安装hadoop2.9.2 jdk1.8 centos7
安装JDK1.8
查看JDK1.8的安装
https://www.cnblogs.com/TJ21/p/13208514.html
安装hadoop
上传hadoop
下载hadoop 地址http://mirrors.hust.edu.cn/apache/hadoop/common/
放到mkdir /usr/local/src/hadoop目录下
解压 tar -zxvf hadoop-2.9.2.tar.gz
配置环境变量
vi /etc/profile 添加如下配置 export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.9.
export PATH=$HADOOP_HOME/bin:$PATH 重新刷新配置 source /etc/profile 查看版本 hadoop version
修改配置文件
vi core-site.xml
路径是 cd /usr/local/src/hadoop/hadoop-2.9.2/etc/hadoop
vi core-site.xml 添加如下配置
<property>
<name>fs.defaultFS</name>
<!-- 这里填的是你自己的ip,端口默认-->
<value>hdfs://192.168.0.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 这里填的是你自定义的hadoop工作的目录,端口默认-->
<value>/usr/local/src/hadoop/hadoop-2.9.2/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>Should native hadoop libraries, if present, be used.
</description>
</property>
vi hadoop-env.sh 配置成你自己的jdk安装路径
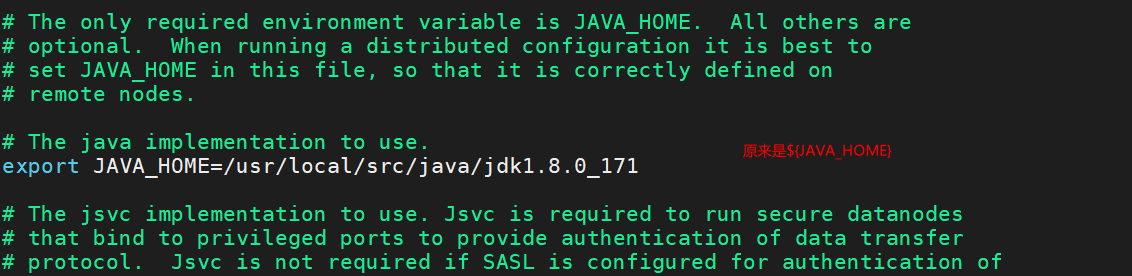
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.secondary.http.address</name> <!--这里是你自己的ip,端口默认-->
<value>192.168.0.130:50090</value>
</property>
vi mapred-site.xml
复制默认的cp mapred-site.xml.template ./mapred-site.xml 配置命名为mapred-site.xml
vi mapred-site.xml 添加如下配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 自己的ip端口默认 -->
<value>192.168.0.130</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置完成启动
配置好之后切换到sbin目录下
cd /usr/local/src/hadoop/hadoop-2.9.2/sbin/ 查看命令 ll
格式化hadoop文件格式,执行命令 hadoop namenode -format,成功之后启动
执行启动所有命令
./start-all.sh
没启动一个进程需要输入密码,可以通过配置ssh来解决,就不需要输入了,暂时配置
使用 jps 查看进程,能看到这些进程证明启动成功了,
也可以通过网页来查看 192.168.0.130:50070 此处的ip是自己的虚拟机IP
关闭防火墙的方法为:
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动
安装hadoop2.9.2 jdk1.8 centos7的更多相关文章
- CentOS7安装Hadoop2.7完整流程
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs.mapreduce等主从关系. 1.环境,3台CentOS7,64位,Hadoo ...
- CentOS7安装Hadoop2.7完整步骤
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs.mapreduce等主从关系. 1.环境,3台CentOS7,64位,Hadoo ...
- CentOS7安装Hadoop2.7流程
准备3个虚拟机节点 其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,那第二个和第三个虚拟机节点如何准备?可能你已经想明白了,你可以按第2步的方法,再分别安装两遍lin ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Ubuntu14.04下安装Hadoop2.5.1 (单机模式)
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-standalone-mode.html,转载请注明源地址. 欢迎关注我的个人博客:www.wuyudo ...
- 安装hadoop2.7.3
hadoop3与hadoop2.x的变化很大,hadoop3很多东西现在做起来太麻烦了,这里先安装hadoop2.7.3 此贴学习地址http://www.yiibai.com/t/mapreduce ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 编译安装hadoop2.6.3
一.安装环境 1.1 JAVA 安装java1.7 下载jdk1.7: [root@node1~]# wget http://download.oracle.com/otn-pub/java/jd ...
- centos单机安装Hadoop2.6
一,安装环境 硬件:虚拟机 操作系统:Centos 6.4 64位 IP:10.51.121.10 主机名:datanode-4 安装用户:root 二,安装JDK 安装JDK1.6或者以上版本.这里 ...
随机推荐
- 初窥Ansible playbook
Ansible是一个系列文章,我会尽量以通俗易懂.诙谐幽默的总结方式给大家呈现这些枯燥的知识点,让学习变的有趣一些. Ansible系列博文直达链接:Ansible入门系列 前言 在上一篇文章中说到A ...
- Html超链接和表单
超链接 a href="链接地址" target="链接打开方式" title="当鼠标放在连接上显示的文字"></a>链 ...
- webpack+vue2.0项目 (二)热加载,vue-router
目录创建好之后,命令行输入 npm run dev 因为在配置文件config/index.js里: dev: { env: require('./dev.env'), port: 8080, aut ...
- Linux kernel学习(序)
伟大的Linux kernel有几大重要模块: 1.文件系统(File System) 2.进程调度(Process Scheduler) 3.内存管理(Memory Management) 4.进程 ...
- Java实现 LeetCode 535 TinyURL 的加密与解密(位运算加密)
535. TinyURL 的加密与解密 TinyURL是一种URL简化服务, 比如:当你输入一个URL https://leetcode.com/problems/design-tinyurl 时,它 ...
- Java实现 蓝桥杯VIP 算法训练 求指数
问题描述 已知n和m,打印n1,n2,-,nm.要求用静态变量实现.nm表示n的m次方.已知n和m,打印n1,n2,-,nm.要求用静态变量实现.nm表示n的m次方.(每行显示5个数,每个数宽为12, ...
- Java实现 LeetCode 227 基本计算器 II(二)
227. 基本计算器 II 实现一个基本的计算器来计算一个简单的字符串表达式的值. 字符串表达式仅包含非负整数,+, - ,*,/ 四种运算符和空格 . 整数除法仅保留整数部分. 示例 1: 输入: ...
- Java实现 LeetCode 80 删除排序数组中的重复项 II(二)
80. 删除排序数组中的重复项 II 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O ...
- 分布式数据库PolonDB 云端发力未来数据处理需求
企业数字化转型的不断深入,传统 IT 架构和数据库早已无法适应诸如物联网.新金融.新零售.新制造等行业对于数据高吞吐.灵活扩展等需求,企业对数据库有了更高的要求. 青云QingCloud 本次推出的 ...
- 【百度前端技术学院 Day5/6】CSS盒模型及Float简单布局
1. 盒模型 1.1 内容区 content 默认情况下,width和height只包括内容区域的宽和高,不包括border.padding.margin使用box-sizing可以使其包含conte ...