HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程:
安装Hbase之前首先系统应该做通用的集群环境准备工作,这些是必须的:
1、集群中主机名必须正确配置,最好有实际意义;并且主机名都在hosts文件中对应主机IP,一一对应,不可缺少
这里集群有6台服务器:bigdata1,bigdata2,bigdata3,bigdata4,bigdata5,bigdata6
这里是3台主机,分别对应
2、JDK环境正确安装
3、集群中每台机器关闭防火墙,保证通信畅通
4、配置集群间ssh免密登录
5、集群ntp服务开启,保证时间同步(这一步非常重要,否则hbase启动会失败)
6、zookeeper正确安装
7、Hadoop HDFS服务开启
这里预定zookeeper的地址为:bigdata2,bigdata3,bigdata4,bigdata5,bigdata6 5个zookeeper节点
hadoop namenode为bigdata1(主),bigdata2(备用),其余4个为datanode
hbase Master为bigdata1,其余为存储节点
基于以上配置结合集群高可用配置,构成一个性能比较好的集群配置方式
前面6步都配置好的基础上,首先配置Hadoop集群,在bigdata1上做配置操作
首先解压hadoop,并安装至指定目录:
tar -xvzf hadoop-2.6..tar.gz
mkdir /bigdata/hadoop
mv hadoop-2.6. /bigdata/hadoop
cd /bigdata/hadoop/hadoop-2.6.
就是简单的释放,然后为了方便可以将HADOOP_HOME添加至环境变量
配置hadoop需要编辑以下几个配置文件:
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves
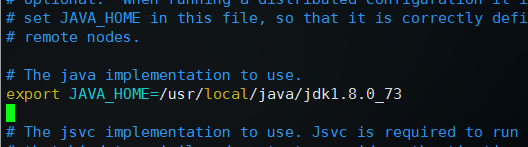
1、编辑hadoop-env.sh
修改export JAVA_HOME=${JAVA_HOME}为自己的实际安装位置
这里是export JAVA_HOME=/usr/local/java/jdk1.8.0_73
2、编辑core-site.xml,在configuration标签中间添加如下代码,
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopha</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata2:2181,bigdata3:2181,bigdata4:2181,bigdata5:2181,bigdata6:2181</value>
</property>
3、编辑hdfs-site.xml ,添加如下代码:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<!--这里和core-site中配置保持一致-->
<value>hadoopha</value>
</property> <property>
<name>dfs.ha.namenodes.hadoopha</name>
<value>bigdata1,bigdata2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoopha.bigdata1</name>
<value>bigdata1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopha.bigdata1</name>
<value>bigdata1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoopha.bigdata2</name>
<value>bigdata2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopha.bigdata2</name>
<value>bigdata2:50070</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:///bigdata/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///bigdata/hadoop/hdfs/data</value>
</property>
<!-- 这个地方是为Hbase的专用配置,最小为4096,表示同时处理文件的上限,不配置会报错 -->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property> <!--提供journal的服务器列表,一般为奇数个,这里为3个-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata3:8485;bigdata4:8485;bigdata5:8485/hadoopha</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <property>
<name>dfs.client.failover.proxy.provider.hadoopha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/hdfs/journal</value>
</property> <property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>5000</value>
</property> <!--配置ssh密钥存放位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
其中配置的注释说明要注意一下
4、编辑mapred-site.xml,这个不用配置
5、编辑yarn-site.xml,这个也不用配置
6、编辑slaves,添加datanode节点
bigdata3
bigdata4
bigdata5
bigdata6
这些都保存完毕,将/bigdata/下的hadoop目录整体发送至集群中其他主机,其他主机应该事先建立好bigdata目录
scp -r /bigdata/hadoop bigdata2:/bigdata
