hadoop运行原理之Job运行(一) JobTracker启动及初始化
这部分的计划是这样的,首先解释JobTracker的启动过程和作业从JobClient提交到JobTracker上;然后分析TaskTracker和heartbeat;最后将整个流程debug一遍来加深映象。
在看JobTracker源代码的时候就会发现,它里边有main()方法,这就说明了它是一个独立的java进程。在hadoop根目录下的bin文件夹中的hadoop脚本中可以看到,它指定了JobTracker类。如下图所示:
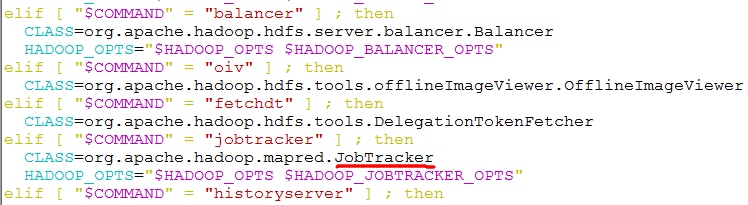
JobTracker的main()方法中最主要的是以下两条语句:
public static void main(String argv[]
) throws IOException, InterruptedException {
StringUtils.startupShutdownMessage(JobTracker.class, argv, LOG); try {
if(argv.length == 0) {
JobTracker tracker = startTracker(new JobConf());//用来生成JobTracker对象
tracker.offerService();//初始化JobTracker,并启动作业调度器
}
else {
if ("-dumpConfiguration".equals(argv[0]) && argv.length == 1) {
dumpConfiguration(new PrintWriter(System.out));
}
else {
System.out.println("usage: JobTracker [-dumpConfiguration]");
System.exit(-1);
}
}
} catch (Throwable e) {
LOG.fatal(StringUtils.stringifyException(e));
System.exit(-1);
}
}
startTracker()方法比较简单,通过几次方法调用最终生成JobTracker对象。下面重点分析offerService()方法。由于篇幅限制,只列出了最重要的部分:
public void offerService() throws InterruptedException, IOException {
......
// Initialize the JobTracker FileSystem within safemode
setSafeModeInternal(SafeModeAction.SAFEMODE_ENTER);
initializeFilesystem();
setSafeModeInternal(SafeModeAction.SAFEMODE_LEAVE);
// Initialize JobTracker
initialize();
......
taskScheduler.start();
首先进入安全模式下(SAFEMODE_ENTER),初始化文件系统,然后退出安全模式(SAFEMODE_LEAVE)。然后初始化JobTracker。最后启动作业调度器(TaskScheduler)。默认的作业调度器是JobQueueTaskScheduler,在mapred-default.xml中配置。所以taskScheduler.start()会调用JobQueueTaskScheduler的start()方法。如下所示:

JobQueueTaskScheduler使用FIFO来对job进行调度。下面来进入到JobQueueTaskScheduler来分析start()方法。
@Override
public synchronized void start() throws IOException {
super.start();
taskTrackerManager.addJobInProgressListener(jobQueueJobInProgressListener);
eagerTaskInitializationListener.setTaskTrackerManager(taskTrackerManager);
eagerTaskInitializationListener.start();
taskTrackerManager.addJobInProgressListener(
eagerTaskInitializationListener);
}
这里用到了观察者模式,JobQueueTaskScheduler向JobTracker注册了两个JobInProgressListener:EagerTaskInitializationListener和JobQueueJobInProgressListener,分别用于作业初始化和作业排序。
这里的taskTrackerManager实际上是JobTracker,因为JobTracker的父类就是TaskTrackerManager。在JobTracker的startTracker()方法中,将JobTracker实例传递给TaskTrackerManager。如下所示:
public static JobTracker startTracker(JobConf conf, String identifier, boolean initialize)
throws IOException, InterruptedException {
DefaultMetricsSystem.initialize("JobTracker");
JobTracker result = null;
while (true) {
try {
result = new JobTracker(conf, identifier);
result.taskScheduler.setTaskTrackerManager(result);
......
在eagerTaskInitializationListener.start()方法启动一个线程JobInitManager,这个线程用来监控jobInitQueue,即List<JobInProgress>。当有新的job(JobInProgress)加入到队列中时,JobInitManager线程就对其进行初始化。
class JobInitManager implements Runnable {
public void run() {
JobInProgress job = null;
while (true) {
try {
synchronized (jobInitQueue) {
while (jobInitQueue.isEmpty()) {
jobInitQueue.wait();
}
job = jobInitQueue.remove(0); //从队列中拿出一个job
}
threadPool.execute(new InitJob(job)); //对job进行初始化
} catch (InterruptedException t) {
LOG.info("JobInitManagerThread interrupted.");
break;
}
}
LOG.info("Shutting down thread pool");
threadPool.shutdownNow();
}
}
class InitJob implements Runnable {
private JobInProgress job;
public InitJob(JobInProgress job) {
this.job = job;
}
public void run() {
ttm.initJob(job); //实质上调用JobTracker的initJob()方法进行初始化
}
}
这里JobInitManager线程最终调用了JobTracker的initJob()方法来对job进行初始化。具体过程下篇文章中再写。
最后画个流程图来总结一下,画的不好,将就看一下吧。

本文基于hadoop1.2.1
如有错误,还请指正
参考文章:《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》 董西成
转载请注明出处:http://www.cnblogs.com/gwgyk/p/3998753.html
hadoop运行原理之Job运行(一) JobTracker启动及初始化的更多相关文章
- hadoop运行原理之Job运行(二) Job提交及初始化
本篇主要介绍Job从客户端提交到JobTracker及其被初始化的过程. 以WordCount为例,以前的程序都是通过JobClient.runJob()方法来提交Job,但是现在大多用Job.wai ...
