HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程:
安装Hbase之前首先系统应该做通用的集群环境准备工作,这些是必须的:
1、集群中主机名必须正确配置,最好有实际意义;并且主机名都在hosts文件中对应主机IP,一一对应,不可缺少
这里集群有6台服务器:bigdata1,bigdata2,bigdata3,bigdata4,bigdata5,bigdata6
这里是3台主机,分别对应
2、JDK环境正确安装
3、集群中每台机器关闭防火墙,保证通信畅通
4、配置集群间ssh免密登录
5、集群ntp服务开启,保证时间同步(这一步非常重要,否则hbase启动会失败)
6、zookeeper正确安装
7、Hadoop HDFS服务开启
这里预定zookeeper的地址为:bigdata2,bigdata3,bigdata4,bigdata5,bigdata6 5个zookeeper节点
hadoop namenode为bigdata1(主),bigdata2(备用),其余4个为datanode
hbase Master为bigdata1,其余为存储节点
基于以上配置结合集群高可用配置,构成一个性能比较好的集群配置方式
前面6步都配置好的基础上,首先配置Hadoop集群,在bigdata1上做配置操作
首先解压hadoop,并安装至指定目录:
tar -xvzf hadoop-2.6..tar.gz
mkdir /bigdata/hadoop
mv hadoop-2.6. /bigdata/hadoop
cd /bigdata/hadoop/hadoop-2.6.
就是简单的释放,然后为了方便可以将HADOOP_HOME添加至环境变量
配置hadoop需要编辑以下几个配置文件:
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves
1、编辑hadoop-env.sh
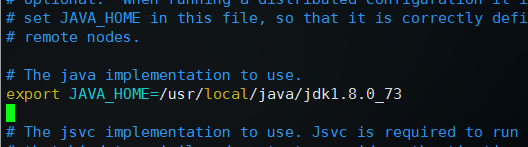
修改export JAVA_HOME=${JAVA_HOME}为自己的实际安装位置
这里是export JAVA_HOME=/usr/local/java/jdk1.8.0_73
2、编辑core-site.xml,在configuration标签中间添加如下代码,
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopha</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata2:2181,bigdata3:2181,bigdata4:2181,bigdata5:2181,bigdata6:2181</value>
</property>
3、编辑hdfs-site.xml ,添加如下代码:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<!--这里和core-site中配置保持一致-->
<value>hadoopha</value>
</property> <property>
<name>dfs.ha.namenodes.hadoopha</name>
<value>bigdata1,bigdata2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoopha.bigdata1</name>
<value>bigdata1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopha.bigdata1</name>
<value>bigdata1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoopha.bigdata2</name>
<value>bigdata2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopha.bigdata2</name>
<value>bigdata2:50070</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:///bigdata/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///bigdata/hadoop/hdfs/data</value>
</property>
<!-- 这个地方是为Hbase的专用配置,最小为4096,表示同时处理文件的上限,不配置会报错 -->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property> <!--提供journal的服务器列表,一般为奇数个,这里为3个-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata3:8485;bigdata4:8485;bigdata5:8485/hadoopha</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <property>
<name>dfs.client.failover.proxy.provider.hadoopha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/hdfs/journal</value>
</property> <property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>5000</value>
</property> <!--配置ssh密钥存放位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
其中配置的注释说明要注意一下
4、编辑mapred-site.xml,这个不用配置
5、编辑yarn-site.xml,这个也不用配置
6、编辑slaves,添加datanode节点
bigdata3
bigdata4
bigdata5
bigdata6
这些都保存完毕,将/bigdata/下的hadoop目录整体发送至集群中其他主机,其他主机应该事先建立好bigdata目录
scp -r /bigdata/hadoop bigdata2:/bigdata
