d6d.html 样例程序: #include <GL/glut.h> #inc ...
- redis 之初体验(window)
1 下载window版本的redis :https://github.com/MSOpenTech/redis/releases 2 解压压缩包.我的放在了E盘: E:/redis 3 程序,输入cm ...
- const关键字浅析
1 const变量 const double PI = 3.14159; 定义之后不能被修改,所以定义时必须初始化. const int i, j = 0; // error: i is unini ...
- OpenLayers基础知识:
OpenLayers是一个开源的js框架,用于在您的浏览器中实现地图浏览的效果和基本的zoom,pan等功能.OpenLayers支持的地图来源 包括了WMS,GoogleMap,KaMap,MSV ...
- linux下一些常用命令和访问目录
1. 目录 ls 列出目录文件名 ll 列出所有目录文件的访问权限等相关信息,包括 . .. ls -a 列出所有目录文件名,包括 . .. ls - ...
- 一个Activity中使用两个layout实例
package com.sbs.aas2l; import android.app.Activity; import android.os.Bundle; import android.view.Vi ...
- ROM和RAM的故事
在公众号里看到一篇很好的文章讲解rom和ram,之前也是一直不能理解两者的区别,今天就转载记下来吧.也方便大家学习. 因为我刚开始学习的时候总喜欢刨根问底,一个问题要是不搞清楚,后面学习都会很吃力的. ...
- Docker企业级仓库Harbor的安装配置与使用
Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如安全.标识和管理等,扩展了开源Docker Distribution.作为一个企业级 ...