scp -r /bigdata/hadoop bigdata3:/bigdata
scp -r /bigdata/hadoop bigdata4:/bigdata
scp -r /bigdata/hadoop bigdata5:/bigdata
scp -r /bigdata/hadoop bigdata6:/bigdata
然后在配置jouralnode的服务器上启动jouralnode服务,这里是bigdata3,4,5
sbin/hadoop-daemon.sh start journalnode
然后在bigdata1上格式化zookeeper节点:
bin/hdfs zkfc -formatZK
在其中一台namenode上格式化文件系统并启动namenode,这里是bigdata1:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
在另外一台namenode,bigdata2上同步元数据:
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
然后启动hdfs服务:
sbin/start-dfs.sh
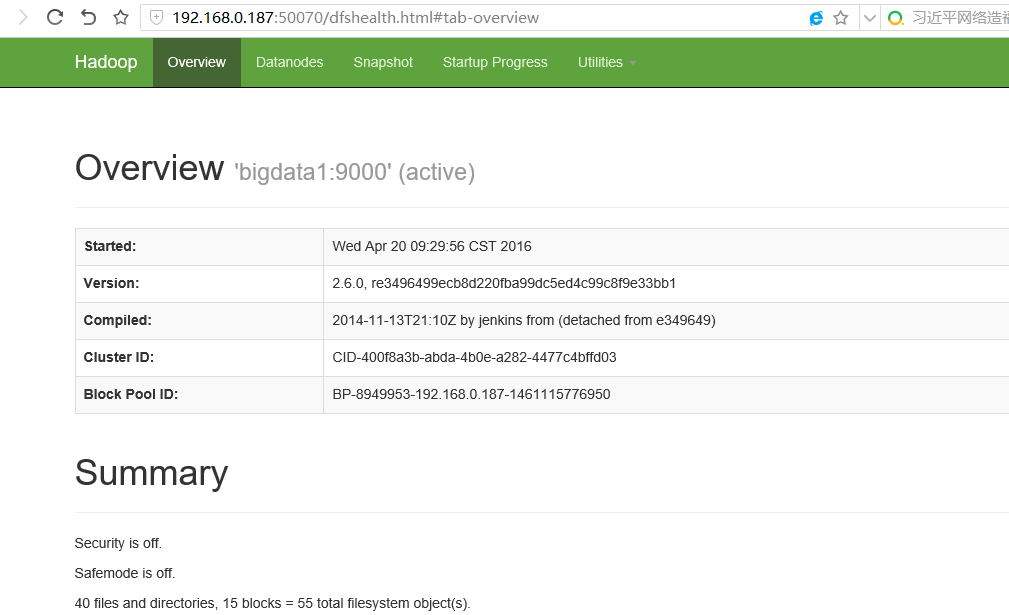
启动完成之后,执行 jps 命令,在主节点可以看到NameNode和DFSZKFailoverController进程;其他节点可以看到DataNode进程
现在通过浏览器可以打开相应的管理界面,以bigdata1的IP访问:
http://192.168.0.187:50070
到这里hadoop hdfs就部署完成了,然后开始部署HBase,这里使用的版本为:hbase-0.98.18-hadoop2-bin.tar.gz
和释放hadoop包一样将hbase释放到对应的目录并进入,这里是:/bigdata/hbase/hbase-0.98.18-hadoop2
首先编辑配置文件: vim conf/hbase-env.sh
去掉JAVA_HOME前面的注释,改为自己实际的JDK安装路径,和配置hadoop类似

然后,去掉export HBASE_MANAGES_ZK=true前面的注释并改为export HBASE_MANAGES_ZK=false,配置不让HBase管理Zookeeper
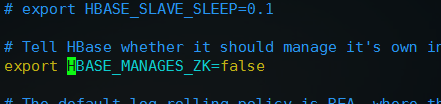
配置完这两项之后,保存退出
编辑文件 vim conf/hbase-site.xml 在configuration标签之间加入如下配置:
<!-- 指定HBase在HDFS上面创建的目录名hbase -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoopha/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>60000</value>
</property>
<!-- 开启集群运行方式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/bigdata/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata2,bigdata3,bigdata4,bigdata5,bigdata6</value>
</property>
分别将hadoop配置下的core-site.xml和hdfs-site.xml复制或者做软链接到hbase配置目录下:
cp /bigdata/hadoop/hadoop-2.6./etc/hadoop/core-site.xml conf/
cp /bigdata/hadoop/hadoop-2.6./etc/hadoop/hdfs-site.xml conf/
执行 vim conf/regionservers 编辑运行regionserver存储服务的Hbase节点,就相当于hadoop slaves中的DataNode节点
这里是bigdata2~bigdata5
保存之后,配置完毕,将hbase发送至其他数据节点:
scp -r /bigdata/hbase/ bigdata2:/bigdata/
scp -r /bigdata/hbase/ bigdata3:/bigdata/
scp -r /bigdata/hbase/ bigdata4:/bigdata/
scp -r /bigdata/hbase/ bigdata5:/bigdata/
scp -r /bigdata/hbase/ bigdata6:/bigdata/
然后在bigdata1启动Hbase Master
bin/hbase-daemon.sh start master
启动成功,在bigdata1会增加进程:HMaster
然后在bigdata2启动regionserver进程,其余4台集群会跟随启动
bin/hbase-daemons.sh start regionserver
这里注意跟随启动时,bigdata2到所有机器ssh确保直接进入,如果配置好的免密也最好提前都进一遍,避免需要输入yes而导致错误
同时集群的时间一定同步,否则hbase会启动失败出现NoNode Error的异常
在bigdata2到bigdata6会增加进程:HRegionServer
到这里HBase就部署完毕,并且包含zookeeper集群高可用配置
执行命令: /bigdata/hadoop/hadoop-2.6./bin/hdfs dfs -ls / 可以查看hbase是否在HDFS文件系统创建成功

看到/hbase节点表示创建成功
然后执行: bin/hbase shell 可以进入Hbase管理界面
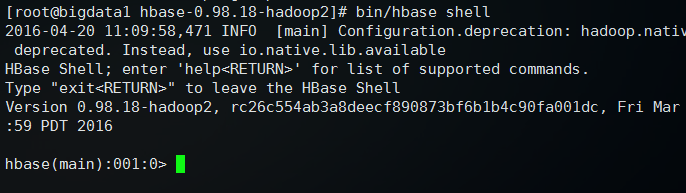
输入 status 查看状态

返回状态,表示HBase可以正常使用
输入 quit 可以退出管理,回到命令行
访问浏览器http://ip:60010可以打开Hbase管理界面
HBase集成Zookeeper集群部署的更多相关文章
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- Centos6下zookeeper集群部署记录
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目的 最终一致性:client不论 ...
