实验:输入一篇英文新闻,以“#”结束,统计其中a-z这26个字母各出现的次数和总字符个数。(不区分大小写)
代码如下:
- #include <iostream>
- using namespace std;
- int main() {
- char ch;
- char s_letter[26]={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
- char b_letter[26]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'};
- int num[26]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
- for (int i = 1; i <= 10000; i++) {
- ch = cin.get();
- if(ch == '#')break;
- for(int j=0;j<=25;j++)
- {
- if(ch==s_letter[j] || ch==b_letter[j]) num[j]++;
- }
- }
- for(int i=0;i<=25;i++)
- {
- cout<<s_letter[i]<<"出现的个数为"<<num[i]<<endl;
- }
- }
(拓展)统计26个字母在一篇新闻中各自出现的频率。
代码如下:
- #include <iostream>
- using namespace std;
- int main() {
- char ch;
- char s_letter[26]={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
- char b_letter[26]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'};
- int num[26]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
- float f_num[26]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
- int Sum;
- for (int i = 1; i <= 10000; i++) {
- ch = cin.get();
- if(ch == '#')break;
- for(int j=0;j<=25;j++)
- {
- if(ch==s_letter[j] || ch==b_letter[j]) num[j]++;
- }
- }
- for(int i=0;i<=25;i++)
- {
- cout<<s_letter[i]<<"出现的个数为"<<num[i]<<endl;
- }
- for(int i=0;i<=25;i++)
- {
- Sum+=num[i]; //计算字母总数
- }
- for(int i=0;i<=25;i++)
- {
- f_num[i]=num[i]*(1.0)/Sum * 100; //计算字母出现的频率*100
- }
- for(int i=0;i<=25;i++)
- {
- cout<<s_letter[i]<<"出现的频率为";
- printf("%.3f",f_num[i]);//保留三位小数
- cout<<"%"<<endl;//输出频率为百分之几
- }
}
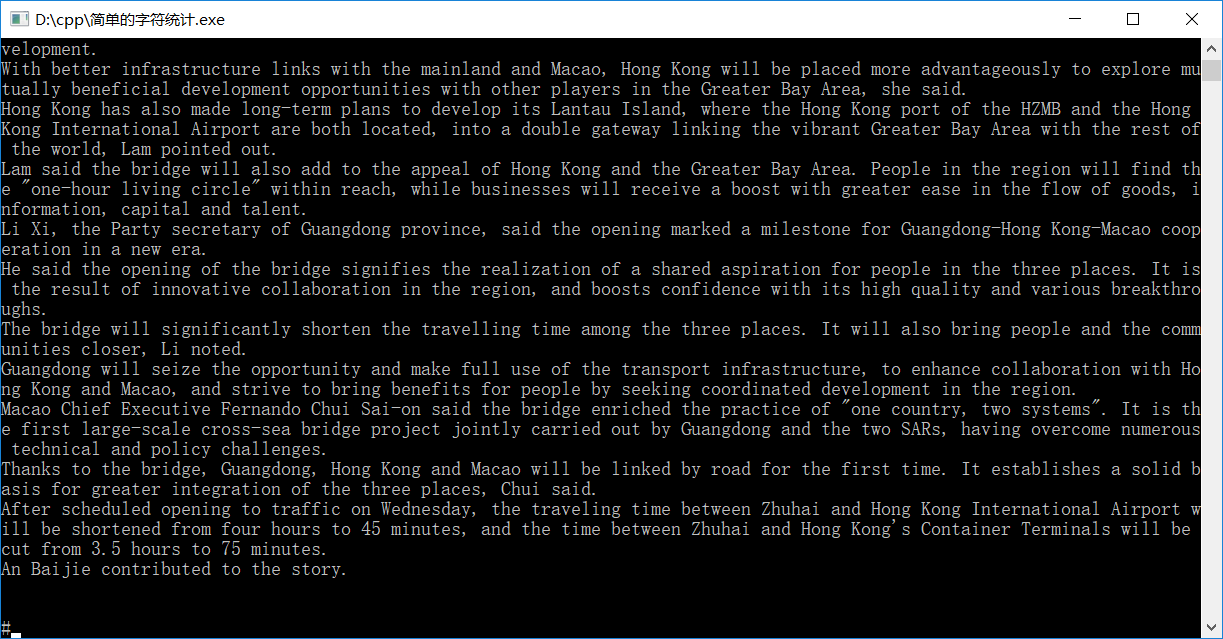
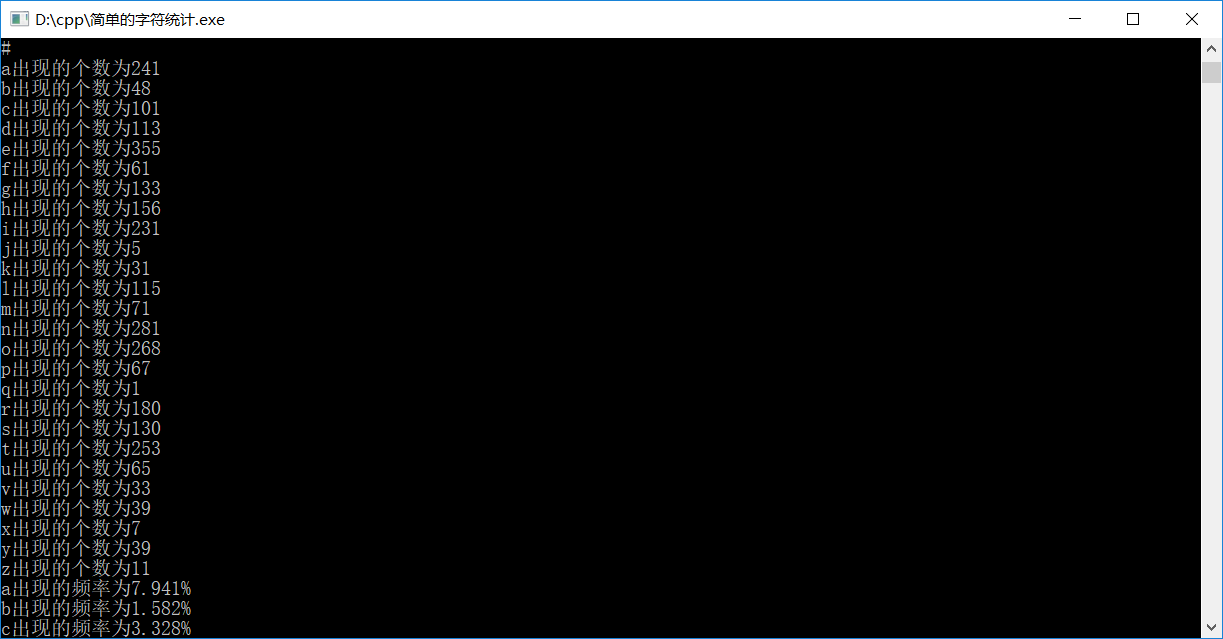
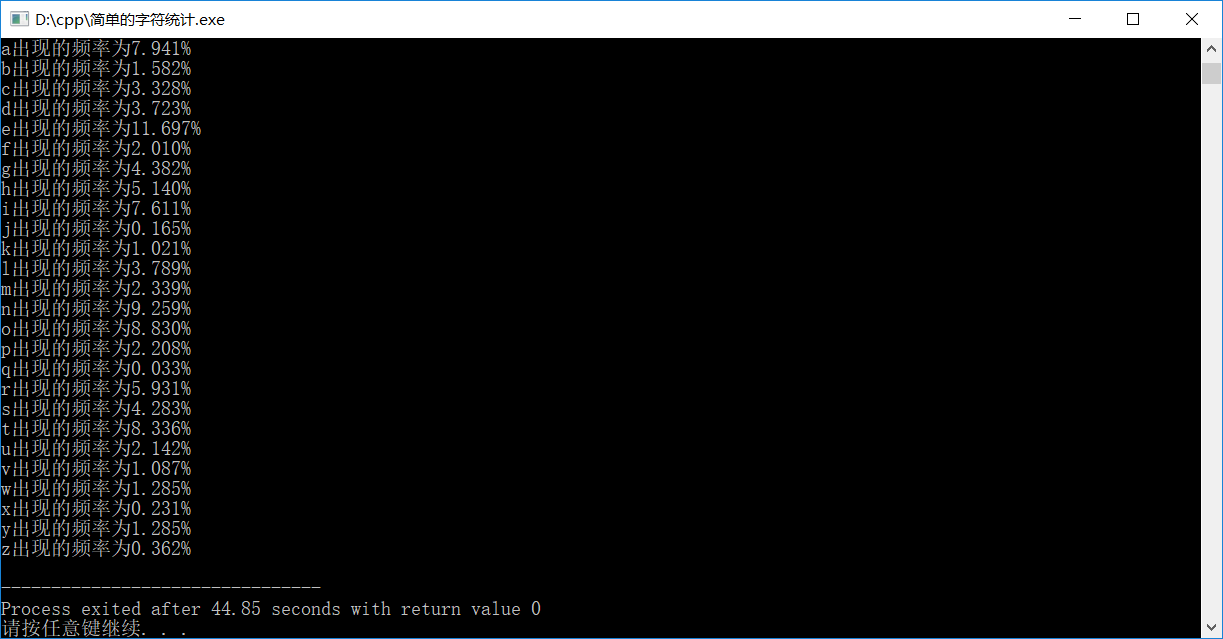
(拓展)英文新闻由文件输入,统计其中a-z这26个字母各出现的次数和总字符个数。(不区分大小写)
- #include <iostream>
- #include <fstream>
- #include <cassert>
- #include <string>
- #include<algorithm>
- #include<iomanip>
- using namespace std;
- int main()
- { char s_letter[26]={'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
- char b_letter[26]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'};
- int num[26]={0};
- float f_num[26]={0};
- ifstream infile;
- int Sum=0;
- infile.open("C:\\Users\\yyz22\\Desktop\\news1.txt");//打开文件txt 根据自身需求更改绝对路径 注意是双反斜杠\\