- hadoop运行原理之Job运行(三) TaskTracker的启动及初始化
与JobTracker一样,TaskTracker也有main()方法,然后以线程的方式启动(继承了Runnable接口).main()方法中主要包含两步:一是创建一个TaskTracker对象:二是 ...
- hadoop运行原理之Job运行(四) JobTracker端心跳机制分析
接着上篇来说,TaskTracker端的transmitHeartBeat()方法通过RPC调用JobTracker端的heartbeat()方法来接收心跳并返回心跳应答.还是先看看这张图,对它的大概 ...
- hadoop运行原理之Job运行(五) 任务调度
接着上篇来说.hadoop首先调度辅助型task(job-cleanup task.task-cleanup task和job-setup task),这是由JobTracker来完成的:但对于计算型 ...
- html、JSP运行原理
HTML运行原理 1.本地运行 所谓本地运行就是直接用 浏览器打开 2.远程访问的原理示意图: 何为协议?计算机互相通信(网络)的规则.常见的协议有 http .smtp. ftp.pop等 ...
- jmeter的运行原理和测试计划要素
jmeter运行原理 1.jmeter运行在JVM虚拟机上,jmeter是以线程的方式运行的. 2.jmeter通过线程组来驱动多个线程,运行测试脚本对被测试服务器发起负载,每一个负载机上够可以运行多 ...
- Python+Appium运行简单的demo,你需要理解Appium运行原理!
坚持原创输出,点击蓝字关注我吧 作者:清菡 博客:oschina.云+社区.知乎等各大平台都有. 目录 一.Appium 的理念 四个原则 1.Web-Selenium 的运行原理 2.Appium ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop(六)之HDFS的存储原理(运行原理)
前言 其实说到HDFS的存储原理,无非就是读操作和写操作,那接下来我们详细的看一下HDFS是怎么实现读写操作的! 一.HDFS读取过程 1)客户端通过调用FileSystem对象的open()来读取希 ...
随机推荐
- Java语言的特点
一. 面向对象:其实是现实世界模型的自然延伸.现实世界中任何实体都可以看作是对象.对象之间通过消息相互作用.另外,现实世界中任何实体都可归属于某类事物,任何对象都是某一类事物的实例.如果说传统的过程式 ...
- ExtJs Grid 删除,编辑,查看详细等超链接处理
在网上查了好多资料,关于ExtJs处理操作栏的“删除”.“编辑”.“查看详细”的处理,原来项目都是这么处理: 操作栏:{ text:'操作', xtype:'actioncolumn', items ...
- 三层架构下的EntityFramework codefirst
好久没写博客了,今天研究了EF框架的CodeFirst模式,从字面意思可以看出,代码优先.所谓代码优先,与以往的添加ado.net不同,主要是编写代码生成数据库和数据表,生成数据实体映射.个人感觉这种 ...
- REPL LOG
using System; using System.Collections.Generic; using System.Text; using System.Text.RegularExpressi ...
- js 获得日期相差天数
function getDays(strDateStart,strDateEnd){ var strSeparator = "-"; //日期分隔符 ...
- [Python]如何获取目录下,最后更新的文件
#-*- coding: utf-8 -*- __author__ = 'tsbc' import time import datetime import os day = time.strftime ...
- Java程序员开发参考资源
构建 这里搜集了用来构建应用程序的工具. Apache Maven:Maven使用声明进行构建并进行依赖管理,偏向于使用约定而不是配置进行构建.Maven优于Apache Ant.后者采用了一种过程化 ...
- python matplotlib 中文显示参数设置
python matplotlib 中文显示参数设置 方法一:每次编写代码时进行参数设置 #coding:utf-8import matplotlib.pyplot as pltplt.rcParam ...
- jquery之remove(),detach()方法详解
一:remove()方法 remove()函数用于从文档中移除匹配的元素. 你还可以使用选择器进一步缩小移除的范围,只移除当前匹配元素中符合指定选择器的部分元素. 与detach()相比,remove ...
- 《BI那点儿事》META DATA(元数据)
关于数据仓库的数据,指在数据仓库建设过程中所产生的有关数据源定义,目标定义,转换规则等相关的关键数据.同时元数据还包含关于数据含义的商业信息,所有这些信息都应当妥善保存,并很好地管理.为数据仓库的发展 ...