- Gitlab CI 集成 Kubernetes 集群部署 Spring Boot 项目
在上一篇博客中,我们成功将 Gitlab CI 部署到了 Docker 中去,成功创建了 Gitlab CI Pipline 来执行 CI/CD 任务.那么这篇文章我们更进一步,将它集成到 K8s 集 ...
- 分布式协调服务之Zookeeper集群部署
一.分布式系统概念 在聊Zookeeper之前,我们先来聊聊什么是分布式系统:所谓分布式系统就是一个系统的软件或硬件组件分布在网络中的不同计算机之上,彼此间通过消息传递进行通信和协作的系统:简单讲就是 ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- Zookeeper集群部署
一. 部署前的准备工作 保证各个主机之间能够正常通信,最好是在同一网段. 修改host文件,加入IP和主机名的映射.方法为修改/etc/hosts和etc/hostname文件,不同的Linux发行版 ...
- docker环境下solrcloud+zookeeper集群部署教程
前言:两个月前的16年11月份完成的配置,使用的solr6.1和zookeeper3.4,刚刚写成blog,目前版本可能有小版本的变化. 本例完成结果为:在docker环境下部署solrcloud集群 ...
- Zookeeper集群部署与配置(三)
在上一篇博客中我们讲解了<Zookeeper的单机配置>,此篇博客将继续介绍Zookeeper的集群部署与配置. 环境 集群配置的环境与单机配置的环境相同,唯一不同的就是集群是在多台服务器 ...
随机推荐
- .NET逻辑分层架构总结
一.基础知识准备: 1.层的原则: (1)每一层以接口方式供上层调用. (2)上层只能调用下层. (3)依赖分为松散交互和严格交互两种. 2.业务逻辑分类: (1)应用逻辑. (2)领域逻辑. 3.采 ...
- OFFICE文档(DOC,XLS,PPT)打开报错的解决办法!
一般情况下,打开OFFICE文档报错都是因为模板文件出错!! 至于为什么会出错这个问题不好说,可能是不正确关闭文档等等,重装OFFICE也不一定能解决问题! 出现这种情况一般是所有的Word文档或者E ...
- 黄学长模拟day1 球的序列
N个编号为1-n的球,每个球都有唯一的编号.这些球被排成两种序列,分别为A.B序列,现在需要重新寻找一个球的序列l,对于这个子序列l中任意的两个球,要求j,k(j<k),都要求满足lj在A中位置 ...
- Cotex-M3内核STM32F10XX系列时钟及其配置方法
一.背景 最近做个项目,需要使用STM32,还是以前一样的观点,时钟就是MCU心脏,供血即时钟频率输出,想要弄明白一个MCU,时钟是一个非常好的切入点.言归正传,网上已经有太多大神详述过STM32的详 ...
- java依赖注入
接口的作用 1.在spide中创建一个私有接口 private Downloadable downlaodable 覆盖set get 方法 创建一个方法 Public Page down load ...
- 简单实现div遮罩
顾名思义,div遮罩就是将网页上的一部分用div遮盖起来,防止用户误点,因此div遮罩的一个用途就是将table设置为不可编辑. 作者通过查找资料,并进行简单的测试,最终完成了以下几段简单代码,来实现 ...
- Web服务精讲–搭个 Web 服务器(二)
导读 曾几何时,你所选择的 Python Web 框架会限制你所可选择的 Web 服务器,反之亦然.如果某个框架及服务器设计用来协同工作的,那么一切正常. 在第一部分中,我提出了一个问题:“如何在你刚 ...
- 160809209_李梦鑫_C语言程序设计实验3 循环结构程序设计
<C语言程序设计>实验报告 学 号 160809209 姓 名 李梦鑫 专业.班 计科16-2班 学 期 2016-2017 第1学期 指导教师 黄俊莲 吉吉老师 实验地点 C05 ...
- Caffe学习系列(8):solver及其配置
solver是caffe的核心. net: "examples/mnist/lenet_train_test.prototxt" test_iter: 100 test_inter ...
- H5canvas赛车游戏-基于lufylegend引擎
lufylegend引擎是canvas游戏中,比较简单的引擎之一,它不需要配置环境,类似引入jquery包的方式,引用对应js文件即可 lufylegend官方网站:http://www.lufyle ...