- char ch;
- infile >> noskipws;//不跳过空格和换行
- while (!infile.eof())//循环直到文本末尾结束
- {
- infile>>ch;
- cout<<ch;
- for(int j=0;j<=25;j++)
- {
- if(ch==s_letter[j] || ch==b_letter[j]) num[j]++;//统计字母出现个数
- }
- }
- infile.close();
- cout<<endl;
- for(int i=0;i<=25;i++)
- {
- cout<<s_letter[i]<<"出现的个数为"<<num[i]<<endl;
- Sum= Sum + num[i]; //计算字母总数
- }
- cout<<"总数:"<<Sum<<"\n";
- for(int i=0;i<=25;i++)
- {
- f_num[i]=float(num[i])/Sum; //计算字母出现的频率
- }
- for(int i=0;i<=25;i++)
- {
- cout<<s_letter[i]<<"出现的频率为";
- cout<<fixed<<setprecision(6)<<f_num[i]*100;
- cout<<"%"<<endl;//输出频率为百分之几
- }
- }
总结:for循环处理ch=cin.get(); 解决了enter结束输入流的问题。分别用if判断是什么字符或者#结束。
--yyz 1806
2018.10.24
实验:输入一篇英文新闻,以“#”结束,统计其中a-z这26个字母各出现的次数和总字符个数。(不区分大小写)的更多相关文章
- golang统计出其中英文字母、空格、数字和其它字符的个数
方法一 通过ASCII码表判断并统计 package main import "fmt" func charactortype() { var s2 string = " ...
- 【Python】【demo实验18】【练习实例】【统计输入字符串中,数字的个数、英文字母的个数及其他符号的个数】
原题: 输入一行字符,分别统计出其中英文字母.空格.数字和其它字符的个数. (本题暂时不支持中文字符及汉字) 我的代码: #!/usr/bin/python # encoding=utf-8 # -* ...