scp -r /bigdata/hadoop bigdata3:/bigdata
scp -r /bigdata/hadoop bigdata4:/bigdata
scp -r /bigdata/hadoop bigdata5:/bigdata
scp -r /bigdata/hadoop bigdata6:/bigdata
然后在配置jouralnode的服务器上启动jouralnode服务,这里是bigdata3,4,5
sbin/hadoop-daemon.sh start journalnode
然后在bigdata1上格式化zookeeper节点:
bin/hdfs zkfc -formatZK
在其中一台namenode上格式化文件系统并启动namenode,这里是bigdata1:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
在另外一台namenode,bigdata2上同步元数据:
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
然后启动hdfs服务:
sbin/start-dfs.sh
启动完成之后,执行 jps 命令,在主节点可以看到NameNode和DFSZKFailoverController进程;其他节点可以看到DataNode进程
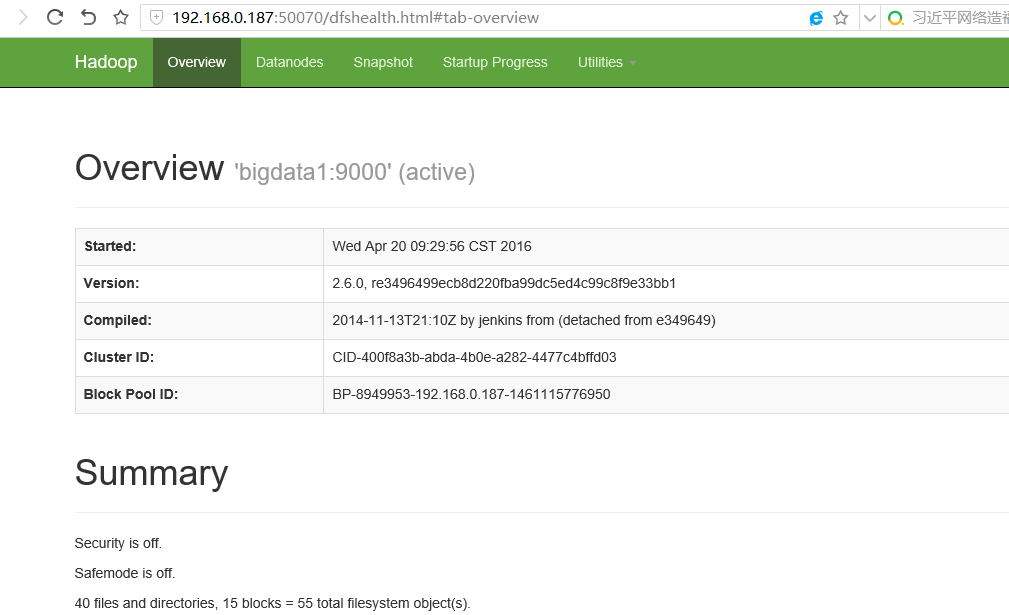
现在通过浏览器可以打开相应的管理界面,以bigdata1的IP访问:
http://192.168.0.187:50070
到这里hadoop hdfs就部署完成了,然后开始部署HBase,这里使用的版本为:hbase-0.98.18-hadoop2-bin.tar.gz
和释放hadoop包一样将hbase释放到对应的目录并进入,这里是:/bigdata/hbase/hbase-0.98.18-hadoop2
首先编辑配置文件: vim conf/hbase-env.sh
去掉JAVA_HOME前面的注释,改为自己实际的JDK安装路径,和配置hadoop类似

然后,去掉export HBASE_MANAGES_ZK=true前面的注释并改为export HBASE_MANAGES_ZK=false,配置不让HBase管理Zookeeper
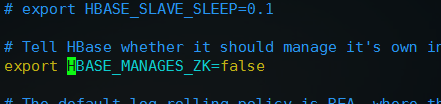
配置完这两项之后,保存退出
编辑文件 vim conf/hbase-site.xml 在configuration标签之间加入如下配置:
<!-- 指定HBase在HDFS上面创建的目录名hbase -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoopha/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>60000</value>
</property>
<!-- 开启集群运行方式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/bigdata/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata2,bigdata3,bigdata4,bigdata5,bigdata6</value>
</property>
分别将hadoop配置下的core-site.xml和hdfs-site.xml复制或者做软链接到hbase配置目录下:
cp /bigdata/hadoop/hadoop-2.6./etc/hadoop/core-site.xml conf/
cp /bigdata/hadoop/hadoop-2.6./etc/hadoop/hdfs-site.xml conf/
执行 vim conf/regionservers 编辑运行regionserver存储服务的Hbase节点,就相当于hadoop slaves中的DataNode节点
这里是bigdata2~bigdata5
保存之后,配置完毕,将hbase发送至其他数据节点:
scp -r /bigdata/hbase/ bigdata2:/bigdata/
scp -r /bigdata/hbase/ bigdata3:/bigdata/
scp -r /bigdata/hbase/ bigdata4:/bigdata/
scp -r /bigdata/hbase/ bigdata5:/bigdata/
scp -r /bigdata/hbase/ bigdata6:/bigdata/
然后在bigdata1启动Hbase Master
bin/hbase-daemon.sh start master
启动成功,在bigdata1会增加进程:HMaster
然后在bigdata2启动regionserver进程,其余4台集群会跟随启动
bin/hbase-daemons.sh start regionserver
这里注意跟随启动时,bigdata2到所有机器ssh确保直接进入,如果配置好的免密也最好提前都进一遍,避免需要输入yes而导致错误
同时集群的时间一定同步,否则hbase会启动失败出现NoNode Error的异常
在bigdata2到bigdata6会增加进程:HRegionServer
到这里HBase就部署完毕,并且包含zookeeper集群高可用配置
执行命令: /bigdata/hadoop/hadoop-2.6./bin/hdfs dfs -ls / 可以查看hbase是否在HDFS文件系统创建成功

看到/hbase节点表示创建成功
然后执行: bin/hbase shell 可以进入Hbase管理界面
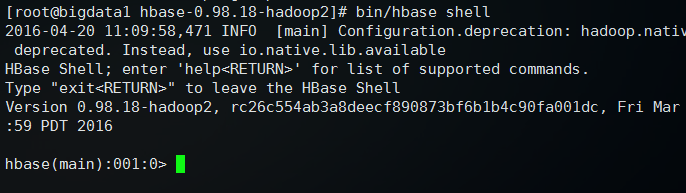
输入 status 查看状态

返回状态,表示HBase可以正常使用
输入 quit 可以退出管理,回到命令行
访问浏览器http://ip:60010可以打开Hbase管理界面
HBase集成Zookeeper集群部署的更多相关文章
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- Centos6下zookeeper集群部署记录
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目的 最终一致性:client不论 ...
