ZooKeeper分布式集群安装
我特意选择了稳定版......
奇数意思是说奇数和偶数对故障的容忍度是一致的....所以建议配置奇数个,并不是必须奇数...
一、master节点上安装配置
1、下载并解压ZooKeeper-3.4.6.tar.gz
tar -zxvf zookeeper-3.4.6.tar.gz
这里路径为 /home/fesh/zookeeper-3.4.6
2、设置the Java heap size (个人感觉一般不需要配置)
保守地use a maximum heap size of 3GB for a 4GB machine
3、$ZOOKEEPER_HOME/conf/zoo.cfg
cp zoo_sample.cfg zoo.cfg
新建此配置文件,并设置内容

# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/fesh/data/zookeeper
# the port at which the clients will connect
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
4、/home/fesh/data/zookeeper/myid
在节点配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,$ZOOKEEPER_HOME/conf/zoo.cfg文件中配置的server.X,则myid文件中就输入这个数字X。(即在每个节点上新建并设置文件myid,其内容与zoo.cfg中的id相对应)这里master节点为 1
mkdir -p /home/fesh/data/zookeeper
cd /home/fesh/data/zookeeper
touch myid
echo "1" > myid
5、设置日志
conf/log4j.properties
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, CONSOLE
改为
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, ROLLINGFILE
将
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
改为---每天一个log日志文件,而不是在同一个log文件中递增日志
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender
bin/zkEvn.sh
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="."
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,CONSOLE"
fi
改为
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="$ZOOBINDIR/../logs"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
二、从master节点分发文件到其他节点
1、在master节点的/home/fesh/目录下
scp -r zookeeper-3.4.6 slave1:~/
scp -r zookeeper-3.4.6 slave2:~/
scp -r data slave1:~/
scp -r data slave2:~/
2、在slave1节点的/home/fesh/目录下
vi ./data/zookeeper/myid
修改为 2
3、在slave2节点的/home/fesh/目录下
vi ./data/zookeeper/myid
修改为 3
三、其他配置
1、在每个节点配置/etc/hosts (并保证每个节点/etc/hostname中分别为master、slave1、slave2) 主机 -IP地址映射
192.168.145.129 master
192.168.145.130 slave1
192.168.145.131 slave2
2、在每个节点配置环境变量/etc/profile
#Set ZOOKEEPER_HOME ENVIRONMENT
export ZOOKEEPER_HOME=/home/fesh/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
四、启动
在每个节点上$ZOOKEEPER_HOME目录下,运行 (这里的启动顺序为 master > slave1 > slave2 )
bin/zkServer.sh start
并用命令查看启动状态
bin/zkServer.sh status
master节点
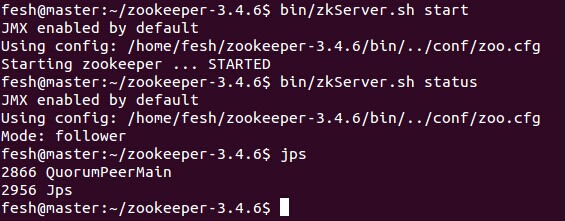
slave1节点
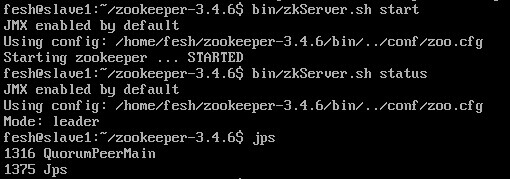
slave2节点
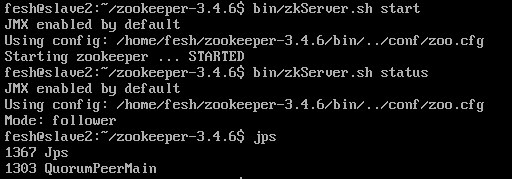