- js控制文本框只能输入中文、英文、数字与指定特殊符号.
先在'' 里输入 onkeyup="value=value.replace(/[^\X]/g,'')" 然后在(/[\X]/g,'')里的 X换成你想输入的代码就可以了, 中文u4 ...
- 限制HTML的input只能输入数字、英文、汉字...
限制HTML的input只能输入数字.英文.汉字... 关键词:正则表达式, JavaScript, HTML, input 常用HTML正则表达式1.只能输入数字和英文的:<input onk ...
- (js) 输入框只能输入中文、英文、数字、@符号和.符号
只能输入中文.英文.数字.@符号和.符号<input type="text" onkeyup="value=value.replace(/[^\a-\z\A-\Z0 ...
- C++语言,统计一篇英文文章中的单词数(用正则表达式实现)
下面的例子展示了如何在C++11中,利用regex_search()统计一篇英文文章中的单词数: #include <iostream> #include <regex> #i ...
- JS 控制文本框只能输入中文、英文、数字与指定特殊符号
想做姓名输入的js判断是否是中文,但是网上找的很多是源于一篇文章的,判断中文的正则式不对,后来找到一个可以准确判断了,但是是监测里面有中文的就行,跟我想要的只能输入中文的意思相左,所以又找了下面的 J ...
- js控制文本框仅仅能输入中文、英文、数字与指定特殊符号
JS 控制文本框仅仅能输入数字 <input onkeyup="value=value.replace(/[^0-9]/g,'')"onpaste="value=v ...
- Java Nested Classes(内部类~第一篇英文技术文档翻译)
鄙人最近尝试着翻译了自己的第一篇英文技术文档.Java Nested Classes Reference From Oracle Documentation 目录 嵌套类-Nested Classes ...
随机推荐
- C.【转】C语言字符串与数字相互转换
1.gcvt 把浮点数转成字符串 - CSDN博客.html(https://blog.csdn.net/dxuehui/article/details/52791412) 1.1. 函数名: gcv ...
- 学习笔记23—window10 64位 python2.7 安装liblinear
最近在使用pythin,因为要使用libsvm,所以到官网去下载libsvm.官网地址为libsvm(https://www.csie.ntu.edu.tw/~cjlin/libsvm/)结果下载下来 ...
- RTTI(运行时类型识别),typeid,dynamic_cast
dynamic_cast注意: 1.只能应用于指针和引用的转换: 2.要转换的类型中必须包含虚函数: 3.转换成功则返回地址,如果失败则返回NULL: 参见项目:RTTI
- zabbix自定义监控方式
- 20165327 2017-2018-2 《Java程序设计》第6周学习总结
20165327 2017-2018-2 <Java程序设计>第6周学习总结 教材内容总结 第八章 String类常用方法 public int length() public boole ...
- java日志及异常错误信息输出的问题
1.异常信息可以层层传递,直到最后一层再输出日志也来得及 2.错误信息要在发生错误的当时就输出日志,否则到了其它层,很难得到准确的错误信息内容
- 【debug、info、warn、error】四者之间的区别与用法
debug:需要在调试过程中输出的信息,但发布后是不需要的(当然发布后,也是看不到的) info:需要持续输出的信息(无论调试还是发布状态) warn:警告级别的信息(不严重) error:错误信息( ...
- WebStrom配置
1.下载安装Node.jshttps://nodejs.org/en/download/2.配置node路径3.修改文件默认字符集
- Xmanager Power Suit 6.0.0009 最新版注册激活
Xmanager Power Suit 6.0.0009 最新版注册激活 手工操作步骤Xmanger Power Suit 官方 其实有两种 .exe 文件,一个是用于试用的,在注册的时候不能直接输入 ...
- 【洛谷p2142】高精度减法
高精度减法第一遍没有过 高精度减法[传送门] 洛谷算法标签: 总之技术都在高精上了吧. 附代码: #include<iostream> #include<cstdio> #in ...