- Gitlab CI 集成 Kubernetes 集群部署 Spring Boot 项目
在上一篇博客中,我们成功将 Gitlab CI 部署到了 Docker 中去,成功创建了 Gitlab CI Pipline 来执行 CI/CD 任务.那么这篇文章我们更进一步,将它集成到 K8s 集 ...
- 分布式协调服务之Zookeeper集群部署
一.分布式系统概念 在聊Zookeeper之前,我们先来聊聊什么是分布式系统:所谓分布式系统就是一个系统的软件或硬件组件分布在网络中的不同计算机之上,彼此间通过消息传递进行通信和协作的系统:简单讲就是 ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- Zookeeper集群部署
一. 部署前的准备工作 保证各个主机之间能够正常通信,最好是在同一网段. 修改host文件,加入IP和主机名的映射.方法为修改/etc/hosts和etc/hostname文件,不同的Linux发行版 ...
- docker环境下solrcloud+zookeeper集群部署教程
前言:两个月前的16年11月份完成的配置,使用的solr6.1和zookeeper3.4,刚刚写成blog,目前版本可能有小版本的变化. 本例完成结果为:在docker环境下部署solrcloud集群 ...
- Zookeeper集群部署与配置(三)
在上一篇博客中我们讲解了<Zookeeper的单机配置>,此篇博客将继续介绍Zookeeper的集群部署与配置. 环境 集群配置的环境与单机配置的环境相同,唯一不同的就是集群是在多台服务器 ...
随机推荐
- GOF业务场景的设计模式-----观察者模式
定义:定义对象间一种一对多的依赖关系,使得当每一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新. 在软件系统中经常会有这样的需求:如果一个对象的状态发生改变,某些与它相关的对象也要随之做出 ...
- [整理]AngularJS学习资源
https://angular.io/docs/js/latest/(2.0官方网站) http://www.linuxidc.com/Linux/2014-05/102139.htm(Angular ...
- 也谈Promise
最新的ES6标准添加有Promise方法,但自己在项目中一直使用jQuery(jQuery自己实现了不标准的Promise),加上es6标准还没有得到普及,也就懒得学习相关资料. 最近手头上的活少了, ...
- 一张图告诉你,只会JavaScript还不够!
会了JavaScript语法,你就真的会了JavaScript吗,来看这张图!是超实用的JavaScript代码段一书的导览!熊孩子们,赶紧学习去吧!
- Asp.net 网站防攻击安全设置
针对已解密的_ViewStat参数漏洞整改建议:在<system.web>下添加 <machineKey validation="3DES"/> 禁用脚本调 ...
- tcp三次握手与四次挥手
- 弹窗插件 popup.js 完美修正版
作为信息展示弹出窗口,很有用!是一个js插件,不是jQuery插件! 地址:http://img.jb51.net/online/popup/popup.html
- 使用VNC登录Linux
###服务器是否配置了VNCSERVER,可以在命令行下敲入以下命令查看: [root@localhost: ~]#rpm -qa |grep vnc ###配置VNC 1. 机器IP为:10.0.0 ...
- Android内存性能优化(内部资料总结)
eoe上看到的一个很好的文章 摘抄了下来留着自己看看 刚入门的童鞋肯能都会有一个疑问,Java不是有虚拟机了么,内存会自动化管理,我们就不必要手动的释放资源了,反正系统会给我们完成.其实Java中没有 ...
- vs2012+qt5.2.0环境搭建
1.安装vs2012: 2.下载Qt 5.2.0 for Windows 32-bit(VS 2012, 579 MB) 和 Visual Studio Add-in 1.2.2for Qt5 注意: ...