(注:之前我配置正确的,但是一直都是,每个节点上都启动了,但就是互相连接不上,最后发现好像是防火墙的原因,啊啊啊!一定要先把防火墙关了! sudo ufw disable )
五、结束语
5.1 日志报错
查看$ZOOKEEPER_HOME/zookeeper.out 日志,会发现开始会报错,但当leader选出来之后 就没有问题了。
我启动的顺序是slave-01>slave-02>slave-03,由于ZooKeeper集群启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
其他结点可能也出现类似问题,属于正常。
5.2 时钟同步
zookeeper等需要其他机器和master时间同步。
ZooKeeper分布式集群安装的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- 在 Linux 多节点安装配置 Apache Zookeeper 分布式集群
规划: 三台物理服务器就形成了(法定人数).对于高可用性集群,您可以使用高于3的任何奇数.例如,如果设置5台服务器,则集群可以处理两个故障节点等. 物理服务器需要开启的端口 2888 , 3888 和 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- Zookeeper分布式集群搭建
实验条件:3台安装linux的机子,配置好Java环境. 步骤1:下载并分别解包到每台机子的/home/iHge2k目录下,附上下载地址:http://mirrors.cnnic.cn/apache/ ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- (原) 1.2 Zookeeper伪集群安装
本文为原创文章,转载请注明出处,谢谢 Zookeeper伪集群安装 zookeeper单机安装配置可以查看 1.1 zookeeper单机安装 1.复制三份zookeeper,分别为zookeeper ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- zookeeper+kafka集群安装之一
zookeeper+kafka集群安装之一 准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下: $ cat /etc/hosts ... # zookeeper hostnames ...
随机推荐
- IE 和Firefox的js兼容性总结
IE 和Firefox的js兼容性总结 12 August 2010 11:39 Thursday by 小屋 标签: 浏览器 方法 属性 IT 写法 一.函数和方法差异 1 . getYear()方 ...
- Android各种屏幕适配原理
dip(dp): device independent pixels(设备独立像素) dip,就是把屏幕的高分成480分,宽分成320分.比如你做一条160dip的横线,无论你在320还480的模拟器 ...
- Mysql的操作说明
Mysql对于用户的操作权限的控制都在:mysql.user表中 User字段:表示用户名称: Host字段:表示允许该用户访问的地址,可以是域名(如localhost).主机名.ip和%:%表示不限 ...
- 翻译qmake文档(二) Getting Started
翻译qmake文档 目录 原英文文档: http://qt-project.org/doc/qt-5/qmake-tutorial.html 本教程教讲授qmake基础知识.这个手册里 ...
- 玉伯的一道课后题题解(关于 IEEE 754 双精度浮点型精度损失)
前文 的最后给出了玉伯的一道课后题,今天我们来讲讲这题的思路. 题目是这样的: Number.MAX_VALUE + 1 == Number.MAX_VALUE; Number.MAX_VALUE + ...
- .NET MVC HtmlHepler
一.HtmlHepler 1.ActionLink() 动态生成 超链接:根据路由规则,生成对应的 html 代码. //1.注册路由信息 routes.MapRoute( name: "D ...
- JavaScript中call,apply,bind方法的总结。
why?call,apply,bind干什么的?为什么要学这个? 一般用来指定this的环境,在没有学之前,通常会有这些问题. var a = { user:"追梦子", fn:f ...
- nios II--实验5——定时器软件部分
软件开发 首先,在硬件工程文件夹里面新建一个software的文件夹用于放置软件部分:打开toolsàNios II 11.0 Software Build Tools for Eclipse,需要进 ...
- 站内搜索——Lucene +盘古分词
为了方便的学习站内搜索,下面我来演示一个MVC项目. 1.首先在项目中[添加引入]三个程序集和[Dict]文件夹,并新建一个[分词内容存放目录] Lucene.Net.dll.PanGu.dll.Pa ...
- js 漩涡
What's the ball's orbit if they head for it's next ball. <html> <canvas id="ca"&g ...